






Meta 新的开源模型 ImageBind 将多个数据流连接在一起,适用于文本、视频和音频等 6 种模态。
在人类的感官中,一张图片可以将很多体验融合到一起,比如一张海滩图片可以让我们想起海浪的声音、沙子的质地、拂面而来的微风,甚至可以激发创作一首诗的灵感。图像的这种「绑定」(binding)属性通过与自身相关的任何感官体验对齐,为学习视觉特征提供了大量监督来源。
理想情况下,对于单个联合嵌入空间,视觉特征应该通过对齐所有感官来学习。然而这需要通过同一组图像来获取所有感官类型和组合的配对数据,显然不可行。
最近,很多方法学习与文本、音频等对齐的图像特征。这些方法使用单对模态或者最多几种视觉模态。最终嵌入仅限于用于训练的模态对。因此,视频 - 音频嵌入无法直接用于图像 - 文本任务,反之亦然。学习真正的联合嵌入面临的一个主要障碍是缺乏所有模态融合在一起的大量多模态数据。
今日,Meta AI 提出了 ImageBind,它通过利用多种类型的图像配对数据来学习单个共享表示空间。该研究不需要所有模态相互同时出现的数据集,相反利用到了图像的绑定属性,只要将每个模态的嵌入与图像嵌入对齐,就会实现所有模态的迅速对齐。Meta AI 还公布了相应代码。
论文名称:IMAGEBIND: One Embedding Space To Bind Them All (CVPR 2023)
项目主页: http://imagebind.metademolab.com/
- 论文地址:https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
- GitHub 地址:https://github.com/facebookresearch/ImageBind
具体而言,ImageBind 利用网络规模(图像、文本)匹配数据,并将其与自然存在的配对数据(视频、音频、图像、深度)相结合,以学习单个联合嵌入空间。这样做使得 ImageBind 隐式地将文本嵌入与其他模态(如音频、深度等)对齐,从而在没有显式语义或文本配对的情况下,能在这些模态上实现零样本识别功能。
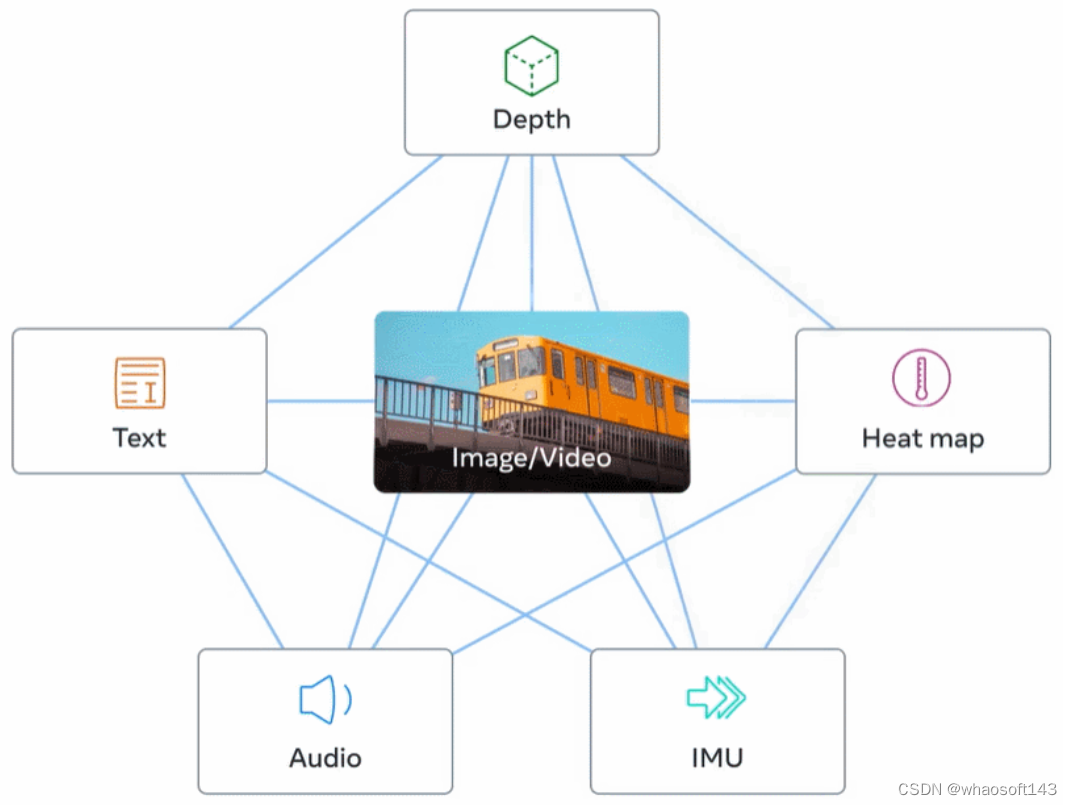
下图 2 为 ImageBind 的整体概览。

与此同时,研究者表示 ImageBind 可以使用大规模视觉语言模型(如 CLIP)进行初始化,从而利用这些模型的丰富图像和文本表示。因此,ImageBind 只需要很少的训练就可以应用于各种不同的模态和任务。
ImageBind 是 Meta 致力于创建多模态 AI 系统的一部分,从而实现从所有相关类型数据中学习。随着模态数量的增加,ImageBind 为研究人员打开了尝试开发全新整体性系统的闸门,例如结合 3D 和 IMU 传感器来设计或体验身临其境的虚拟世界。此外它还可以提供一种探索记忆的丰富方式,即组合使用文本、视频和图像来搜索图像、视频、音频文件或文本信息。
绑定内容和图像,学习单个嵌入空间
人类有能力通过很少的样本学习新概念,比如如阅读对动物的描述之后,就可以在实际生活中认出它们;通过一张不熟悉的汽车模型照片,就可以预测其引擎可能发出的声音。这在一定程度上是因为单张图像可以将整体感官体验「捆绑」在一起。然而在人工智能领域,虽然模态数量一直在增加,但多感官数据的缺乏会限制标准的需要配对数据的多模态学习。
理想情况下,一个有着不同种类数据的联合嵌入空间能让模型在学习视觉特征的同时学习其他的模态。此前,往往需要收集所有可能的配对数据组合,才能让所有模态学习联合嵌入空间。
ImageBind 规避了这个难题,它利用最近的大型视觉语言模型它将最近的大规模视觉语言模型的零样本能力扩展到新的模态,它们与图像的自然配对,如视频 - 音频和图像 - 深度数据,来学习一个联合嵌入空间。针对其他四种模式(音频、深度、热成像和 IMU 读数),研究者使用自然配对的自监督数据。
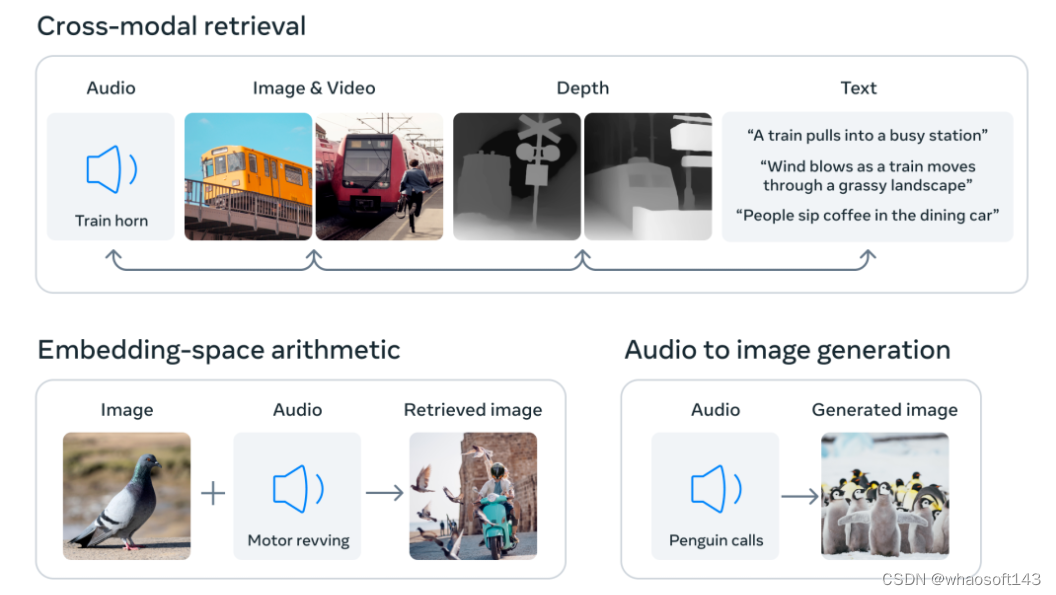
通过将六种模态的嵌入对齐到一个公共空间,ImageBind 可以跨模态检索未同时观察到的不同类型的内容,添加不同模态的嵌入以自然地对它们的语义进行组合,以及结合使用 Meta AI 的音频嵌入与预训练 DALLE-2 解码器(设计用于与 CLIP 文本嵌入)来实现音频到图像生成。
互联网上存在大量连同文本一起出现的图像,因此训练图像 - 文本模型已经得到了广泛的研究。ImageBind 利用了图像能与各种模态相连接的绑定属性,比如利用网络数据将文本与图像连接起来,或者利用在有 IMU 传感器的可穿戴相机中捕捉到的视频数据将运动与视频连接起来。
从大规模网络数据中学习到的视觉表征可以用作学习不同模态特征的目标。这使得 ImageBind 将图像与同时出现的任何模态对齐,自然地使这些模态彼此对齐。热图和深度图等与图像具有强相关性的模态更容易对齐。音频和 IMU(惯性测量单元)等非视觉的模态则具有较弱的相关性,比如婴儿哭声等特定声音可以搭配各种视觉背景。
ImageBind 表明,图像配对数据足以将这六种模态绑定在一起。该模型可以更全面地解释内容,使不同的模态可以相互「对话」,并在没有同时观察它们的情况下找到它们之间的联系。例如,ImageBind 可以在没有一起观察音频和文本的情况下将二者联系起来。这使得其他模型能够「理解」新的模态,而不需要任何资源密集型的训练。
ImageBind 强大的 scaling 表现使该模型能够替代或增强许多人工智能模型,使它们能够使用其他模态。例如虽然 Make-A-Scene 可以通过使用文本 prompt 生成图像,但 ImageBind 可以将其升级为使用音频生成图像,如笑声或雨声。
ImageBind 的卓越性能
Meta 的分析表明,ImageBind 的 scaling 行为随着图像编码器的强度而提高。换句话说,ImageBind 对齐模态的能力随着视觉模型的能力和大小而提升。这表明,更大的视觉模型对非视觉任务有利,如音频分类,而且训练这种模型的好处超出了计算机视觉任务的范畴。
在实验中,Meta 使用了 ImageBind 的音频和深度编码器,并将其与之前在 zero-shot 检索以及音频和深度分类任务中的工作进行了比较。
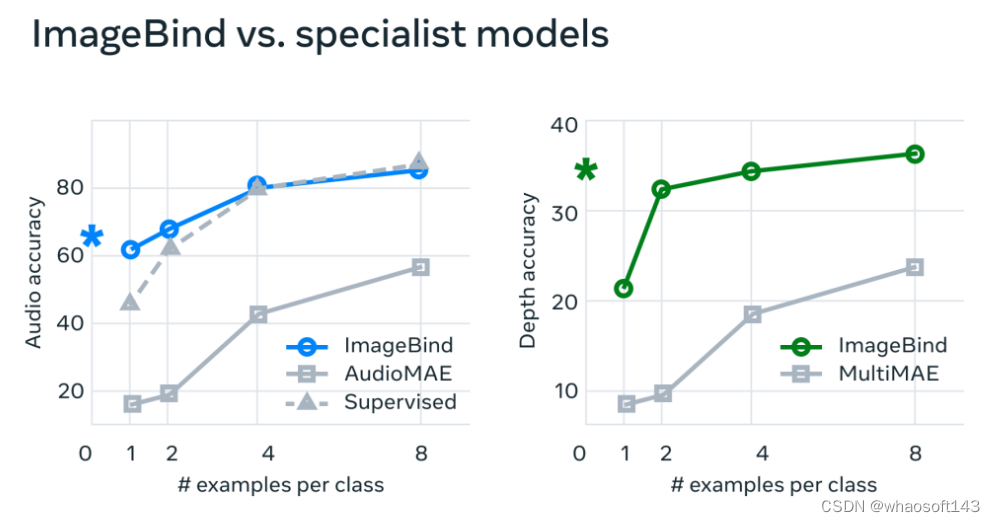
在基准测试上,ImageBind 在音频和深度方面优于专家模型
Meta 发现 ImageBind 可以用于少样本音频和深度分类任务,并且优于之前定制的方法。例如,ImageBind 明显优于 Meta 在 Audioset 上训练的自监督 AudioMAE 模型,以及在音频分类上微调的监督 AudioMAE 模型。
此外,ImageBind 还在跨模态的零样本识别任务上取得了新的 SOTA 性能,甚至优于经过训练以识别该模态概念的最新模型。
参考链接:https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Meta统一表征模型的设想ImageBind:图像配对数据绑定6种模态
首个能够同时绑定六种模式数据的人工智能模型,ImageBind 提出了一种通过利用多种模态 (text, audio, depth, IMU) 与 image 的配对数据来学习共享的表征空间的方法。它不需要所有模态彼此同时出现的数据集,而是只需要与 image/video 配对的数据即可
ImageBind 是一个学习一个联合特征嵌入 (Joint Embedding) 的方法,这个联合嵌入可以同时编码 images, text, audio, depth, thermal, 和 IMU 数据。而且,在训练这个联合嵌入的时候,不需要所有模态彼此同时出现的数据集,比如不需要配对的 image + text + audio + depth + IMU 数据。而是只需要与 image/video 配对的数据即可,比如,image + text,image + audio 这样的数据集。
这个性质可以为 ImageBind 带来一些开箱即用的功能,比如:跨模态检索,将模态与算术相结合,跨模态检测和生成等。
一张简单的图片,能让人回忆起很多经历:海滩的图片可以让人想起海浪的声音,沙子的纹理,想起阵阵海风,甚至是一首诗。这种图像和多种模态信息的 "绑定" 给人们提供了许多监督的来源来学习视觉的特征,其方法就是人们会将图像与自己其他的感官信息 "对齐"。理想的情况下,是不是有一种联合的嵌入空间,可以将所有的这些种类的模态信息对齐来学习视觉特征。但是,这就需要所有类型的模态的数据集组合,比如需要声音,文字,图像等等所有的信息,从现在研究的角度出发,比较困难。
最近,有很多工作试图学习与文本对齐的图像特征,音频特征等。比如 CLIP 就把图片和文本这两种模态做了对齐。但是这些工作所学习到的嵌入 (Embedding) 有两个局限性:
- 只使用一对嵌入 (比如视觉和文本),或者较少的几对嵌入。
- 学习到的嵌入仅限于用于训练的模态对。比如,视频音频嵌入不能直接用于图像文本任务。
ImageBind 提出了一种通过利用多种模态 (text, audio, depth, IMU) 与 image 的配对数据来学习共享的表征空间的方法。它不需要所有模态彼此同时出现的数据集,比如不需要配对的 image + text + audio + depth + IMU 数据。而是只需要与 image/video 配对的数据即可,比如,image + text,image + audio 这样的数据集。这就大大减小了对数据集质量的要求。
因此,本文方法取名 ImageBind ,意思是通过 image/video 这种模态,来 "绑定" 其他多种模态的数据。这允许 ImageBind 将文本嵌入隐式对齐到其他模态,例如音频、深度等,从而在该模态上实现零样本识别能力,而无需显式语义或文本配对。而且,作者表明 ImageBind 可以使用 CLIP 等大规模视觉语言模型进行初始化,从而利用这些模型丰富的图像和文本表示。因此,ImageBind 可以在只进行少量训练的情况下轻松应用于多种模态任务。
ImageBind 使用的数据集不仅有图像-文本对,还包括了4种新的模态:audio, depth, thermal, 和 Inertial Measurement Unit (IMU),并在每种模态的任务上面都表现出了强大的 Emergent Zero-Shot 分类和检索性能。
ImageBind 的联合嵌入表征可以用于各种组合任务,如下图1所示,包括1) 跨模态检索:快速对齐音频,深度图和文本信息。2) 给一个嵌入增加来自不同模态的另一个嵌入可以自然地增加语音信息。3) 音频到图像的生成,通过预训练的 DALLE-2 解码器,旨在与 CLIP 的文本嵌入一起工作

具体方法
本文的目标是通过图像或者视频这个媒介,将所有的模态绑定在一起,来学习所有模态的联合嵌入空间 (joint embedding space)。作者把除了 image, video 之外的每个模态都和 image, video 模态对齐,比如 text 模态,作者就通过 web data 和 image 对齐。再比如 IMU 模态,通过 egocentric camera 捕获得到的结果和 video 对齐。如下图2所示,这个联合嵌入空间 (joint embedding space) 的优点是:具有强大的 Zero-Shot 能力。比如训练集里面并没有任何配对的 IMU-text 数据,但是联合嵌入空间使得 ImageBind 模型可以关联这两种模态。不同模态的数据在不同的数据来源中自然出现,比如网络数据中有很多 images+text,video+audio 数据。image 里面自带 depth 或 thermal 信息,egocentric camera 得到的 video 中包含 IMU 信息。ImageBind 方法把所有模态与 image, video 相关联。

图2:ImageBind 方法概述。不同模态的数据在不同的数据来源中自然出现,比如网络数据中有很多 images+text,video+audio 数据。image 里面自带 depth 或 thermal 信息,egocentric camera 得到的 video 中包含 IMU 信息。ImageBind 方法把所有模态与 image, video 相关联
在介绍 ImageBind 的具体方法之前需要先提一下两个常用的概念。
第1是对齐特定的模态对,比如 CLIP 里面就将 image 和 text 这2种模态对齐。在对比学习里面,我们可以使用 (image, text), (audio, text) , (image, depth) , (video, audio) 等等类型的数据对。然而,在每种情况下,我们在评估模型的时候也只能在相应类型的数据对上做评估。比如在 (video, audio) 数据上训练得到的模型无法直接适用于 text 的任务,同理在 (image, text) 数据上训练得到的模型无法直接适用于 audio 的任务。
第2是使用 text prompt 进行 Zero-Shot 的图像分类。CLIP 构建了一个描述数据集中类的文本描述列表。输入图像根据其与嵌入空间中的文本描述的相似性进行分类。但是 CLIP 的训练需要成对的数据,比如如果希望 CLIP 支持 (audio, text) 的 Zero-Shot 分类就需要有对应的大量 (audio, text) 数据对。但是,ImageBind 无此要求。

实现
ImageBind 在概念上很简单,而且可以通过多种方式实现。使用 ViT 作为 image 的特征提取器,使用 Patch Size 为 16 和 stride 为 10 的 ViT。
对于 video:从2秒采样的2帧视频剪辑。
对于 audio:使用 128 mel-spectrogram bins 将 16kHz 采样的 2 秒音频转换为频谱图。
对于 thermal image 和 depth image:按照 channel 为1的 image 来处理。
对于 IMU:将深度转换为视差图,以实现尺度不变性。提取由 X、Y 和 Z 轴上的加速度计和陀螺仪测量组成的IMU信号。使用 5 秒的剪辑,从而产生 2K 时间步长 IMU 读数,这些读数是使用核大小为 8 的 1D 卷积投影的。
作者对 images, text, audio, thermal images, depth images, 和 IMU 使用单独的编码器,在每个编码器上添加特定于模态的线性投影头来获得固定大小的 dd 维嵌入,该嵌入被归一化并用于式1的 InfoNCE 损失函数。除了易于学习之外,这种设置还允许使用预训练的 CLIP 或 OpenCLIP 的图像和文本编码器。
实验设置
ImageBind 所使用的数据集中包含自然与图片配对的各种模态的数据,比如:
- Audioset dataset 中包含了自然配对的 (video, audio) 数据。
- SUN RGB-D dataset 中包含了自然配对的 (image, depth) 数据。
- LLVIP dataset 中包含了自然配对的 (image, thermal) 数据。
- Ego4D dataset 中包含了自然配对的 (video, IMU) 数据。
由于 SUN RGB-D 和 LLVIP 相对较小,作者将它们复制 50 倍进行训练。
模型方面,作者使用了 CLIP 的预训练权重,视觉编码器是 ViT-H,有 630M 参数。文本编码器来自 OpenCLIP,有 302M 参数。audio 的编码器使用 ViT-B,thermal 和 depth image 的编码器使用 ViT-S。图像和文本编码器在 ImageBind 训练期间保持冻结,并更新 audio,thermal,depth 和 IMU 的编码器。
ImageBind 的下游任务数据集如下图3所示。
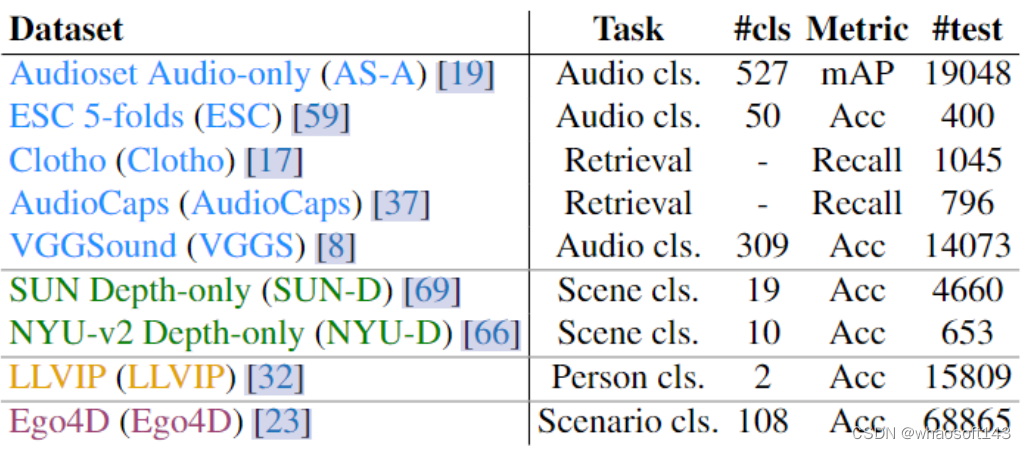
图3:ImageBind 的下游任务数据集
关于 Emergent Zero-Shot Classification
Emergent Zero-Shot Classification 是本文定义的一个词。CLIP、AudioCLIP 等方法使用数据对 (image, text) 和 (audio, text) 进行训练,并证明可以在 (image, text) 和 (audio, text) 数据对上进行 Zero-Shot Classification。
但反观 ImageBind,只需要对 (image, text) 和 (image, audio) 进行训练,就可以使用 text prompt 对 audio 进行 Zero-Shot Classification,对应下图4的蓝色区域的结果。但是这种能力并不是直接训练得到的,因此作者称之为紧急零样本分类性能 (Emergent Zero-Shot Classification),以与专门的 Zero-Shot Classification 区分开来。
Emergent Zero-Shot Classification 实验结果
如下图4所示是 Emergent Zero-Shot Classification 实验结果。使用 text prompts 的结果使用蓝色底注释。
比如:63.4 这个数据,就是 ImageBind 模型使用 text prompt,在 LLVIP 数据集上做 Zero-Shot 分类的结果,前提是模型在训练时并没有任何的 (text, thermal) 数据对,而是只有 (image, thermal) 数据对。模型是靠 (image, thermal) 和 (text, thermal) 的联合训练学习到的 (text, thermal) 的 Zero-Shot 分类的性能。
Imagebind 将图像与文本、深度、音频、热和 IMU 等模态对齐。生成的嵌入空间可以将文本嵌入与非图像模态相关联,并获得强大的紧急零样本分类性能。即使在音频和视频模式(例如音频和 IMU)上也表现出强大的性能。
Imagebind 是第一个搞 Emergent Zero-Shot Classification 的工作,所以没有任何对比的 Baseline 在。而从图4中我们也可以发现,Imagebind 的 Emergent Zero-Shot Classification 性能还是相当不错的。在每个基准测试中,Imagebind 都获得了强大的增益,甚至优于针对特定模态和任务训练的监督专家模型。
这些结果表明,Imagebind 可以通过 (image, x) 和 (image, text) 数据对的对齐训练,来隐式地对齐 (x, text) 模态的数据,这个能力很神奇。
图4中的 Absolute state-of-the-art (SOTA) 代表每个数据集真正的 SOTA 性能,但是这个点数通常是有监督信号。作者报告了除 MSR-VTT (Recall@1) 和音频 (mAP) 之外的所有数据集的 Top-1 分类精度。

图4:Emergent Zero-Shot Classification 实验结果。使用 text prompts 的结果使用蓝色底注释。Imagebind 将图像与文本、深度、音频、热和 IMU 等模态对齐。生成的嵌入空间可以将文本嵌入与非图像模态相关联,并获得强大的紧急零样本分类性能
Zero-Shot 检索和分类任务实验结果
Zero-shot text to audio 检索和分类
之前的工作 AudioCLIP 这个方法使用了 (audio, text) 监督信号,AVFIC 这个工作也使用了 (audio, text) 监督信号,作者在图5中比较了它们的性能。ImageBind 在音频文本检索基准上显著优于先前的工作。在 Clotho 数据集上,尽管在训练期间没有使用任何文本配对的音频,但是 ImageBind 的性能是 AVFIC 的两倍。与监督训练得到的 AudioCLIP 模型相比,ImageBind 在 ESC 数据集上实现了相当的音频分类性能。ImageBind 在所有3个基准上的强大性能,验证了它能够使用 image 作为桥梁来对齐 audio 和 text 模态。
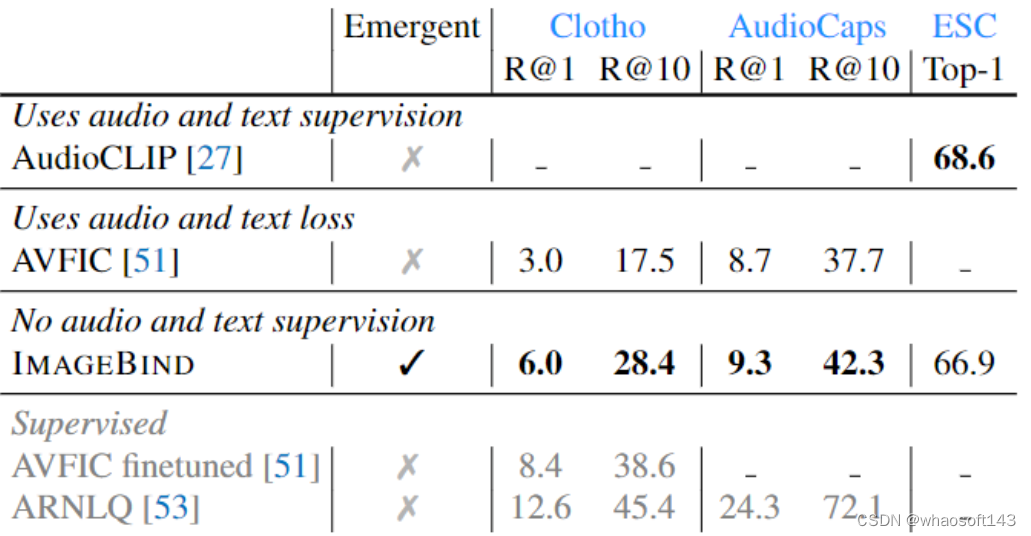
图5:Zero-shot text to audio 检索和分类实验结果
Text to audio and video 检索
作者使用 MSR-VTT 1k-A benchmark 来评估 Text to audio and video 检索性能。
ImagBind 在仅使用 audio 的情况下,text-based 的检索性能 (Emergent Zero-Shot Retrieval) 性能不错,与 MIL-NCE 等先前工作的视频检索性能相比,还是实现了不错的紧急检索性能。
ImagBind 结合 audio 和 video 模态的情况下,可以进一步获得强大的性能,表明 ImageBind 的特征在检索模型上的实用性。
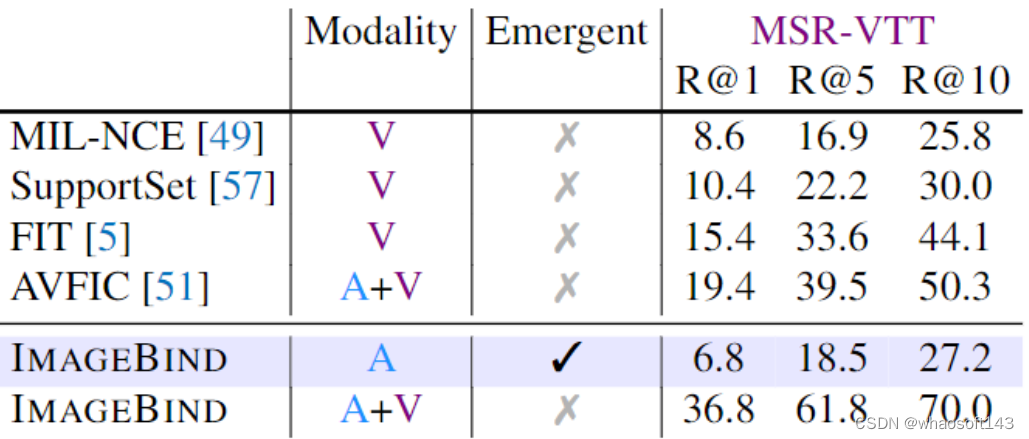
图6:基于 text 的 Zero-shot 检索实验结果
Few-shot 分类性能
作者接下来通过对 Few-shot 分类性能进行评估来评估 ImageBind 的标签效率,作者使用来自 ImageBind 的audio 和 depth 的 Encoder,并分别评测其 audio 和 depth 分类的性能,实验结果如图7所示。对于 ≥1-shot 的结果,就训练一个 Linear Classifier。
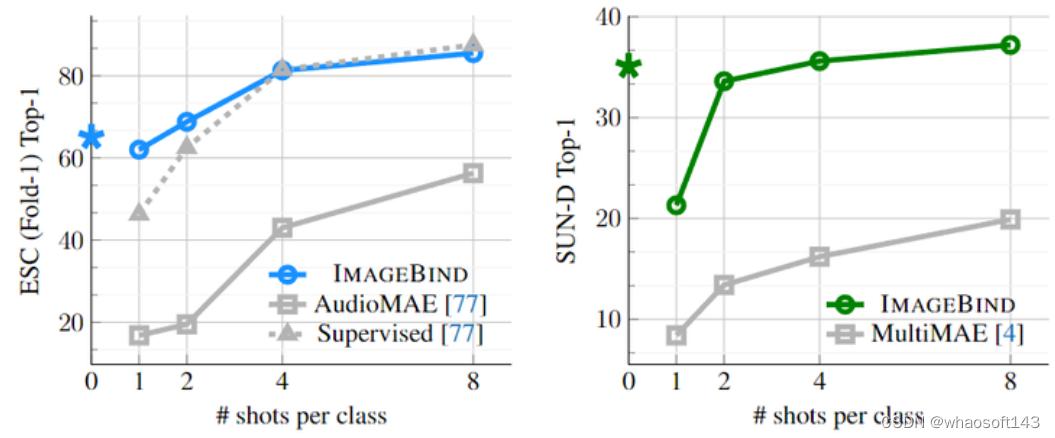
图7:Few-Shot 分类性能
Audio 分类任务作者比较的模型是:
- Self-supervised AudioMAE 模型。
- 用于音频分类任务的微调 supervised AudioMAE 模型。
以上两个 Baseline 都使用 ViT-B 模型作为 audio encoder,和 ImageBind 保持一致。
ImageBind 在所有设置中都显着优于 AudioMAE 模型,在 ≤4-shot 分类上以 top-1 准确度提高了约 40%。ImageBind 在 ≥1-shot 分类上也匹配或优于监督模型。ImageBind 的紧急零样本性能超过了有监督的 ≤2-shot 性能。
Depth 分类任务作者比较的模型是:MultiMAE 模型,即 ViT-B/16 模型。在所有 Few-Shot 的设置中,ImageBind 的性能明显优于 MultiMAE。这些结果表明使用图像对齐训练的 ImageBind 在 audio 和 depth 特征中具有很强的泛化能力。
ImageBind 分析
1) 多模态嵌入空间的算术
作者研究了 ImageBind 的嵌入是否可以用于跨模态组合信息。如下图8所示,通过把 image 和 audio 的 Embedding 加在一起,得到的联合嵌入,使得我们可以组合两个 Embedding。比如:桌子上水果的图像+啁啾鸟的声音,并检索包含这些概念的图像,就得到了有鸟和水果的树的图片。
通过这个特点,我们可以在没有重新训练的情况下,借助使用其他模态的 ImageBind 模型来升级已有的基于 CLIP 的视觉模型。

图8:通过把 image 和 audio 的 Embedding 加在一起得到联合嵌入,组合已有的嵌入
2) 将基于文本的检测器升级为基于音频的检测器
预训练的基于文本的检测模型 Detic,简单地将其基于 CLIP 的 text Embedding 替换为 ImageBind 的 audio 嵌入。在没有训练的情况下,就得到了一个基于 audio 的检测器,可以根据音频提示检测和分割对象。如下图9所示,输入狗叫的声音,可以定位出狗的位置。输入敲击键盘的声音,可以对键盘进行分割。

图9:基于音频的检测器:输入狗叫的声音,检测出狗的位置。输入敲击键盘的声音,分割出键盘的 mask
3) 将基于文本的扩散模型升级为基于音频的扩散模型
作者使用预训练的 DALLE-2 扩散模型并将其 Prompt Embedding 替换为 ImageBind 的 audio 嵌入。这样就得到了一个基于 audio 的扩散模型。如图1所示,作者观察到可以利用扩散模型使用不同类型的声音生成合理的图像。















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









