






本文首次探索了数据集压缩中的匹配效率问题,提出了高效的数据集压缩匹配算法DREAM,能将现有主流数据集压缩算法无损加速至少八倍,为大规模数据集压缩提供了基础。
DREAM: Efficient Dataset Distillation by Representative Matching
论文链接:https://arxiv.org/abs/2302.14416
代码链接:https://github.com/lyq312318224/DREAM
一句话总结;TL DR:本文首次探索了数据集压缩中的匹配效率问题,提出了高效的数据集压缩匹配算法------DREAM,能将现有主流数据集压缩算法无损加速至少八倍,为大规模数据集压缩提供了基础。
数据集蒸馏旨在从原始的大规模数据集中合成具有较少信息丢失的小数据集,以减少存储和训练成本。目前最先进的方法主要是通过匹配合成图像和原始图像的梯度、嵌入分布或训练轨迹来约束样本合成过程。尽管有各种匹配目标,但目前选择原始图像的策略仍然局限于原始的随机采样。我们认为,随机采样忽略了所选样本分布的均匀性,这可能导致嘈杂或有偏差的匹配目标。此外,随机采样也难以约束样本的多样性。这些因素共同导致了蒸馏过程中的优化不稳定性并降低了训练效率。因此,我们提出了一种新的匹配策略,称为"Dataset distillation by REpresentAtive Matching(DREAM)",仅选择有代表性的原始图像进行匹配。DREAM方法可以轻松地嵌入到流行的数据集蒸馏框架中,并且在不降低性能的情况下将蒸馏迭代次数降低了8倍以上。在获得更多训练时间的情况下,DREAM进一步实现了显著的性能提升,达到了最先进的性能水平。
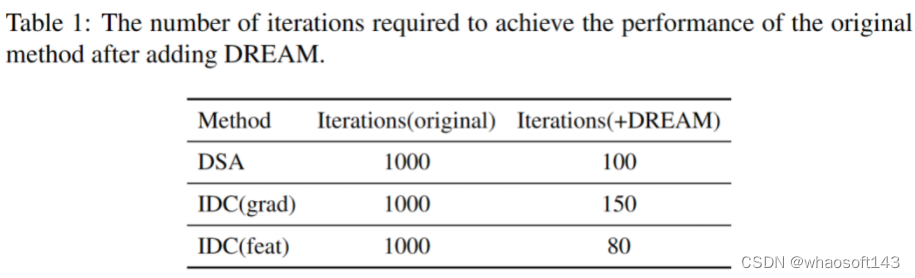
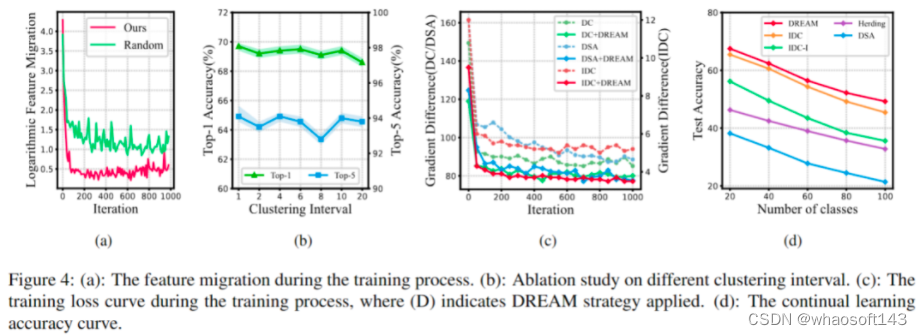
对训练效率的观察数据集蒸馏过程中,通过匹配特定目标从采样的原始图像中蒸馏知识,因此选择原始图像对训练效率有重要影响。现有方法通常通过随机采样来选择原始图像,我们以梯度匹配为例,仔细说明随机采样干扰了数据集蒸馏的高效训练。在类别的所有样本中,接近分布中心的样本预测准确性较高,反向梯度较小,而决策边界上的样本相反。对于梯度匹配,中心样本提供的监督效果较弱,而边界样本的梯度在优化方向上起主导作用,图2(b)中展示了仅使用中心样本或边界样本与合成图像匹配时的训练准确率曲线。此外,图2(c)中记录了随机采样不能保证获得均匀分布的小批量样本,导致梯度差异不平衡,监督不稳定。不均匀分布的小批量样本还导致样本多样性相对较差,使得小批量样本无法充分代表原始数据。这些因素导致了优化不稳定并降低了训练效率。
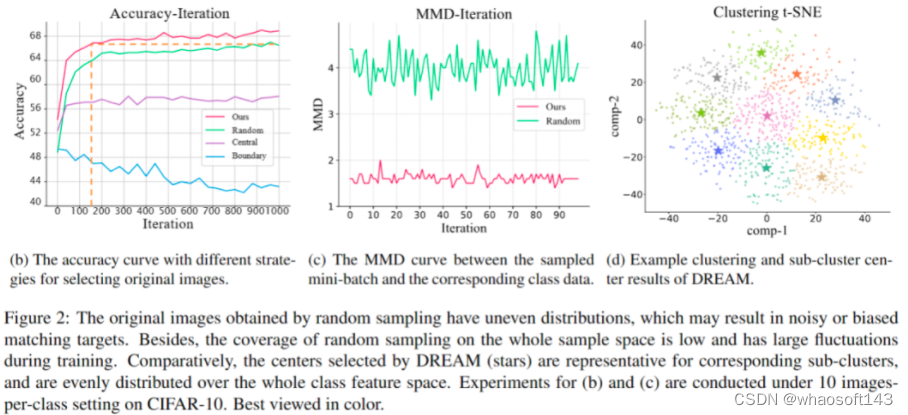
代表性匹配为了实现稳定且快速的优化,我们选择了具有代表性的原始图像进行梯度匹配,并采用了聚类过程来选择这些代表性图像。选择代表性图像遵循两个原则:首先,所选图像应均匀分布,以避免偏差的匹配目标;其次,在保持多样性的同时,所选样本应准确地反映整体类别样本分布。为了实现这一目标,我们使用K-Means算法在每个类别内进行聚类,生成N个子聚类,其中N是预定义的真实图像小批量大小的超参数。子聚类的中心点均匀覆盖整个类别的样本空间,同时提供足够的多样性,完全满足上述原则。在训练流程中,通过聚类选择的原始小批量样本和具有相同类别标签的合成图像通过随机模型进行前向传播,得到预测分数,并计算分类损失及其对应的梯度。然后,根据梯度差异更新合成图像。聚类过程每隔一定迭代次数进行一次,以降低额外的时间成本。同时,在训练开始时,每个类别的数据被聚类成与预定义的每类图像数相对应的子聚类,并选择每个子聚类的中心样本作为合成图像的初始化。这样的基于聚类的初始化能更好地反映数据分布,并加速训练过程的收敛。

实验结果
我们在多个常用的数据集上验证了提出的方法的有效性,包括CIFAR-10、CIFAR-100、SVHN、MNIST、FashionMNIST和TinyImageNet。我们提出的方法(DREAM)通过匹配真实样本的梯度来合成图像,而且为了保持样本多样性和均匀分布,我们使用了基于K-Means聚类的方法来选择代表性的原始图像。
实验结果表明,DREAM在多个数据集上都表现出优异的性能。与其他基于核心集和基于优化的方法相比,DREAM在训练效率和数据集性能方面都具有优势。
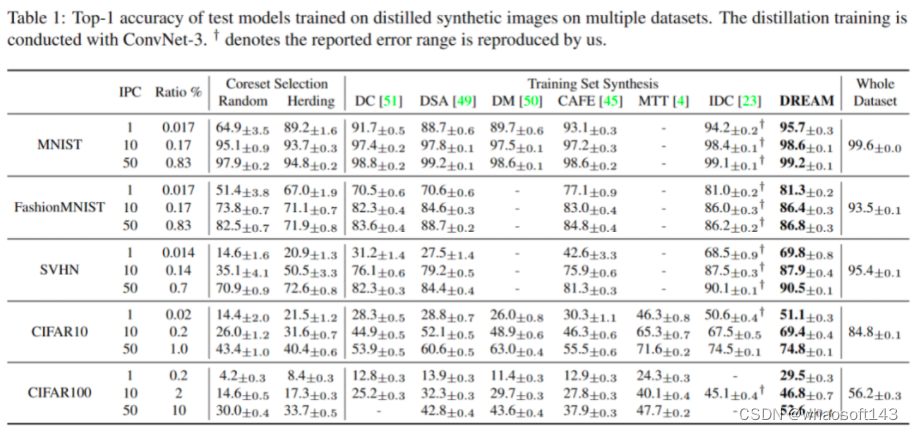
我们在IDC、DC和DSA等流行的数据集蒸馏框架中验证了DREAM的有效性,同时分析了DREAM中各组件的影响。此外,DREAM还展现了出色的跨架构泛化能力,在不同的架构上应用合成数据集时也表现出较好的性能。
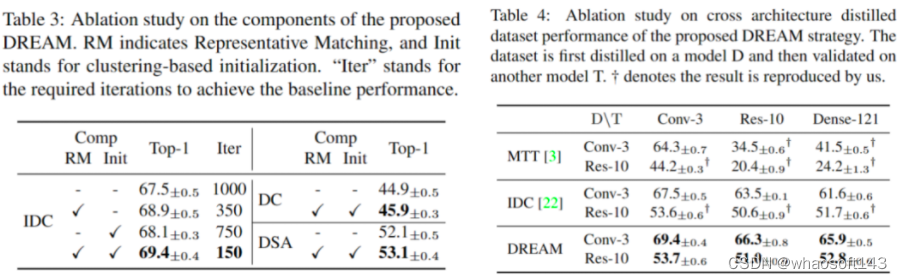
此外,我们还观察了训练过程中的特征迁移、聚类间隔和梯度变化曲线,并验证了DREAM在持续学习场景下的有效性。
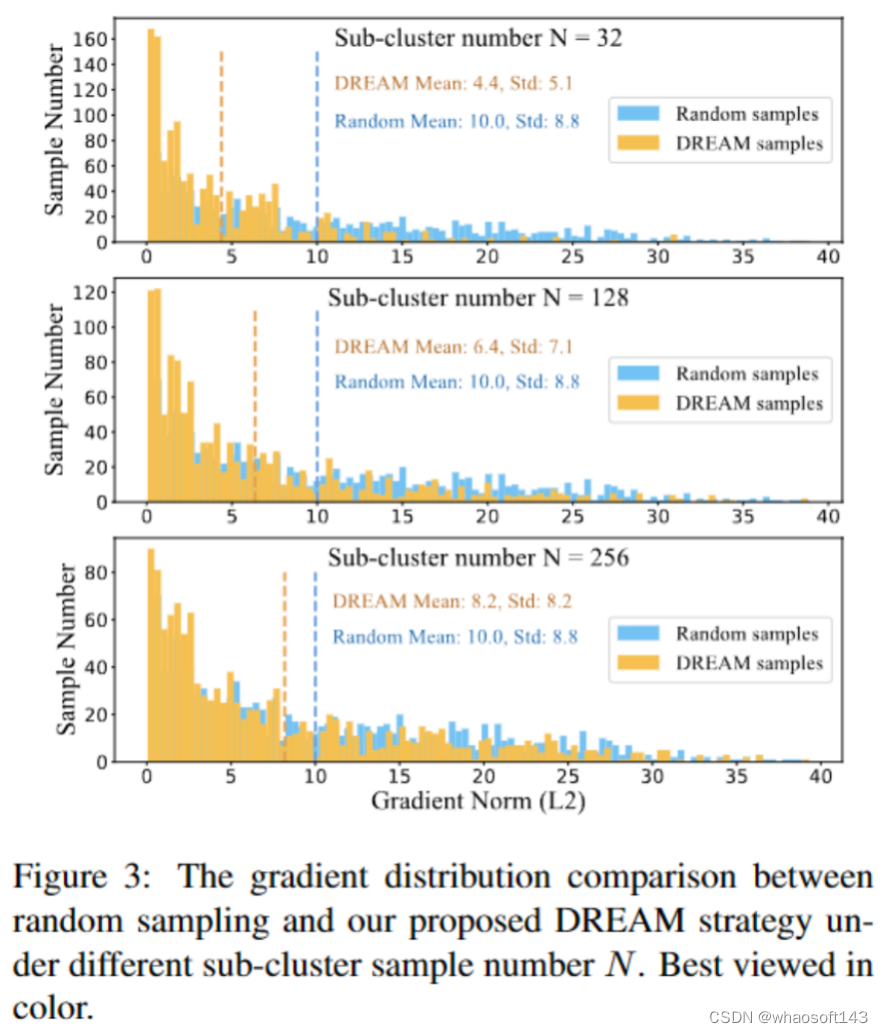
我们对不同的采样策略进行了分析。在小的子聚类数量N=32的情况下,子聚类中心更有可能分布在梯度较小的区域,这些样本在随机模型训练过程中逐渐无法提供有效的梯度监督,导致性能较差。较大的子聚类数量N=256产生的分布更接近于随机采样,会带来轻微的性能下降。每个子聚类的样本数n对结果影响较小。选择每个子聚类中的1个中心样本,总共128个子聚类,被证明是获得最佳梯度监督的组合,并被选择用于小批量组成。
结论与讨论
DREAM方法通过代表性匹配改进了数据集蒸馏的训练效率,在不影响性能的前提下减少了训练迭代次数8倍以上,提高了模型的稳定性和泛化能力,在多个数据集上达到了SOTA的效果,为进一步设计更复杂的匹配度量提供了可能。
虽然DREAM显著提高了基于匹配的数据集蒸馏方法的训练效率,但在处理大规模数据集(如ImageNet)时仍然面临计算负担较重的问题。未来的工作可以集中在设计更加资源友好的数据集蒸馏方法,以解决大规模数据集压缩的挑战。















 2171
2171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









