





首先要知道线性模型的基本形式:
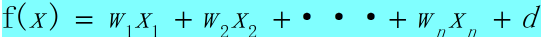
其中X1,X2,...,Xn代表各个属性,而X1,X2,...,Xn的系数W1,W2,...,Wn代表属性值,其用矢量可以表示为

线性回归
:
线性回归试图学得W1,W2,...,Wn和d的值,使f(x)尽可能接近真实值y,而线性回归中经常利用最小二乘法得到W1,W2,...,Wn和d的值。
利用最小二乘法求参数W1,W2,...,Wn,d:
我们使均方误差最小化来求参数,即先表示出来
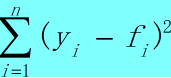
并使之最小化,即求
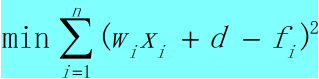
再分别对W1,W2,...,Wn,d偏导数,并令偏导数等于零,得到n+1个方程,可以求出W1,W2,...,Wn,d这n+1个变量的解。(其实这是在数学中比较常做的一个求极值的问题)
注意:在实际应用中,我们可能没有足够的样本去学习参数,这样就使得到的方程数少于变量的个数,由线性代数的知识可知,这种情况下我们可以得到多组最优解,至于选择那组解,可由学习算法的归纳偏好而定,常见的是引入正则化项。
有时候输出y是成非线性关系变化的,为了得到线性关系,可以令
 表示y。例如y随着x的变化呈指数型变化,则令
表示y。例如y随着x的变化呈指数型变化,则令
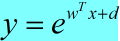 ,那么
,那么
表示y。例如y随着x的变化呈指数型变化,则令
,那么
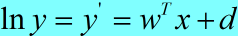 ,从而得到输出x和输入y的线性关系方程。这里g()=ln(),称
,从而得到输出x和输入y的线性关系方程。这里g()=ln(),称
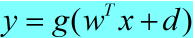 为广义线性模型。
为广义线性模型。
知识回忆:与最小二乘法使最小均方误差函数最小而求得参数不同,最大似然估计法是根据使抽取的样本发生概率最大化,从而求出参数。
reference:机器学习-周志华 清华大学出版社















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









