








目录
BiLSTM+CRF
注:
1、以下所有内容均非原创,是集合几篇内容不错的资料集中整理的,含理论讲解、公式推导、代码结合等多个过程,重在讲解 CRF 相关知识点。
2、CSDN 使用 Katex 渲染公式,部分语法可能有问题,{align*} 改用 {aligned} ,背景颜色 \bbox[color][contenc] 改 \colorbox{#e1ffc1}{$ \frac{1}{2} $} 12
BiLSTM + CRF 在 NER 领域中被广泛使用,尤其是 BERT 诞生以前,因此该模型可作为 baseline 模型去尝试。
1、原理讲解
1.1 LSTM
LSTM 原理比较简单,参考下图:
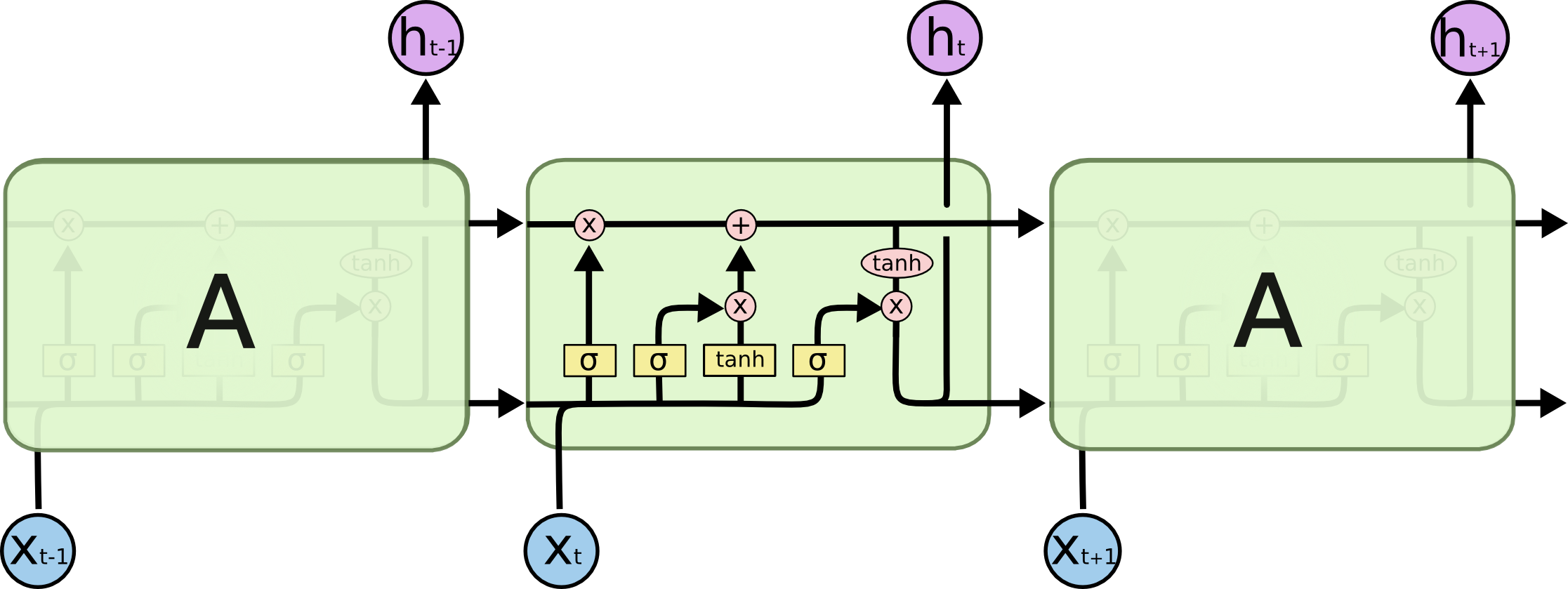
涉及到的主要计算过程为:
i t = σ ( W i i x t + b i i + W h i h t − 1 + b h i ) f t = σ ( W i f x t + b i f + W h f h t − 1 + b h f ) g t = tanh ( W i g x t + b i g + W h g h t − 1 + b h g ) o t = σ ( W i o x t + b i o + W h o h t − 1 + b h o ) c t = f t ⊙ c t − 1 + i t ⊙ g t h t = o t ⊙ tanh ( c t ) \begin{array} {ll} \\ i_t = \sigma(W_{ii} x_t + b_{ii} + W_{hi} h_{t-1} + b_{hi}) \\ f_t = \sigma(W_{if} x_t + b_{if} + W_{hf} h_{t-1} + b_{hf}) \\ g_t = \tanh(W_{ig} x_t + b_{ig} + W_{hg} h_{t-1} + b_{hg}) \\ o_t = \sigma(W_{io} x_t + b_{io} + W_{ho} h_{t-1} + b_{ho}) \\ c_t = f_t \odot c_{t-1} + i_t \odot g_t \\ h_t = o_t \odot \tanh(c_t) \end{array} it=σ(Wiixt+bii+Whiht−1+bhi)ft=σ(Wifxt+bif+Whfht−1+bhf)gt=tanh(Wigxt+big+Whght−1+bhg)ot=σ(Wioxt+bio+Whoht−1+bho)ct=ft⊙ct−1+it⊙gtht=ot⊙tanh(ct)
各个步骤的具体计算过程及图解如下所示:
 |  |
 |  |
关于 LSTM 的更多内容可参考 colah 的博客3。
1.2 BiLSTM
BILSTM 即 双向 LSTM,一般结构如下图所示:

BiLSTM 实际上只是将两个独立的 LSTM 放在一起。对于一个 LSTM,按正常时序进行处理,另一个 LSTM 则按反向时序处理。输出的结果通常采用的是拼接(concat),而不是求和。即上图中的 y = [ A ∣ A ′ ] y=[A|A'] y=[A∣A′]。
需要注意的是,拼接的过程是正向的第一个时序与反向的最后一个时序进行拼接,依次类推。
1.3 CRF
条件随机场(crf) 在序列标注任务中被广泛使用,但其涉及的概率知识让很多人望而却步,因此下面将通过一个 demo 示例,详解整个过程4:
例如,我们有一句话 x x x,包含 5 个字, w 0 , w 1 , w 2 , w 3 , w 4 w_0, w_1, w_2, w_3, w_4 w0,w1,w2,w3,w4,其中 [ w 0 w_0 w0, w 1 w_1 w1] 是一个”人名”实体,[ w 3 w_3 w3] 是一个“组织”实体,则整个语料我们可标注为 “B-Person I-Person O B-Organization O”。

如上图所示,这就是我们整个 BiLSTM + CRF 的架构图以及 CRF 输出层内容,通过选择概率最大的选项输出最终结果。那么问题来了,BiLSTM 的输出层不也是标签序列嘛,为什么还需要 CRF,直接 argmax BiLSTM 的输出层不行嘛?就像下图这样:

BiLSTM 的输出层也是每种标签的概率输出值,通过选择最大值,也可以做出正确的结果(如图中红色标注),然而事情并非总是如此,更多的时候,得到的是下面的情形:

显而易见,“I-Organization I-Person” 是无效的,至少我们不允许一个实体的标注以 “I” 开头,也不能两个实体的 “I” 连续出现,也就是说我们需要对输出结果强加一些约束条件,这些约束可能是:
- 句子中第一个词的标签应该以 “B-” 或者 “O” 开头,不能是 “I-”
- “B-label1 I-label2 I-label3 I-…” ,在这个模式中,label1,label2,label3… 应该是同一个命名实体的标签。例如,“B-Person I-Person”是有效的,但是“B-Person I-Organization”是无效的。
- “O I-label” 是无效的。一个命名实体的第一个标签应以“B-”开头,而不能是“I-”,换句话说,“O B-label”模式是有效的。
- …
要理解 CRF 的工作原理,我们需要掌握两个分数:散发(Emission) 分数和转移(Transition) 分数。
1.3.1 Emission Score
Emission Score 来自于 BiLSTM 的输出,例如上图中, w 0 w_0 w0 被预测为 “B-Person” 的概率为 1.5。为了方便,我们把标签标上序号,{0: “B-Person”, 1: “I-Person”, 2: “B-Organization”, 3: “I-Organization”, 4:“O”}。
我们用 x i , y j x_{i, y_j} xi,yj 来表示 Emission Score,其中 i i i 是词在句子中的序号, y j y_j yj 是标签的索引。例如 x i = 1 , y j = 2 = x w 1 , B − O r g a n i z a t i o n = 0.1 x_{i=1,y_j=2} = x_{w_1,B-Organization} = 0.1 xi=1,yj=2=xw1,B−Organization=0.1,即 w 1 w_1 w1 的标签被预测为 “B-Organization” 的概率是 0.1.
1.3.2 Transition 分数
我们使用 t y i y j t_{y_iy_j} tyiyj 表示一个转移分数。例如 t B − P e r s o n , I − P e r s o n = 0.9 t_{B-Person, I-Person} = 0.9 tB−Person,I−Person=0.9 意味着标签 B − P e r s o n → I − P e r s o n B-Person \rightarrow I-Person B−Person→I−Person 是 0.9. 因此,我们有一个转移分数矩阵,存储了任意两个标签之间转移的全部分数。
为了是转移矩阵更加强健,我们增加了两个标签,START 和 END。 START 意味着一个句子的开始,但不是第一个词。END 意味着一个句子结束了。
这有一个转移矩阵的例子,这里面包含了 START 和 END 这两个额外的标签。
| START | B-Person | I-Person | B-Organization | I-Organization | O | END | |
|---|---|---|---|---|---|---|---|
| START | 0 | 0.8 | 0.007 | 0.7 | 0.0008 | 0.9 | 0.08 |
| B-Person | 0 | 0.6 | 0.9 | 0.2 | 0.0006 | 0.6 | 0.008 |
| I-Person | -1 | 0.5 | 0.53 | 0.55 | 0.0003 | 0.85 | 0.08 |
| B-Organization | 0.9 | 0.5 | 0.0003 | 0.25 | 0.8 | 0.77 | 0.006 |
| I-Organization | -0.9 | 0.45 | 0.007 | 0.7 | 0.65 | 0.76 | 0.2 |
| O | 0 | 0.65 | 0.0007 | 0.7 | 0.0008 | 0.9 | 0.08 |
| END | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
如上表所示,我们可以发现转移矩阵学到了一些有用的约束。
- 句子中第一个词的标签应该以 “B-” 或者 “O” 开头,不能是 “I-” (从“START”转移到“I-Person 或 I-Organization”的转移分数很低)
- “B-label1 I-label2 I-label3 I-…” ,在这个模式中,label1,label2,label3… 应该是同一个命名实体的标签。例如,“B-Person I-Person”是有效的,但是“B-Person I-Organization”是无效的。(例如,从“B-Organization”到“I-Person”的分数仅有0.0003,比转移到其他标签低很多)
- “O I-label” 是无效的。一个命名实体的第一个标签应以“B-”开头,而不能是“I-”,换句话说,“O B-label”模式是有效的。(再一次。例如,tO,I−PersontO,I−Person 的分数很低)
- …
关于这个转移矩阵,你可能会有一个问题这个转移矩阵从哪里怎么得到的呢?
实际上,这个矩阵是 BiLSTM-CRF 模型的一个参数。在你训练你的模型之前,你应该随机初始化所有的转移分数。在训练过程中,这些随机的分数会自动被更新。换句话说,CRF 层可以自动学习这些约束。我们不需要手工构建这个矩阵。这个分数随着训练迭代增加会越来越合理。
1.3.3 CRF loss
CRF 损失函数由两部分组成,真实路径的分数和所有路径的总分数。真实路径的分数应该是所有路径中分数最高的。例如我们有标签类别:{0: “B-Person”, 1: “I-Person”, 2: “B-Organization”, 3: “I-Organization”, 4:“O”, 5: “START”, 6: “END”}
一个包含 5 个字的句子,其可能的标签序列如下:
-
- START B-Person B-Person B-Person B-Person B-Person END
-
- START B-Person I-Person B-Person B-Person B-Person END
- ……
- 10. START B-Person I-Person O B-Organization O END
- N. O O O O O O O
假设,每种可能的路径有一个分数 p i p_i pi,总共有 N N N 种可能的路径,所有路径的总分数是 P t o t a l = P 1 + P 2 + … + P N = e S 1 + e S 2 + … + e S N P_{total} = P_1 + P_2 + … + P_N = e^{S_1} + e^{S_2} + … + e^{S_N} Ptotal=P1+P2+…+PN=eS1+eS2+…+eSN ,其中 e e e 为自然底数, S i = E m i s s i o n S c o r e + T r a n s i t i o n S c o r e S_i=Emission\ Score + Transition\ Score Si=Emission Score+Transition Score
如果我们说第 10 个路径是真实路径,换句话说,第 10 个路径是我们训练数据集的标注标签。则分数 P 10 P_{10} P10 在所有可能路径中应该具有最高的百分比。
下面给出一个损失函数的定义,在训练过程中,BiLSTM-CRF 模型的参数值会被一次次的更新,使得真实路径的分数越来越高。
L o s s F u n c t i o n = − P R e a l P a t h P 1 + P 2 + … + P N Loss Function = -\frac{P_{RealPath}}{P_1 + P_2 + … + P_N} LossFunction=−P1+P2+…+PNPRealPath
注:英文版原文中此处没有加负号,而是在后面引入负号,我觉得此处应该加入负号,既然是损失函数,自然是期望分值越小越好。
现在有一些问题:
- 一个路径的分数是如何定义的?
- 如何计算所有可能路径的总分数呢?
- 当我们计算出总分数时,我们需要列举出所有可能的路径吗?(这个问题的答案是 NO)
我们先计算 S i S_i Si ,以真实路径 “START B-Person I-Person O B-Organization O END” 为例,
计算 Emission score
E m i s s i o n S c o r e = x 0 , S T A R T + x 1 , B − P e r s o n + x 2 , I − P e r s o n + x 3 , O + x 4 , B − O r g a n i z a t i o n + x 5 , O + x 6 , E N D EmissionScore=x_{0,START}+x_{1,B-Person}+x_{2,I-Person}+x_{3,O}+x_{4,B-Organization}+x_{5,O}+x_{6,END} EmissionScore=x0,START+x1,B−Person+x2,I−Person+x3,O+x4,B−Organization+x5,O+x6,END
- 如果第 i n d e x index index个单词被标记为 l a b e l label label,则分数为 x i n d e x , l a b e l x_{index,label} xindex,label
- 具体的每一项的分数来自于 Bi-LSTM 的输出
- 对于 x 0 , S T A R T x_{0,START} x0,START 和 x 6 , E N D x_{6,END} x6,END 我们可以将它们设置为 0
计算 Transition score
T r a n s i t i o n S c o r e = t S T A R T → B − P e r s o n + t B − P e r s o n → I − P e r s o n + t I − P e r s o n → O + t 0 → B − O r g a n i z a t i o n + t B − O r g a n i z a t i o n → O + t O → E N D TransitionScore=t_{START \rightarrow B-Person} + t_{B-Person \rightarrow I-Person} + t_{I-Person \rightarrow O} + t_{0 \rightarrow B-Organization} + t_{B-Organization \rightarrow O} + t_{O \rightarrow END} TransitionScore=tSTART→B−Person+tB−Person→I−Person+tI−Person→O+t0→B−Organization+tB−Organization→O+tO→END
- t l a b e l 1 → l a b e l 2 t_{label1 \rightarrow label2} tlabel1→label2 是从 l a b e l 1 label1 label1 转移到 l a b e l 2 label2 label2 的转移分数
- 这个分数来自 CRF 层。换句话说,这些转移分数实际上是 CRF 层的参数
有了这些基础操作,我们就可以计算 S i S_i Si 以及路径分数 e S i e^{S_i} eSi,接下来就是计算所有可能路径的所有分数,一猜你就要说枚举所有的挨个计算,这种方式理论上肯定算得出,但计算量多大,效率非常低。
下面的内容计算内容较多,我们放到附录部分,不在此继续展开。
1.3.4 推理
对一条数据进行实体类型预测,该过程比较常用的算法有维特比算法,因涉及的计算量较大,我们将其 放到附录部分。
2、核心代码56
该部分采用 PyTorch 计算框架,与 TensorFlow 相比,PyTorch 是采用动态神经网络计算图的,而 TensorFlow 是静态的,动态最直接的好处是便于 debug,你可以观察每一步的计算变化,就如同常规的 Python 代码调试一般,而 TensorFlow 则不同,你无法直观的 debug 或者 print 一些变量的实际数值,而只是一些静态图结点的抽象描述,如张量维度。这么说的意思并不意味着静态图不如动态图,静态图的好处是只编译一次即可,而动态的需要对每一组实例重新定义计算图。
回顾一下上面的部分,假设我们有序列 x x x,其标签序列为 y y y,我们需要计算:
P ( y ∣ x ) = exp ( Score ( x , y ) ) ∑ y ′ exp ( Score ( x , y ′ ) ) P(y|x) = \frac{\exp{(\text{Score}(x, y)})}{\sum_{y'} \exp{(\text{Score}(x, y')})} P(y∣x)=∑y′exp(Score(x,y′))exp(Score(x,y))
其中的 score 是通过定义一些对数运算 log ψ i ( x , y ) \log \psi_i(x,y) logψi(x,y) 来确定:
Score ( x , y ) = ∑ i log ψ i ( x , y ) \text{Score}(x,y) = \sum_i \log \psi_i(x,y) Score(x,y)=i∑logψi(x,y)
接下来,我们定义 emission 和 transition 两种 score:
Score ( x , y ) = ∑ i log ψ EMIT ( y i → x i ) + log ψ TRANS ( y i − 1 → y i ) \text{Score}(x,y) = \sum_i \log \psi_\text{EMIT}(y_i \rightarrow x_i) + \log \psi_\text{TRANS}(y_{i-1} \rightarrow y_i) Score(x,y)=i∑logψEMIT(yi→xi)+logψTRANS(yi−1→yi)
2.1、CRF 部分整体概览7
简化解构如下, 整个计算过程大致包括:
def log_sum_exp(smat): # 模型中经常用到的一种路径运算的实现
...
class BiLSTM_CRF(nn.Module):
def neg_log_likelihood(self, features, lengths, tags): # 求负对数似然,作为loss
...
def _score_sentence(self, frames, tags): # 求分子
...
def _forward_alg(self, frames): # 求分母
...
def _viterbi_decode(self, frames): # 求最优路径分值和最优路径
...
2.2、计算 loss
详见 neg_log_likelihood(features, lengths, tags) 方法:
- 这里的 features 是 LSTM 求出每一个字到每种 tag 的 Emission 分数(注意不是概率,加和不一定等于 1,这里与 HMM 不同)
- 求出指定隐状态路径 tags 对应的分值
gold_score,实际就是求正确路径的得分 - 求出所有路径的分值之和
forward_score - 最后,两者相减, − log ( a / b ) = − [ log ( a ) − log ( b ) ] = log ( b ) − log ( a ) -\log(a / b) = -[\log(a) - \log(b)] = \log(b) - \log(a) −log(a/b)=−[log(a)−log(b)]=log(b)−log(a)
P ( tags ∣ words ) ≜ exp ( Ψ ( tags, words ) ) ∑ t ∈ AllPath exp ( Ψ ( t , words ) ) P(\text { tags } \mid \text { words }) \triangleq \frac{\exp (\Psi(\text { tags, words }))}{\sum_{\mathbf{t} \in \text { AllPath }} \exp (\Psi(\mathbf{t}, \text { words }))} P( tags ∣ words )≜∑t∈ AllPath exp(Ψ(t, words ))exp(Ψ( tags, words ))
− log P ( tags ∣ words ) ⏟ 负对数似然,作为 loss = log [ ∑ t ∈ All Path exp ( Ψ ( t , words ) ) ] ⏟ 分母对数 − Ψ ( tags , words ) ⏟ 分子对数 \underbrace{-\log P(\text{tags} \mid \text{words})}_{\text{负对数似然,作为 loss}}=\underbrace{\log \left[\sum_{t \in \text { All } \operatorname{Path}} \exp (\Psi(\mathbf{t}, \text { words }))\right]}_{\text{分母对数}}-\underbrace{\Psi(\text{tags}, \text{words})}_{\text{分子对数}} 负对数似然,作为 loss −logP(tags∣words)=分母对数 log[t∈ All Path∑exp(Ψ(t, words ))]−分子对数 Ψ(tags,words)
2.3、计算分子部分
详见 _score_sentence() 方法:
定义第 i i i 个单词为 w i w_i wi,第 i i i 个 tag 为 t i t_i ti,序列长度为 L L L;
定义转移矩阵 T i , j T_{i,j} Ti,j 表示从标签 i i i 到标签 j j j 的转移分数, E i j E_{ij} Eij 表示第 i i i 个词预测为 j j j 标签的 Emission 分数 ,则:
log ( Ψ ( tags, words ) ) ≜ [ T B O S , t 1 + E t 1 , w 1 + T t 1 , t 2 + E t 2 , w 2 + ⋯ + E t L , w L ] + T t L , E O S \log (\Psi(\text {tags, words})) \triangleq\left[T_{B O S, t_{1}}+E_{t_{1}, w_{1}}+T_{t_{1}, t_{2}}+E_{t_{2}, w_{2}}+\cdots+E_{t_{L}, w_{L}}\right]+T_{t_{L}, E O S} log(Ψ(tags, words))≜[TBOS,t1+Et1,w1+Tt1,t2+Et2,w2+⋯+EtL,wL]+TtL,EOS
定义 t 0 ≜ BOS t_0 \triangleq \text{BOS} t0≜BOS, L H S = [ ∑ i = 1 L T i i − 1 , t i + E t i , w i ] + T t L , E O S L H S=\left[\sum_{i=1}^{L} T_{i_{i-1}, t_{i}}+E_{t_{i}, w_{i}}\right]+T_{t_{L}, E O S} LHS=[∑i=1LTii−1,ti+Eti,wi]+TtL,EOS
2.4、计算分母部分
详见 _forward_alg 前半部分
分母对数 = log [ ∑ t ∈ All Path exp ( Ψ ( t , words ) ) ] \text{分母对数}=\log \left[\sum_{t \in \text { All } \operatorname{Path}} \exp (\Psi(\mathbf{t}, \text { words }))\right] 分母对数=log[t∈ All Path∑exp(Ψ(t, words ))]
计算分母的困难在于
t
∈
All Path
\text{t} \in \text{All Path}
t∈All Path 难以穷举,例如,当 len(tags)=5且len(words)=10,则
t
t
t 的取值空间是
5
10
5^{10}
510,所以实际计算采用的是沿序列(时间轴)做动态规划,具体的递推关系如下:
- 穷举所有长度为 L − 1 L-1 L−1 的路径集合,记做 P L − 1 \mathbb{P}^{L-1} PL−1
- 定义
α
i
,
j
≜
log
[
∑
y
∈
P
i
−
1
exp
(
Ψ
(
w
1
∼
i
,
y
1
∼
i
−
1
,
y
i
=
j
)
)
]
\alpha_{i, j} \triangleq \log \left[\sum_{\mathbf{y} \in \mathbb{P}^{i-1}} \exp \left(\Psi\left(\mathbf{w}_{1 \sim i}, \mathbf{y}_{1 \sim i-1}, y_{i}=j\right)\right)\right]
αi,j≜log[∑y∈Pi−1exp(Ψ(w1∼i,y1∼i−1,yi=j))],即 "
i
i
i 时刻到状态
j
j
j 的所有路径分数"的
log_sum_exp
因此,我们有:
分母对数 = log [ ∑ t ∈ AllPath exp ( Ψ ( t , words ) ) ] \text{分母对数}=\log \left[\sum_{t \in \text { AllPath }} \exp (\Psi(\mathbf{t}, \text { words }))\right] 分母对数=log[t∈ AllPath ∑exp(Ψ(t, words ))]
(展开定义) = = log [ ∑ y ∈ P L exp ( Ψ ( w 1 ∼ L , y 1 ∼ L ) ) ] \text{(展开定义)}==\log \left[\sum_{\mathbf{y} \in \mathbf{P}^{L}} \exp \left(\Psi\left(\mathbf{w}_{1 \sim L}, \mathbf{y}_{1 \sim L}\right)\right)\right] (展开定义)==log⎣⎡y∈PL∑exp(Ψ(w1∼L,y1∼L))⎦⎤
(穷举 最后一步隐藏状态 j ) = log [ ∑ j ∈ A l l T a g s ∑ y ∈ p L − 1 exp ( Ψ ( w 1 ∼ L − 1 , y 1 ∼ L − 1 , w i , j ) ) ] \text{(穷举}\colorbox{#e1ffc1}{最后一步隐藏状态 j}\text{)}=\log \left[\colorbox{#e1ffc1}{$\sum_{j \in A l l T a g s}$} \sum_{\mathbf{y} \in \mathrm{p}^{L-1}} \exp \left(\Psi\left(\mathbf{w}_{1 \sim L-1}, \mathbf{y}_{1 \sim L-1}, w_{i}, \colorbox{#e1ffc1}{j}\right)\right)\right] (穷举最后一步隐藏状态 j)=log⎣⎡∑j∈AllTagsy∈pL−1∑exp(Ψ(w1∼L−1,y1∼L−1,wi,j))⎦⎤
(带入 α 定义) = log [ ∑ j ∈ AllTags exp ( α L − 1 , j ) ] = log_sum_exp ( α L − 1 , ? ) \begin{aligned}\text{(带入}\alpha\text{定义)}&=\log \left[\sum_{j \in \text {AllTags}} \exp \left(\alpha_{L-1, j}\right)\right] \\ &=\text{log\_sum\_exp} \left(\alpha_{L-1, ?}\right) \end{aligned} (带入α定义)=log⎣⎡j∈AllTags∑exp(αL−1,j)⎦⎤=log_sum_exp(αL−1,?)
至此,我们将待求的”分母对数“转化成了关于
α
\alpha
α 向量的 log_sum_exp 形式;只要能动态规划求出
α
\alpha
α 向量,问题就得到解决,
α
\alpha
α 的递推关系如下:
α i , j ≜ log [ ∑ y ∈ P i − 1 exp ( Ψ ( w 1 ∼ i , f 1 ∼ i − 1 , y i = j ) ⏟ i 时刻到达 j 状态 ) ] = log [ ∑ y ∈ p i − 1 exp ( Ψ ( w 1 ∼ i − 1 , y 1 ∼ i − 2 , y i − 1 = j ′ ) ⏟ i − 1 时刻到达 j 状态 + T j ′ , j ⏟ 状态转移: j ′ → j + E j , w i ⏟ 状态发射: j → w i ) ] = log [ ∑ j exp ( α i − 1 , j ′ + T j ′ , j + E j , w i ) ] … (递归定义) \begin{aligned} \alpha_{i,j} &\triangleq \log\left [\sum_{y \in P^{i-1}}\exp\left(\underbrace{\Psi(\mathbf{w}_{1\sim i},\mathbf{f}_{1 \sim i-1}, y_i=j)}_{i\text{时刻到达}j\text{状态}}\right)\right ] \\ &= \log \left[ \sum_{y \in p^{i-1}}\exp\left (\underbrace{\Psi(\mathbf{w}_{1 \sim i-1}, \mathbf{y}_{1 \sim i-2}, y_{i-1}=j')}_{i-1\text{时刻到达}j\text{状态}}+\underbrace{T_{j',j}}_{\text{状态转移:}j' \to j}+\underbrace{E_{j,w_i}}_{\text{状态发射:}j \to w_i}\right)\right] \\ &=\log \left[\sum_j \exp\left(\alpha_{i-1,j'}+T_{j',j}+E_{j, w_i}\right)\right] \\ & \ldots\text{(递归定义)} \end{aligned} αi,j≜log⎣⎡y∈Pi−1∑exp⎝⎛i时刻到达j状态 Ψ(w1∼i,f1∼i−1,yi=j)⎠⎞⎦⎤=log⎣⎢⎡y∈pi−1∑exp⎝⎜⎛i−1时刻到达j状态 Ψ(w1∼i−1,y1∼i−2,yi−1=j′)+状态转移:j′→j Tj′,j+状态发射:j→wi Ej,wi⎠⎟⎞⎦⎥⎤=log[j∑exp(αi−1,j′+Tj′,j+Ej,wi)]…(递归定义)
(递归终止条件) α 0 , j = { 0 ⏟ = log ( 1 ) ,集中了全部概率 , j=BOS − 10000 ⏟ 用来代替 log ( 0 ) = − ∞ , else \text{(递归终止条件)}\ \ \ \ \alpha_{0,j}=\begin{cases}\underbrace{0}_{=\log(1)\text{,集中了全部概率}}, & \text{j=BOS} \\[2ex] \underbrace{-10000}_{\text{用来代替} \log(0)=-\infty}, & \text{else}\end{cases} (递归终止条件) α0,j=⎩⎪⎪⎨⎪⎪⎧=log(1),集中了全部概率 0,用来代替log(0)=−∞ −10000,j=BOSelse
根据上述推导,观察【单个状态】 α i − 1 , j ′ → α i , j \alpha_{i-1,j'} \to \alpha_{i,j} αi−1,j′→αi,j 的递推过程:
- 已知: α i − 1 , j ′ \alpha_{i-1,j'} αi−1,j′
- 求: α i , j \alpha_{i,j} αi,j
- 解:加上 j ′ → j j' \to j j′→j 的状态转移分和 j → w i j \to w_i j→wi 的发射分,即 α i , j = log [ ∑ j ′ exp ( α i − 1 , j ′ + j j ′ , j + E j , w i ) ] \alpha_{i, j}=\log \left[\sum_{j^{\prime}} \exp \left(\alpha_{i-1, j^{\prime}}+j_{j^{\prime}, j}+E_{j, w_{i}}\right)\right] αi,j=log[∑j′exp(αi−1,j′+jj′,j+Ej,wi)]
将上述【单个状态】的推导加以概括,得到【矩阵化】写法,以 1 -> 2 时刻为例:
α ≜ ( α 11 α 12 α 13 ) ⟶ 第一时刻的状态行向量转置为列向量,然后广播为矩阵 ( α 11 α 11 α 11 α 12 α 12 α 12 α 13 α 13 α 13 ) \alpha \triangleq \begin{pmatrix}\alpha_{11}&&\alpha_{12} &&\alpha_{13}\end{pmatrix} \overset{\text{第一时刻的状态行向量转置为列向量,然后广播为矩阵}}\longrightarrow \begin{pmatrix}\alpha_{11}&&\alpha_{11} &&\alpha_{11} \\ \alpha_{12}&&\alpha_{12} &&\alpha_{12} \\ \alpha_{13}&&\alpha_{13} &&\alpha_{13} \end{pmatrix} α≜(α11α12α13)⟶第一时刻的状态行向量转置为列向量,然后广播为矩阵⎝⎛α11α12α13α11α12α13α11α12α13⎠⎞
T ≜ ( T 11 T 12 T 13 T 21 T 22 T 23 T 31 T 32 T 33 ) ⟶ 正常跟左右两个列/行向量相加,导致它们被广播 … T 自己无需变形 T \triangleq \begin{pmatrix}T_{11}&&T_{12} &&T_{13} \\ T_{21}&&T_{22} &&T_{23} \\ T_{31}&&T_{32} &&T_{33} \end{pmatrix} \stackrel{\text{正常跟左右两个列/行向量相加,导致它们被广播}} \longrightarrow \ldots \text{T 自己无需变形} T≜⎝⎛T11T21T31T12T22T32T13T23T33⎠⎞⟶正常跟左右两个列/行向量相加,导致它们被广播…T 自己无需变形
E ≜ ( E 21 E 22 E 23 ) ⟶ 行向量广播 ( E 21 E 22 E 23 E 21 E 22 E 23 E 21 E 22 E 23 ) E \triangleq \begin{pmatrix}E_{21}&&E_{22} &&E_{23}\end{pmatrix} \stackrel {\text{行向量广播}} \longrightarrow \begin{pmatrix}E_{21}&&E_{22} &&E_{23} \\ E_{21}&&E_{22} &&E_{23} \\ E_{21}&&E_{22} &&E_{23} \end{pmatrix} E≜(E21E22E23)⟶行向量广播⎝⎛E21E21E21E22E22E22E23E23E23⎠⎞
(三者广播相加) α + T + E = ( α 11 + T 11 + E 21 α 11 + T 12 + E 22 a 11 + T 13 + E 23 α 12 + T 21 + E 21 α 12 + T 22 + E 22 a 12 + T 23 + E 23 α 13 + T 31 + E 21 α 13 + T 32 + E 22 a 13 + T 33 + E 23 ) (对每一列求 log_sum_exp,最终得到行向量;以第三列为例) = ( … … log [ exp ( α 11 + T 13 + E 23 ) + exp ( α 12 + T 23 + E 23 ) + … ] ) ≜ 第2时刻的新 α = ( α 21 α 22 α 23 ) \begin{aligned} \text{(三者广播相加)} \ \ \ \alpha +T + E &= \left(\begin{array}{lll} \alpha_{11}+T_{11}+E_{21} & \alpha_{11}+T_{12}+E_{22} & \colorbox{#e1ffc1}{$a_{11}+T_{13}+E_{23}$} \\ \alpha_{12}+T_{21}+E_{21} & \alpha_{12}+T_{22}+E_{22} & \colorbox{#e1ffc1}{$a_{12}+T_{23}+E_{23}$} \\ \alpha_{13}+T_{31}+E_{21} & \alpha_{13}+T_{32}+E_{22} & \colorbox{#e1ffc1}{$a_{13}+T_{33}+E_{23}$} \end{array}\right) \\ & \text{(对每一列求 log\_sum\_exp,最终得到行向量;以第三列为例)} \\ &= \begin{pmatrix}\ldots && \ldots && \colorbox{#e1ffc1}{$\log\left[\exp(\alpha_{11}+T_{13}+E_{23})+\exp(\alpha_{12}+T_{23}+E_{23})+\ldots\right]$}\end{pmatrix}\\ &\triangleq \text{第2时刻的新}\alpha=\begin{pmatrix}\alpha_{21} && \alpha_{22} && \colorbox{#e1ffc1}{$\alpha_{23}$}\end{pmatrix}\end{aligned} (三者广播相加) α+T+E=⎝⎜⎛α11+T11+E21α12+T21+E21α13+T31+E21α11+T12+E22α12+T22+E22α13+T32+E22a11+T13+E23a12+T23+E23a13+T33+E23⎠⎟⎞(对每一列求 log_sum_exp,最终得到行向量;以第三列为例)=(……log[exp(α11+T13+E23)+exp(α12+T23+E23)+…])≜第2时刻的新α=(α21α22α23)
后半部分实际做的与 log_sum_exp 完全一致,只不过便于理解,将各个步骤拆分
经过上面一顿折腾,在计算 α + T + E \alpha+T+E α+T+E 之后,我们得到一个 DP 状态矩阵,我们下面称之为 smat,下面我们以一个具体的小示例解释这个过程,假设我们有:
s m a t = α + T + E = [ 1 3 9 2 9 1 3 4 7 ] smat=\alpha+T+E = \begin{bmatrix}1 && 3 && 9 \\2 && 9 && 1 \\ 3 && 4&& 7 \end{bmatrix} smat=α+T+E=⎣⎡123394917⎦⎤
smat[i][j] 表示从状态
i
i
i 到 状态
j
j
j 的分数,下面我们针对每一列求 log_sum_exp ,意义是求取当前时间步下到各个状态下的分值(综合所有来源),例如 smat[:,2]=[9,1,7],表示当前时间步下到达状态”2“有三种可能的来源,分别来自上一步的状态 ”0,1,2“,计算结果为:
log_sum_exp
(
9
,
1
,
7
)
=
log
[
exp
(
9
)
+
exp
(
1
)
+
exp
(
7
)
]
=
3.964
\text{log\_sum\_exp}(9,1,7)=\log\left[\exp(9)+\exp(1)+\exp(7)\right]=3.964
log_sum_exp(9,1,7)=log[exp(9)+exp(1)+exp(7)]=3.964,这意味着综合所有可能的来源路径,当前时刻能到状态 ”2“ 的分值是 3.964,前两列的计算过程同理可得。
值得注意的是,实际计算过程中采用了一点数学技巧,目的是避免数值上溢。例如,假设 smat[:,2]=[1,999,4],则:
log_sum_exp
(
1
,
999
,
4
)
=
log
(
exp
(
1
)
+
exp
(
999
)
+
exp
(
4
)
)
直接计算会遭遇 exp(999) = INF 上溢问题
=
log
(
exp
(
1
−
999
)
exp
(
999
)
+
exp
(
999
−
999
)
exp
(
999
)
+
exp
(
4
−
999
)
exp
(
999
)
)
每个元素先乘后除 exp(999)
=
log
(
[
exp
(
1
−
999
)
+
exp
(
999
−
999
)
+
exp
(
4
−
999
)
]
∗
exp
(
999
)
)
提取公因式 exp(999)
=
log
(
[
exp
(
1
−
999
)
+
exp
(
999
−
999
)
+
exp
(
4
−
999
)
]
)
+
log
(
exp
(
999
)
)
l
o
g
乘
法
拆
解
成
加
法
=
log
(
[
exp
(
1
−
999
)
+
exp
(
999
−
999
)
+
exp
(
4
−
999
)
]
)
+
999
此处exp(?)内部都是非正数,不会发生上溢
=
log
(
[
exp
(
s
m
a
t
[
0
]
−
v
m
a
x
)
+
exp
(
s
m
a
t
[
1
]
−
v
m
a
x
)
+
exp
(
s
m
a
t
[
2
]
−
v
m
a
x
)
]
)
+
v
m
a
x
符号化表达
\begin{aligned} \text{log\_sum\_exp}(1, 999, 4) &= \log(\exp(1) + \exp(999) + \exp(4)) & \text{直接计算会遭遇 exp(999) = INF 上溢问题} \\ &= \log(\exp(1-999)\exp(999) + \exp(999-999)\exp(999) + \exp(4-999)\exp(999)) & \text{每个元素先乘后除 exp(999)} \\ &= \log([\exp(1-999) + \exp(999-999) + \exp(4-999)] * \exp(999)) &\text{提取公因式 exp(999)} \\ &= \log([\exp(1-999) + \exp(999-999) + \exp(4-999)]) + \log(\exp(999)) &{log乘法拆解成加法} \\ &= \log([\exp(1-999) + \exp(999-999) + \exp(4-999)]) + 999 &\text{此处exp(?)内部都是非正数,不会发生上溢} \\ &= \log([\exp(smat[0]-vmax) + \exp(smat[1]-vmax) + \exp(smat[2]-vmax)]) + vmax &\text{符号化表达} \end{aligned}
log_sum_exp(1,999,4)=log(exp(1)+exp(999)+exp(4))=log(exp(1−999)exp(999)+exp(999−999)exp(999)+exp(4−999)exp(999))=log([exp(1−999)+exp(999−999)+exp(4−999)]∗exp(999))=log([exp(1−999)+exp(999−999)+exp(4−999)])+log(exp(999))=log([exp(1−999)+exp(999−999)+exp(4−999)])+999=log([exp(smat[0]−vmax)+exp(smat[1]−vmax)+exp(smat[2]−vmax)])+vmax直接计算会遭遇 exp(999) = INF 上溢问题每个元素先乘后除 exp(999)提取公因式 exp(999)log乘法拆解成加法此处exp(?)内部都是非正数,不会发生上溢符号化表达
2.5 维特比解码
详见 _viterbi_decode()
大部分其实与上一部分相似,但是除了迭代更新 α \alpha α 以外,还要跟踪每一个时间步上每一个状态的最优”上一步“来自哪里。
附录
计算所有路径的总分
在前面我们定义我们的损失函数为
L
o
s
s
F
u
n
c
t
i
o
n
=
−
P
R
e
a
l
P
a
t
h
P
1
+
P
2
+
…
+
P
N
Loss Function = -\frac{P_{RealPath}}{P_1 + P_2 + … + P_N}
LossFunction=−P1+P2+…+PNPRealPath,我们对其求 log,即
L
o
g
L
o
s
s
F
u
n
c
t
i
o
n
=
−
log
P
R
e
a
l
P
a
t
h
P
1
+
P
2
+
…
+
P
N
=
−
log
e
S
R
e
a
l
P
a
t
h
e
S
1
+
e
S
2
+
…
+
e
S
N
=
−
(
log
(
e
S
R
e
a
l
P
a
t
h
)
−
log
(
e
S
1
+
e
S
2
+
…
+
e
S
N
)
)
=
=
−
(
S
R
e
a
l
P
a
t
h
−
log
(
e
S
1
+
e
S
2
+
…
+
e
S
N
)
)
=
−
(
∑
i
=
1
N
x
i
y
i
+
∑
i
=
1
N
−
1
t
y
i
y
i
+
1
−
log
(
e
S
1
+
e
S
2
+
…
+
e
S
N
)
)
\begin{aligned} Log Loss Function &= - \log \frac{P_{RealPath}}{P_1 + P_2 + … + P_N} \\ &= - \log \frac{e^{S_{RealPath}}}{e^{S_1} + e^{S_2} + … + e^{S_N}} \\ &= - \left(\log \left(e^{S_{RealPath}}\right) - \log \left(e^{S_1} + e^{S_2} + … + e^{S_N}\right)\right) \\ &= = - \left(S_{RealPath} - \log\left(e^{S_1} + e^{S_2} + … + e^{S_N}\right)\right) \\ &= - \left( \sum_{i=1}^{N} x_{iy_i} + \sum_{i=1}^{N-1} t_{y_iy_{i+1}} - \log \left(e^{S_1} + e^{S_2} + … + e^{S_N}\right)\right) \end{aligned}
LogLossFunction=−logP1+P2+…+PNPRealPath=−logeS1+eS2+…+eSNeSRealPath=−(log(eSRealPath)−log(eS1+eS2+…+eSN))==−(SRealPath−log(eS1+eS2+…+eSN))=−(i=1∑Nxiyi+i=1∑N−1tyiyi+1−log(eS1+eS2+…+eSN))
在前面的章节中,我们已经知道了如何计算真实路径的分数,现在我们需要发现一个有效的方式计算
log
(
e
S
1
+
e
S
2
+
…
+
e
S
N
)
\log(e^{S_1} + e^{S_2} + … + e^{S_N})
log(eS1+eS2+…+eSN)
为了简单化,我们假设仅通过一个长度为 3 的句子进行训练: x = [ w 0 , w 1 , w 2 ] \mathbf{x} = [w_0, w_1, w_2] x=[w0,w1,w2],此外,在我们的数据集中有两个标签: L a b e l S e t = { l 1 , l 2 } LabelSet = \{l_1,l_2\} LabelSet={l1,l2}
我们从 Bi-LSTM 层的输出中获得了散发**分数,如下表所示:
| l 1 l_1 l1 | l 2 l_2 l2 | |
|---|---|---|
| w 0 w_0 w0 | x 01 x_{01} x01 | x 02 x_{02} x02 |
| w 1 w_1 w1 | x 11 x_{11} x11 | x 12 x_{12} x12 |
| w 2 w_2 w2 | x 21 x_{21} x21 | x 22 x_{22} x22 |
x i j x_{ij} xij 表示的是 w i w_i wi 的标签是 l j l_j lj。
此外,CRF 层的转移分数如下表所示:
| l 1 l_1 l1 | l 2 l_2 l2 | |
|---|---|---|
| l 1 l_1 l1 | t 11 t_{11} t11 | t 12 t_{12} t12 |
| l 2 l_2 l2 | t 21 t_{21} t21 | t 22 t_{22} t22 |
t i j t_{ij} tij 表示的是从标签 i i i 到 j j j 的转移分数。
接下来,我们的计算目标是: log ( e S 1 + e S 2 + … + e S N ) \log(e^{S_1} + e^{S_2} + … + e^{S_N}) log(eS1+eS2+…+eSN).
这是一个分数累加的过程。这个想法与动态规划相似。简而言之,首先可以计算 w 0 w_0 w0 的所有可能路径的总分数,然后再计算 w 0 → w 1 w_0 \rightarrow w_1 w0→w1 的总分数,最后,我们使用最新的总分数计算 w 0 → w 1 → w 2 w_0 \rightarrow w_1 \rightarrow w_2 w0→w1→w2。最后的这个总分数就是我们需要的。
在下面的步骤中,我们将看到两个变量:obs 和 previous。previous存储前面步骤中的最后结果。obs标记从当前词中得到的信息。
w 0 w_0 w0:
o b s = [ x 01 , x 02 ] obs = [x_{01}, x_{02}] obs=[x01,x02]
p r e v i o u s = N o n e previous = None previous=None
如果我们的句子中只有一个单词 w 0 w_0 w0。我们从前面的步骤中没有得到任何结果,因此 p r e v i o u s previous previous 是 None。此外,我们只能通过 o b s = [ x 01 , x 02 ] obs = [x_{01}, x_{02}] obs=[x01,x02] 计算第一个词。 x 01 x_{01} x01 和 x 02 x_{02} x02 是上面提到的散发分数。
你可能在想,对于 w 0 w_0 w0 的所有可能路径的总分数是多少?这个答案是非常简单的:
T o t a l S c o r e ( w 0 ) = log ( e x 01 + e x 02 ) TotalScore(w_0)=\log (e^{x_{01}} + e^{x_{02}}) TotalScore(w0)=log(ex01+ex02)
w 0 w_0 w0 → w 1 w_1 w1:
o b s = [ x 11 , x 12 ] obs = [x_{11}, x_{12}] obs=[x11,x12]
p r e v i o u s = [ x 01 , x 02 ] previous = [x_{01}, x_{02}] previous=[x01,x02]
- 把 previous 扩张一下: p r e v i o u s = ( x 01 x 01 x 02 x 02 ) previous =\begin{pmatrix}x_{01}&x_{01}\\ x_{02}&x_{02}\end{pmatrix} previous=(x01x02x01x02)
- 把 obs 扩张一下: o b s = ( x 11 x 12 x 11 x 12 ) obs = \begin{pmatrix}x_{11}&x_{12}\\ x_{11}&x_{12}\end{pmatrix} obs=(x11x11x12x12),扩张 previous 和 obs 为一个矩阵的目的是因为这样计算更高效。
- 对
p
r
e
v
i
o
u
s
previous
previous,
o
b
s
obs
obs 和转移分数求和:
s c o r e s = ( x 01 x 01 x 02 x 02 ) + ( x 11 x 12 x 11 x 12 ) + ( t 11 t 12 t 21 t 22 ) scores =\begin{pmatrix} x_{01}&x_{01}\\ x_{02}&x_{02} \end{pmatrix} + \begin{pmatrix} x_{11}&x_{12}\\ x_{11}&x_{12} \end{pmatrix} + \begin{pmatrix} t_{11}&t_{12}\\ t_{21}&t_{22} \end{pmatrix} scores=(x01x02x01x02)+(x11x11x12x12)+(t11t21t12t22) - s c o r e s = ( x 01 + x 11 + t 11 x 01 + x 12 + t 12 x 02 + x 11 + t 21 x 02 + x 12 + t 22 ) scores = \begin{pmatrix} x_{01}+x_{11}+t_{11}&x_{01}+x_{12}+t_{12}\\ x_{02}+x_{11}+t_{21}&x_{02}+x_{12}+t_{22} \end{pmatrix} scores=(x01+x11+t11x02+x11+t21x01+x12+t12x02+x12+t22)
- 在下次迭代中修改 previous 的值为: p r e v i o u s = [ log ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) , log ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) ] previous=[\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}), \log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})] previous=[log(ex01+x11+t11+ex02+x11+t21),log(ex01+x12+t12+ex02+x12+t22)]
实际,第二次迭代已经计算完了。如果想知道如何计算从
w
0
w_0
w0 到
w
1
w_1
w1 所有可能路径(
l
a
b
e
l
1
label_1
label1 →
l
a
b
e
l
1
label_1
label1,
l
a
b
e
l
1
label_1
label1 →
l
a
b
e
l
2
label_2
label2,
l
a
b
e
l
2
label_2
label2 →
l
a
b
e
l
1
label_1
label1,
l
a
b
e
l
2
label_2
label2 →
l
a
b
e
l
2
label_2
label2)的总分数,你可以通过下面的公式计算。
T
o
t
a
l
S
c
o
r
e
(
w
0
→
w
1
)
=
log
(
e
p
r
e
v
i
o
u
s
[
0
]
+
e
p
r
e
v
i
o
u
s
[
1
]
)
=
log
(
e
log
(
e
x
01
+
x
11
+
t
11
+
e
x
02
+
x
11
+
t
21
)
+
e
log
(
e
x
01
+
x
12
+
t
12
+
e
x
02
+
x
12
+
t
22
)
)
=
log
(
e
x
01
+
x
11
+
t
11
+
e
x
02
+
x
11
+
t
21
+
e
x
01
+
x
12
+
t
12
+
e
x
02
+
x
12
+
t
22
)
\begin{aligned} TotalScore(w_0 \rightarrow w_1)& =\log (e^{previous[0]} + e^{previous[1]})\\ &=\log (e^{\log(e^{x_{01} + x_{11} + t_{11}} + e^{x_{02} + x_{11} + t_{21}})}+e^{\log(e^{x_{01} + x_{12} + t_{12}} + e^{x_{02} + x_{12} + t_{22}})})\\ &=\log(e^{x_{01} + x_{11} + t_{11}}+e^{x_{02} + x_{11} + t_{21}} + e^{x_{01} + x_{12} + t_{12}} + e^{x_{02} + x_{12} + t_{22}}) \end{aligned}
TotalScore(w0→w1)=log(eprevious[0]+eprevious[1])=log(elog(ex01+x11+t11+ex02+x11+t21)+elog(ex01+x12+t12+ex02+x12+t22))=log(ex01+x11+t11+ex02+x11+t21+ex01+x12+t12+ex02+x12+t22)
实际这就是我们的目标 log ( e S 1 + e S 2 + … + e S N ) \log(e^{S_1} + e^{S_2} + … + e^{S_N}) log(eS1+eS2+…+eSN).
在这个等式中:
- S 1 = x 01 + x 11 + t 11 S_1 = x_{01}+x_{11}+t_{11} S1=x01+x11+t11 ( l a b e l 1 → l a b e l 1 label_1 \rightarrow label_1 label1→label1)
- S 2 = x 02 + x 11 + t 21 S_2 = x_{02}+x_{11}+t_{21} S2=x02+x11+t21 ( l a b e l 2 → l a b e l 1 label_2 \rightarrow label_1 label2→label1)
- S 3 = x 01 + x 12 + t 12 S_3 = x_{01}+x_{12}+t_{12} S3=x01+x12+t12 ( l a b e l 1 → l a b e l 2 label_1 \rightarrow label_2 label1→label2)
- S 4 = x 02 + x 12 + t 22 S_4 = x_{02}+x_{12}+t_{22} S4=x02+x12+t22 ( l a b e l 2 → l a b e l 2 label_2 \rightarrow label_2 label2→label2)
w 0 w_0 w0 → w 1 w_1 w1 → w 2 w_2 w2:
实际上,这是一个迭代过程,我们会做相同的事情,直到最后一次迭代。
o
b
s
=
[
x
21
,
x
22
]
obs = [x_{21}, x_{22}]
obs=[x21,x22]
p r e v i o u s = [ log ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) , log ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) ] previous=[\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}), \log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})] previous=[log(ex01+x11+t11+ex02+x11+t21),log(ex01+x12+t12+ex02+x12+t22)]
-
扩展 previous 为: p r e v i o u s = ( log ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) log ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) log ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) log ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) ) previous = \begin{pmatrix} \log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})&\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})\\ \log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})&\log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) \end{pmatrix} previous=(log(ex01+x11+t11+ex02+x11+t21)log(ex01+x12+t12+ex02+x12+t22)log(ex01+x11+t11+ex02+x11+t21)log(ex01+x12+t12+ex02+x12+t22))
-
扩展 obs 为 o b s = ( x 21 x 22 x 21 x 22 ) obs = \begin{pmatrix} x_{21}&x_{22}\\ x_{21}&x_{22} \end{pmatrix} obs=(x21x21x22x22)
-
对 previous, obs 以及转移分数求和:
s c o r e s = ( log ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) log ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) log ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) log ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) ) + ( x 21 x 22 x 21 x 22 ) + ( t 11 t 12 t 21 t 22 ) scores = \begin{pmatrix} \log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})&\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})\\ \log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})&\log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) \end{pmatrix} + \begin{pmatrix} x_{21}&x_{22}\\ x_{21}&x_{22} \end{pmatrix} + \begin{pmatrix} t_{11}&t_{12}\\ t_{21}&t_{22} \end{pmatrix} scores=(log(ex01+x11+t11+ex02+x11+t21)log(ex01+x12+t12+ex02+x12+t22)log(ex01+x11+t11+ex02+x11+t21)log(ex01+x12+t12+ex02+x12+t22))+(x21x21x22x22)+(t11t21t12t22)
s c o r e s = ( log ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) + x 21 + t 11 log ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) + x 22 + t 12 log ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) + x 21 + t 21 log ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) + x 22 + t 22 ) scores = \begin{pmatrix} \log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}) + x_{21} + t_{11} &\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}) + x_{22} + t_{12}\\ \log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) + x_{21} + t_{21} &\log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) + x_{22} + t_{22} \end{pmatrix} scores=(log(ex01+x11+t11+ex02+x11+t21)+x21+t11log(ex01+x12+t12+ex02+x12+t22)+x21+t21log(ex01+x11+t11+ex02+x11+t21)+x22+t12log(ex01+x12+t12+ex02+x12+t22)+x22+t22)在下次迭代中修改 previous 的值为:
p r e v i o u s = [ log ( e log ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) + x 21 + t 11 + e log ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) + x 21 + t 21 ) , log ( e log ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) + x 22 + t 12 + e log ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) + x 22 + t 22 ) ] = [ log ( ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) e x 21 + t 11 + ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) e x 21 + t 21 , log ( ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) e x 22 + t 12 + ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) e x 22 + t 22 ) ] \begin{aligned} previous &=[ \log( e^{\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}) + x_{21} + t_{11}} + e^{\log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) + x_{21} + t_{21}} ), \log( e^{\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}) + x_{22} + t_{12}} + e^{\log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) + x_{22} + t_{22}})] \\ &= [\log((e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})e^{x_{21} + t_{11}}+(e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})e^{x_{21} + t_{21}}, \log((e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})e^{x_{22} + t_{12}}+(e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})e^{x_{22} + t_{22}})] \end{aligned} previous=[log(elog(ex01+x11+t11+ex02+x11+t21)+x21+t11+elog(ex01+x12+t12+ex02+x12+t22)+x21+t21),log(elog(ex01+x11+t11+ex02+x11+t21)+x22+t12+elog(ex01+x12+t12+ex02+x12+t22)+x22+t22)]=[log((ex01+x11+t11+ex02+x11+t21)ex21+t11+(ex01+x12+t12+ex02+x12+t22)ex21+t21,log((ex01+x11+t11+ex02+x11+t21)ex22+t12+(ex01+x12+t12+ex02+x12+t22)ex22+t22)]
T o t a l S c o r e ( w 0 → w 1 → w 2 ) = log ( e p r e v i o u s [ 0 ] + e p r e v i o u s [ 1 ] ) = log ( e log ( ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) e x 21 + t 11 + ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) e x 21 + t 21 ) = log ( e log ( ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) e x 21 + t 11 + ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) e x 21 + t 21 ) + e log ( ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 ) e x 22 + t 12 + ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 ) e x 22 + t 22 ) ) = log ( e x 01 + x 11 + t 11 + x 21 + t 11 + e x 02 + x 11 + t 21 + x 21 + t 11 + e x 01 + x 12 + t 12 + x 21 + t 21 + e x 02 + x 12 + t 22 + x 21 + t 21 + e x 01 + x 11 + t 11 + x 22 + t 12 + e x 02 + x 11 + t 21 + x 22 + t 12 + e x 01 + x 12 + t 12 + x 22 + t 22 + e x 02 + x 12 + t 22 + x 22 + t 22 ) \begin{aligned} TotalScore(w_0 \rightarrow w_1 \rightarrow w_2) &=\log (e^{previous[0]} + e^{previous[1]})\\ &=\log (e^{\log((e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})e^{x_{21} + t_{11}}+(e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})e^{x_{21} + t_{21}})} \\ &=\log (e^{\log((e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})e^{x_{21} + t_{11}}+(e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})e^{x_{21} + t_{21}})}+e^{\log((e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})e^{x_{22} + t_{12}}+(e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})e^{x_{22} + t_{22}})}) \\ &=\log (e^{x_{01}+x_{11}+t_{11}+x_{21}+t_{11}}+e^{x_{02}+x_{11}+t_{21}+x_{21}+t_{11}}+e^{x_{01}+x_{12}+t_{12}+x_{21}+t_{21}}+e^{x_{02}+x_{12}+t_{22}+x_{21}+t_{21}}+e^{x_{01}+x_{11}+t_{11}+x_{22}+t_{12}}+e^{x_{02}+x_{11}+t_{21}+x_{22}+t_{12}}+e^{x_{01}+x_{12}+t_{12}+x_{22}+t_{22}}+e^{x_{02}+x_{12}+t_{22}+x_{22}+t_{22}}) \end{aligned} TotalScore(w0→w1→w2)=log(eprevious[0]+eprevious[1])=log(elog((ex01+x11+t11+ex02+x11+t21)ex21+t11+(ex01+x12+t12+ex02+x12+t22)ex21+t21)=log(elog((ex01+x11+t11+ex02+x11+t21)ex21+t11+(ex01+x12+t12+ex02+x12+t22)ex21+t21)+elog((ex01+x11+t11+ex02+x11+t21)ex22+t12+(ex01+x12+t12+ex02+x12+t22)ex22+t22))=log(ex01+x11+t11+x21+t11+ex02+x11+t21+x21+t11+ex01+x12+t12+x21+t21+ex02+x12+t22+x21+t21+ex01+x11+t11+x22+t12+ex02+x11+t21+x22+t12+ex01+x12+t12+x22+t22+ex02+x12+t22+x22+t22)
我们完成了目标, log ( e S 1 + e S 2 + … + e S N ) \log(e^{S_1} + e^{S_2} + … + e^{S_N}) log(eS1+eS2+…+eSN). 在我们的小例子,一个句子中含有三个单词,我们的标签集中有两个标签。因此,共有 8 种可能的路径。
计算推理
同上,我们仍以 3 个字的句子为例, X = [ w 0 , w 1 , w 2 ] X=[w_0, w_1, w_2] X=[w0,w1,w2] ,而且通过训练后的模型,我们得到了 Emission 矩阵和 Transition 矩阵:
- Emission 矩阵:
| l 1 l_1 l1 | l 2 l_2 l2 | |
|---|---|---|
| w 0 w_0 w0 | x 01 x_{01} x01 | x 02 x_{02} x02 |
| w 1 w_1 w1 | x 11 x_{11} x11 | x 12 x_{12} x12 |
| w 2 w_2 w2 | x 21 x_{21} x21 | x 22 x_{22} x22 |
- Transition 矩阵:
| l 1 l_1 l1 | l 2 l_2 l2 | |
|---|---|---|
| l 1 l_1 l1 | t 11 t_{11} t11 | t 12 t_{12} t12 |
| l 2 l_2 l2 | t 21 t_{21} t21 | t 22 t_{22} t22 |
再次强调,上述两个表是经过训练阶段训练后的模型参数,尽管形式上与训练阶段计算所有路径总分部分一致
与训练阶段一致,我们仍需 obs 和 previous 两个变量,另外还需要 α 0 \alpha_0 α0 和 α 1 \alpha_1 α1 两个新变量,分别用于存储历史最佳分数和历史最佳分数对应的类别索引。预测的顺序依然是从 w 0 w_0 w0 开始。
w 0 w_0 w0:
o b s = [ x 01 , x 02 ] obs = [x_{01}, x_{02}] obs=[x01,x02]
p r e v i o u s = N o n e previous = None previous=None
这个的计算可以直接通过 Emission 矩阵得到,例如 o b s = [ x 01 = 0.2 , x 02 = 0.8 ] obs=[x_{01}=0.2, x_{02}=0.8] obs=[x01=0.2,x02=0.8],显然 w 0 w_0 w0 的最佳预测结果是 l 2 l_2 l2。
w 0 w_0 w0 → w 1 w_1 w1:
o b s = [ x 11 , x 12 ] obs = [x_{11}, x_{12}] obs=[x11,x12]
p r e v i o u s = [ x 01 , x 02 ] previous = [x_{01}, x_{02}] previous=[x01,x02]
用前面的方法我们可以得到 s c o r e s = ( x 01 + x 11 + t 11 x 01 + x 12 + t 12 x 02 + x 11 + t 21 x 02 + x 12 + t 22 ) scores = \begin{pmatrix} x_{01}+x_{11}+t_{11}&x_{01}+x_{12}+t_{12}\\ x_{02}+x_{11}+t_{21}&x_{02}+x_{12}+t_{22} \end{pmatrix} scores=(x01+x11+t11x02+x11+t21x01+x12+t12x02+x12+t22)
重点在于如何更新 p r e v i o u s previous previous,
p r e v i o u s = [ max ( s c o r e s [ 00 ] , s c o r e s [ 10 ] ) , max ( s c o r e s [ 01 ] , s c o r e s [ 11 ] ) ] previous=[\max (scores[00], scores[10]),\max (scores[01],scores[11])] previous=[max(scores[00],scores[10]),max(scores[01],scores[11])]
举个例子,例如: s c o r e s = ( x 01 + x 11 + t 11 x 01 + x 12 + t 12 x 02 + x 11 + t 21 x 02 + x 12 + t 22 ) = ( 0.2 0.3 0.5 0.4 ) scores = \begin{pmatrix} x_{01}+x_{11}+t_{11}&x_{01}+x_{12}+t_{12}\\ x_{02}+x_{11}+t_{21}&x_{02}+x_{12}+t_{22} \end{pmatrix}= \begin{pmatrix} 0.2&0.3\\ 0.5&0.4 \end{pmatrix} scores=(x01+x11+t11x02+x11+t21x01+x12+t12x02+x12+t22)=(0.20.50.30.4)
则: p r e v i o u s = [ max ( s c o r e s [ 00 ] , s c o r e s [ 10 ] ) , max ( s c o r e s [ 01 ] , s c o r e s [ 11 ] ) ] = [ 0.5 , 0.4 ] previous=[\max (scores[00], scores[10]),\max (scores[01],scores[11])] = [0.5, 0.4] previous=[max(scores[00],scores[10]),max(scores[01],scores[11])]=[0.5,0.4]
解释一下,我们要预测的是 w 1 w_1 w1,当 w 1 w_1 w1 被预测为 l 1 l_1 l1 时,其实一共有两个路径:
- w 0 w_0 w0 被预测为 l 1 l_1 l1(即 x 01 x_{01} x01), l 1 l_1 l1 下次可以转到 l 1 l_1 l1(即 t 11 t_{11} t11), w 1 w_1 w1 被预测为 l 1 l_1 l1
- w 0 w_0 w0 被预测为 l 2 l_2 l2(即 x 02 x_{02} x02), l 2 l_2 l2 下次可以转到 l 1 l_1 l1(即 t 21 t_{21} t21), w 1 w_1 w1 被预测为 l 1 l_1 l1
上面两个过程对应的就是 s c o r e s 00 scores_{00} scores00 和 s c o r e s 10 scores_{10} scores10 ,同理,当 w 1 w_1 w1 被预测为 l 2 l_2 l2 对应的就是 s c o r e s 01 scores_{01} scores01 和 s c o r e s 11 scores_{11} scores11
因此:
- α 0 = [ ( s c o r e s [ 10 ] , s c o r e s [ 11 ] ) ] = [ ( 0.5 , 0.4 ) ] \alpha_0=[(scores[10],scores[11])]=[(0.5,0.4)] α0=[(scores[10],scores[11])]=[(0.5,0.4)]
- α 1 = [ ( C o l u m n I n d e x ( s c o r e s [ 10 ] ) , C o l u m n I n d e x ( s c o r e s [ 11 ] ) ) ] = [ ( 1 , 1 ) ] \alpha_1=[(ColumnIndex(scores[10]),ColumnIndex(scores[11]))]=[(1,1)] α1=[(ColumnIndex(scores[10]),ColumnIndex(scores[11]))]=[(1,1)]
上式中, α 1 \alpha_1 α1 最后的 [ ( 1 , 1 ) ] [(1,1)] [(1,1)] 表示的是标签的索引,即 ( 1 , 1 ) = ( l 2 , l 2 ) (1,1)=(l_2, l_2) (1,1)=(l2,l2),即 ( l 2 → l 1 ) = 0.5 , ( l 2 → l 2 ) = 0.4 (l_2 \to l_1)=0.5, (l_2 \to l_2)=0.4 (l2→l1)=0.5,(l2→l2)=0.4
w 0 w_0 w0 → w 1 w_1 w1 → w 2 w_2 w2:
o b s = [ x 21 , x 22 ] obs = [x_{21}, x_{22}] obs=[x21,x22]
p r e v i o u s = [ 0.5 , 0.4 ] previous=[0.5, 0.4] previous=[0.5,0.4]
计算 scores,并假设计算结果为:
s c o r e s = ( 0.5 + x 21 + t 11 0.5 + x 22 + t 12 0.4 + x 21 + t 21 0.4 + x 22 + t 22 ) = ( 0.6 0.9 ‾ 0.8 ‾ 0.7 ) scores = \begin{pmatrix} 0.5+x_{21}+t_{11}&0.5+x_{22}+t_{12}\\ 0.4+x_{21}+t_{21}&0.4+x_{22}+t_{22} \end{pmatrix}=\begin{pmatrix}0.6&\underline{0.9}\\\underline{0.8}&0.7\end{pmatrix} scores=(0.5+x21+t110.4+x21+t210.5+x22+t120.4+x22+t22)=(0.60.80.90.7)
再次更新:
- p r e v i o u s = [ 0.8 , 0.9 ] previous=[0.8,0.9] previous=[0.8,0.9]
- α 0 = [ ( 0.5 , 0.4 ) , ( 0.8 , 0.9 ) ‾ ] \alpha_0=[(0.5,0.4),\underline{(0.8,0.9)}] α0=[(0.5,0.4),(0.8,0.9)]
- α 1 = [ ( 1 , 1 ) , ( 1 , 0 ) ‾ ] \alpha_1=[(1,1),\underline{(1,0)}] α1=[(1,1),(1,0)]
预测:
根据 α 0 \alpha_0 α0 和 α 1 \alpha_1 α1 我们选择最佳路径,首先是 α 0 \alpha_0 α0 ,最后一个字的标签得分分别是 0.8 和 0.9,我们选择 0.9,也就是最后一个字被预测为 l 2 l_2 l2, α 0 \alpha_0 α0 中 0.9 的位置对应 α 1 \alpha_1 α1 中的 0,即前一个字的标签是 l 1 l_1 l1,继续往前推,前一个个字的标签是 l 2 l_2 l2。所以预测的最佳路径是 l 2 → l 1 → l 2 l_2 \to l_1 \to l_2 l2→l1→l2。















 8206
8206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









