







数据库数据:226万
导出10万条数据,每条数据50个字段:导出时间13秒左右
一,所用技术
EasyExcel,
线程池
ThreadPoolExecutor
,原子类
AtomicInteger
,阻塞队列,
Mysql
索引
二,设计方案
2.1
,
EasyExcel
是一个基于
Java
的、快速、简洁、解决大文件内存溢出的
Excel
处理工具。
他能让你在不用考虑性能、内存的等因素的情况下,快速完成
Excel
的读、写等功能。
2.2
,
Mysql
查询优化
2.3
,并发查询设计
2.4
,读写分离设计(数据读取和数据写入
EXCEL
并发进行)
三,详细说明
3.1,Mysql 查询优化
1.1
需要时间查询增加时间的索引

1.2
数据量大需要分页查询,分页查询页数越大会查询越慢
分页查询时,可以通过子查询单独查询出主键
ID
字段,由于主键
ID
加了索引,查询速度会
非常快,再通过子查询继续查询出其他需要的字段
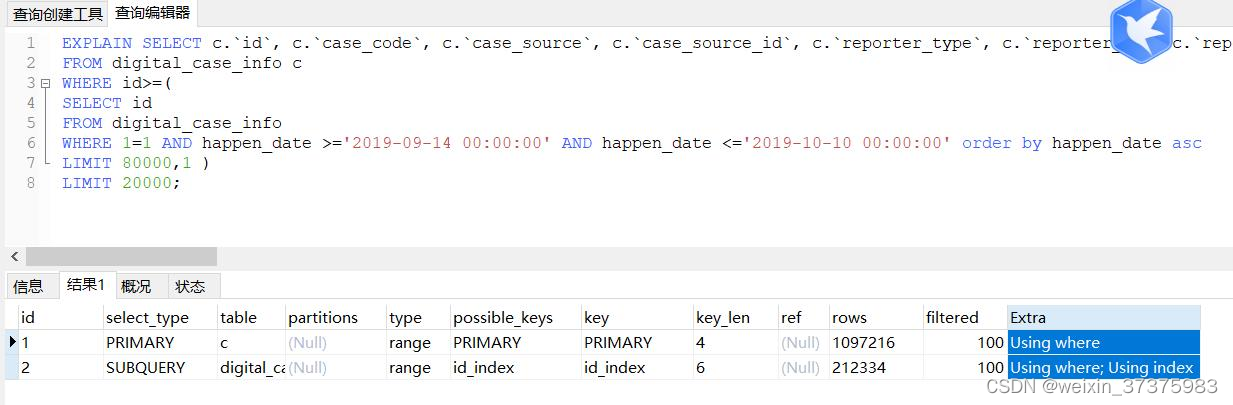
SELECT ..........
FROM digital_case_info c
WHERE id>=(
SELECT id
FROM digital_case_info
WHERE 1=1 AND happen_date >='2019-09-14 00:00:00' AND happen_date <='2019-10-10
00:00:00' order by happen_date asc LIMIT 80000,1
)
LIMIT 20000;
耗时:

索引使用情况:
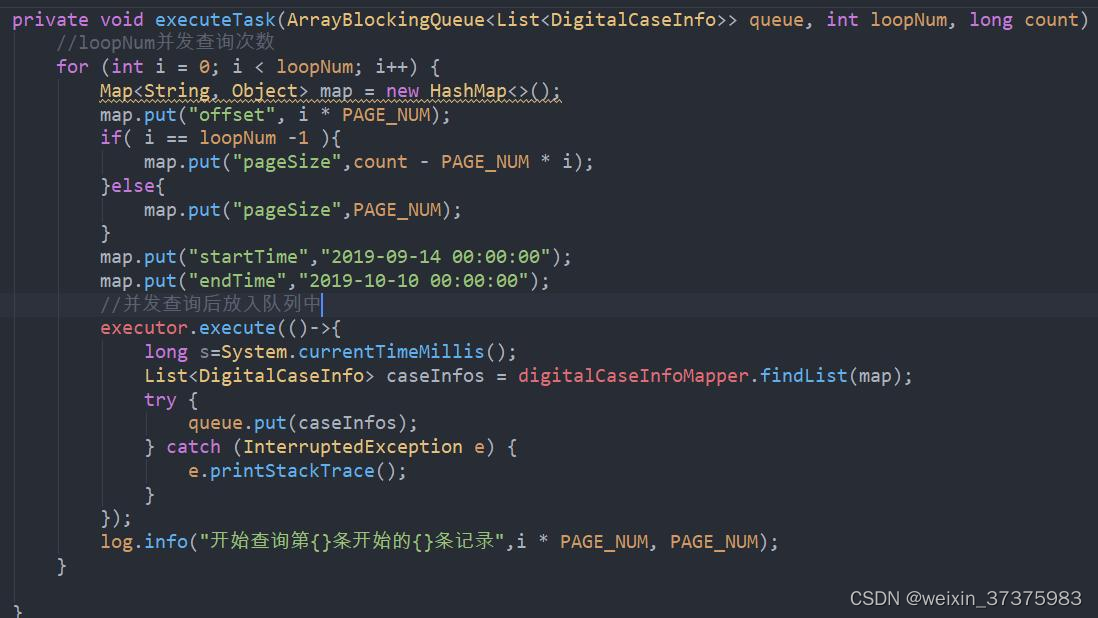
3.2,并发查询设计
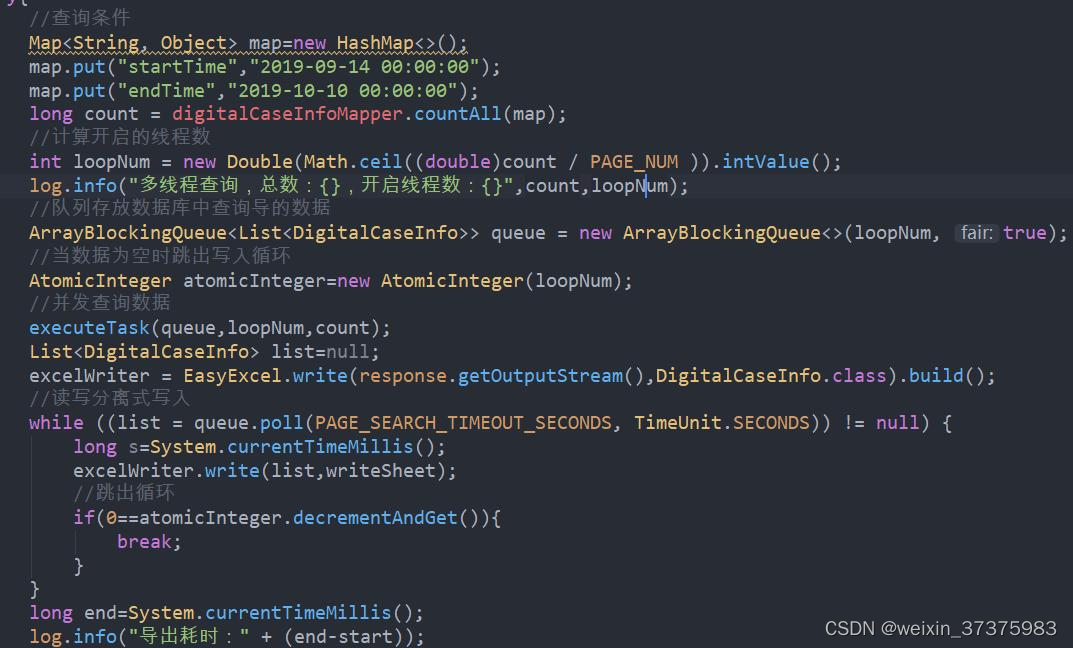
3.3,读写分离设计
通过定义一个阻塞队列,在主线程中新起多个线程用于查询
([
并发
]
查询时将查询结果放入队列
中
)
,写入时直接从队列中进行获取待写入数据,实现读写分离和降低写入时等待查询数据的时间, 从而降低总体用时。
四,最终源码
@Autowired
private DigitalCaseInfoMapper digitalCaseInfoMapper;
@Resource
private ThreadPoolExecutor executor;
/**
* 每个线程查询的页数
*/
private static final int PAGE_NUM = 20000;
/**
* 阻塞队列获取数据超时时间
*/
private static final Integer PAGE_SEARCH_TIMEOUT_SECONDS = 60;
@Override
public void export(HttpServletResponse response) {
log.info("sql分页导出excel....");
long start=System.currentTimeMillis();
//定义easyExcel导出的对象
ExcelWriter excelWriter = null;
response.setContentType("application/vnd.ms-excel");
response.setCharacterEncoding("utf-8");
response.setHeader("Content-disposition", "attachment;filename=demo.xlsx");
WriteSheet writeSheet = EasyExcel.writerSheet("sheet1").build();
try{
//查询条件
Map<String, Object> map=new HashMap<>();
map.put("startTime","2019-09-14 00:00:00");
map.put("endTime","2019-10-10 00:00:00");
//获取总数
long count = digitalCaseInfoMapper.countAll(map);
//计算开启的线程数
int loopNum = new Double(Math.ceil((double)count / PAGE_NUM )).intValue();
log.info("多线程查询,总数:{},开启线程数:{}",count,loopNum);
//队列存放数据库中查询导的数据
ArrayBlockingQueue<List<DigitalCaseInfo>> queue = new ArrayBlockingQueue<>(loopNum, true);
//当数据为空时跳出写入循环
AtomicInteger atomicInteger=new AtomicInteger(loopNum);
//并发查询数据
executeTask(queue,loopNum,count);
List<DigitalCaseInfo> list=null;
excelWriter = EasyExcel.write(response.getOutputStream(),DigitalCaseInfo.class).build();
//读写分离式写入
while ((list = queue.poll(PAGE_SEARCH_TIMEOUT_SECONDS, TimeUnit.SECONDS)) != null) {
excelWriter.write(list,writeSheet);
//跳出循环
if(0==atomicInteger.decrementAndGet()){
break;
}
}
long end=System.currentTimeMillis();
log.info("导出耗时:" + (end-start));
}catch (Exception e){
log.debug("文件导出报错,{}",e.getMessage());
}finally {
if(excelWriter != null ){
excelWriter.finish();
}
}
}
/**
* 并发查询数据库
* @param queue 存放数据队列
* @param loopNum 查询次数
* @param count 总数
*/
private void executeTask(ArrayBlockingQueue<List<DigitalCaseInfo>> queue, int loopNum, long count) {
//loopNum并发查询次数
for (int i = 0; i < loopNum; i++) {
Map<String, Object> map = new HashMap<>();
map.put("offset", i * PAGE_NUM);
if( i == loopNum -1 ){
map.put("pageSize",count - PAGE_NUM * i);
}else{
map.put("pageSize",PAGE_NUM);
}
map.put("startTime","2019-09-14 00:00:00");
map.put("endTime","2019-10-10 00:00:00");
//并发查询后放入队列中
executor.execute(()->{
long s=System.currentTimeMillis();
List<DigitalCaseInfo> caseInfos = digitalCaseInfoMapper.findList(map);
try {
queue.put(caseInfos);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
log.info("开始查询第{}条开始的{}条记录",i * PAGE_NUM, PAGE_NUM);
}
}














 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









