







1. Active-Dormant Attention Heads_ Mechanistically Demystifying Extreme-Token Phenomena in LLMs
1.1研究背景
本论文探讨了基于Transformer的大语言模型(LLMS)中观察到一些令人困惑的现象,统称为extreme-token 现象。这些现象包括注意力汇聚、值状态流失和残差状态峰值,对于LLMs的推理量化和可解释性带来了挑战。该论文的主要目标是阐明这些extreme-token现象背后的机制,并提出在预训练期间减轻这些现象的策略。
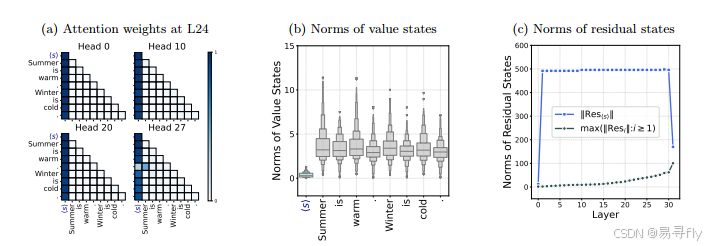
- 注意力汇聚(Attention Sinks):在许多注意力头中,initial token(如序列开始的token)持续吸引大部分注意力权重,而其他特殊token(如分隔符)也能吸引显著的注意力权重。这些token就被称为sink token。
- 值状态流失(Value-State Drains):对于表现出Attention sinks的注意力头,sink tokens的状态值显著小于其他token。
- 残差状态峰值(Residual-State Peaks):除了第一层和最后一层外,sink tokens 的残差状态的范数明显大于其他token
1.2 主要内容
- 简化任务分析:作者在简单的Bigram-Backcopy 上训练了一层到3层的Transformer,展示了这些模型也会出现类似于大型语言模型中的极端标记现象。
- 理论分析:通过理论分析,作者揭示了extreme-token 现象背后的机制,包括注意力头的主动-休眠机制和相互加强机制。这些机制解释了attention sinks和value-state drains是如何在训练过程中相互促进的。
-
预训练语言模型分析:作者将分析扩展到预训练的LLMs,包括Llama和OLMo,发现这些模型中的许多注意力头也表现出类似的主动-休眠机制,并且相互加强机制也支配着extreme-token现象的出现。
-
解决方案提出:基于对extreme-token现象背后机制的理解,作者提出了一些减轻这些现象的策略,包括在注意力头中用ReLU替换SoftMax激活函数,以及将Adam优化器替换为SGD。
-
实验验证:通过在BB任务和预训练的LLMs上的实验,作者验证了理论分析的预测,并展示了提出的策略可以有效减轻极端标记现象。
2. L3Ms -- Lagrange Large Language Models
2.1 研究背景
这篇论文试图解决的问题是如何在对大型语言模型(LLMs)进行监督式微调(SFT)和对齐(alignment)的过程中,将这些步骤作为一个受约束的优化问题来处理。具体来说,论文旨在在微调LLMs以最小化任务困惑度(perplexity)的同时,满足特定应用的需求和约束,而不是依赖于启发式的方法来驱动优化。这种方法允许为不同的应用定制LLMs,同时避免了启发式驱动过程,并保持了在原始任务上的性能。
2.2 主要内容
论文通过以下几个步骤解决大型语言模型(LLMs)的监督式微调(SFT)和对齐问题
- 将SFT和对齐表述为受约束的优化问题:论文将SFT和对齐合并为一个受约束的优化问题,其中LLM被微调以最小化任务困惑度(perplexity),同时满足应用特定的最低要求(约束)。
- 提出Lagrange Large Language Models (L3Ms):为了解决这种受约束的优化问题,论文提出了L3Ms,即拉格朗日大型语言模型。L3Ms通过使用对数障碍函数(logarithmic barriers)来逐渐强化约束,避免了启发式过程。
- 使用对数障碍函数:采用对数障碍函数来强制执行约束,将它们添加到目标函数中,从而将受约束的问题转化为不受约束的问题。参数μ控制约束的强度。
- 迭代优化过程:提出了一个迭代过程,其中固定μ的最小化解被找到,μ被减少,并重复此过程。这种方法逐渐引导LLM满足约束,同时避免了不稳定性。
- 实验验证:通过实验验证了L3Ms在满足定制约束和任务困惑度目标方面的有效性。实验结果表明,L3Ms可以根据不同的偏好定制,同时保持对原始任务的性能
- 实施细节:提供了一些实施细节,包括交替目标和梯度裁剪、长度归一化、估计平均偏好奖励等,以确保大型模型的稳定训练。
通过这些步骤,论文展示了如何定制LLMs以适应不同的应用需求,同时避免了启发式方法,并保持了在原始任务上的性能。
3. LDAdam_ Adaptive Optimization from Low-Dimensional Gradient Statistics
3.1 研究背景
这篇论文介绍了一种名为LDAdam的新型内存高效优化器,旨在解决在训练大型模型时内存和计算需求不断增加的问题。具体来说,论文关注于优化器状态的内存成本,即在自适应优化过程中所需的额外的一阶和二阶梯度统计量,对于基线算法Adam来说,其大小可达模型大小的两倍。
论文的主要目标是在显著减少内存占用的同时,复制Adam的性能和理论保证。作者观察到深度网络的优化景观具有低内在维度,因此提出了LDAdam,这是一种在低维子空间内执行自适应优化步骤的优化器,同时在训练过程中始终探索完整的参数空间。LDAdam通过一种新的投影感知更新规则和一种新的广义错误反馈机制来实现这一目标,这些机制允许在子空间之间转换,并显式考虑了梯度和优化器状态的压缩。论文还证明了LDAdam在标准假设下的收敛性,并通过实验验证了其在训练效率方面的优势。
3.2 相关研究
根据论文内容,相关研究包括以下几个领域:
-
内存高效的一阶优化方法:研究了如何使用梯度统计量来确定下降方向并为每个参数调整学习率。Adam算法结合了这些想法,并提供了偏差校正的设计。此外,还有对Adam/AdamW内存占用进行优化的扩展,例如Adafactor、CAME和Adam-mini,这些方法通过分解二阶统计量来减少内存占用。还有通过量化优化器状态来减少内存占用的方法。
-
分布式优化中的错误反馈:在分布式优化领域,提出了多种减少通信开销的方法,包括量化、稀疏化和低秩近似。错误反馈机制被证明可以改善压缩梯度方法的实验性能,并确保它们的收敛性。
-
参数高效微调(PEFT):为了减少内存开销,提出了只训练较少参数的方法。这导致了加性PEFT、选择性PEFT和重参数化PEFT等方法的发展,这些方法通过在模型架构中添加新的可训练模块或仅重新训练原始模型的某些参数来实现。
-
通过低秩梯度投影进行优化:GaLore算法通过定期更新低维子空间来进行自适应优化。该算法使用SVD获得的低秩梯度表示来节省内存,并产生下降方向的低秩表示,然后将其上投影以更新模型参数。
3.3 主要内容
论文通过提出LDAdam(Low-Dimensional Adam)算法解决了大型模型训练中的内存效率问题。LDAdam算法的核心思想是在低维子空间内执行自适应优化步骤,同时在训练过程中始终探索完整的参数空间。下面是该算法解决该问题的几个关键技术点:
-
投影感知更新规则:LDAdam引入了一种新的更新规则,允许优化器状态在不同子空间之间转换,即估计投影梯度的统计量。这种规则使得优化步骤能够从投影感知的中间优化器状态和投影梯度中执行,而不是从上一次迭代的优化器状态和全秩梯度中执行。
-
低秩压缩:LDAdam利用块幂迭代(Block Power Iteration)在每一步高效且准确地投影梯度和优化器状态。这种方法避免了在每一步进行奇异值分解(SVD)的高计算成本,同时实现了对最重要奇异向量的紧密近似。
-
广义错误反馈机制:为了减轻由于低秩投影造成的错误,LDAdam集成了一种新的广义错误反馈机制。这种机制显式考虑了梯度和优化器状态压缩,并通过在错误缓冲区中重新引入丢失的信息来校正梯度和优化器状态。
-
内存效率:LDAdam的优化器状态内存占用仅为模型大小的一小部分。对于形状为n×mn×m的权重层,LDAdam的优化器状态空间成本为nr+2rmnr+2rm,其中rr是投影秩,而Adam的状态成本为2nm2nm。这使得LDAdam在内存使用上与流行的GaLore算法相当,并且通常r≪min(m,n)r≪min(m,n),因此在实践中可以带来显著的内存节省。
-
理论保证:论文还证明了LDAdam在标准假设下的收敛性,并展示了它在训练效率方面的实证证据。对于光滑的非凸目标,LDAdam可以保持AMSGrad(Adam的可证明收敛版本)的渐近收敛速率,并且在满足Polyak-Łojasiewicz条件的目标上展示了更快的速率。
通过这些技术,LDAdam能够在显著减少内存占用的同时,提供与Adam相当的性能和理论保证,从而有效地解决了大型模型训练中的内存效率问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









