







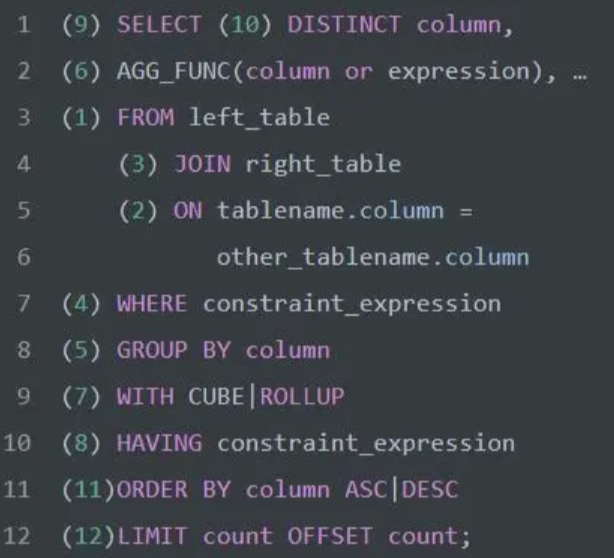
高频 SQL 50 题(基础版)刷题攻略(上篇)
简介
刷题网址:高频 SQL 50 题(基础版) - 学习计划 - 力扣(LeetCode)全球极客挚爱的技术成长平台
上篇网址:Leetcode SQL 50题刷题攻略(上篇)-CSDN博客
正文开始
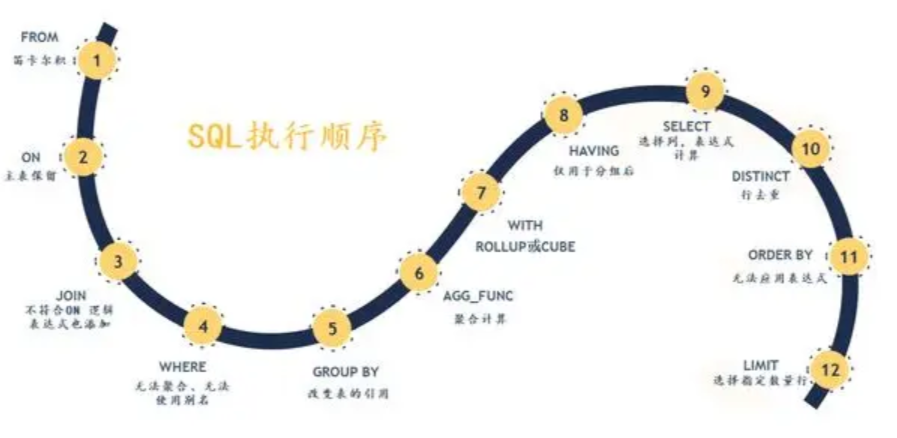
1789.员工的直属部门
select employee_id,department_id from (select employee_id,count(employee_id) as n,department_id from Employee group by employee_id) t where n=1
union
select employee_id,department_id from Employee where primary_flag = 'Y'
-
union的用法
第一个select语句
select employee_id,department_id from (select employee_id,count(employee_id) as n,department_id from Employee group by employee_id) t where n=1的结果:employee_id department_id 1 1 3 3 第二个select语句
select employee_id,department_id from Employee where primary_flag = 'Y'的结果:employee_id department_id 2 1 4 3 通过union语句即
SELECT column_a FROM table_a UNION SELECT column_b FROM table_b;合并的结果如下:employee_id department_id 1 1 3 3 2 1 4 3 需要注意的是,使用UNION操作符合并列时,两个表的列数和数据类型必须相同。
180.连续出现的数字


select distinct l1.num as ConsecutiveNums from Logs l1 left join Logs l2 on l1.id=l2.id+1 left join Logs l3 on l1.id=l3.id+2 where l1.num is not null and l1.num=l2.num and l1.num=l3.num
- 很有意思的一道题,如何破解连续与计数的方式
1204.最后一个能进入巴士的人
select person_name from
(select person_id,person_name,sum(weight) over (order by turn) as sum_weight,turn from Queue order by turn) t where t.sum_weight<=1000 ORDER BY turn DESC
LIMIT 1
-
计算累计和
原始数据:
person_id person_name weight turn 5 Alice 250 1 4 Bob 175 5 3 Alex 350 2 6 John Cena 400 3 1 Winston 500 6 2 Marie 200 4 使用sum(…) over (order by …)来计算累加和
select person_id,person_name,sum(weight) over (order by turn) as sum_weight,turn from Queue order by turn的结果:person_id person_name sum_weight turn 5 Alice 250 1 3 Alex 600 2 6 John Cena 1000 3 2 Marie 1200 4 4 Bob 1375 5 1 Winston 1875 6 即按turn的次序累加weight为sum_weight
-
读取最后一行,使用
ORDER BY turn DESC与LIMIT 1配合获取turn倒数第一行
1978.上级经理已离职的公司员工
select employee_id from Employees where salary < 30000 and manager_id not in
(select employee_id from Employees) order by employee_id
- 如何查找一个经理id与所有的员工的id都不一样,即查找一个值与某一列都不一样,使用
not in (select employee_id from Employees)来解决,也即SELECT * FROM table1 WHERE id NOT IN (SELECT id FROM table2)
626.换座位
SELECT
case when id=(select max(id) from Seat) and id%2=1 then id
when id%2=1 then id+1
when id%2=0 then id-1
end as id,
student
FROM Seat order by id;
-
查询子表使用
XXX=(select...)的方式来查询SELECT column_name [, column_name ] FROM table1 [, table2 ] WHERE column_name OPERATOR (SELECT column_name [, column_name ] FROM table1 [, table2 ] [WHERE]) -
使用case与when以及end来条件判断,免得使用union的连接操作:
case when id=(select max(id) from Seat) and id%2=1 then id when id%2=1 then id+1 when id%2=0 then id-1 end as id也即:
CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 ... ELSE resultN END
1341.电影评分
(select name as results from MovieRating m left join Users u on m.user_id=u.user_id group by m.user_id order by count(m.user_id) desc,name asc limit 1)
union all
(select title as results from MovieRating mr left join Movies m on mr.movie_id=m.movie_id where created_at>='2020-02-01' and created_at<='2020-02-29' group by mr.movie_id order by sum(rating)/count(rating) desc,title asc limit 1)
-
union会去掉重复项,union all不会
比如union会返回:
results Rebecca 而union all会返回:
results Rebecca Rebecca -
order by可以使用sum,count等函数,结果可以不返回,排序的时候可以根据这些排序
1321.餐馆营业额变化增长
# 方式1,使用窗口函数
select visited_on,amount,round(amount/7,2) as average_amount from
(select max(visited_on) over (rows between 6 PRECEDING AND CURRENT ROW) as visited_on,sum(amount) over (rows between 6 PRECEDING AND CURRENT ROW) as amount from
(select visited_on,sum(amount) as amount from Customer group by visited_on) t) t1
having visited_on>=(select visited_on from Customer group by visited_on limit 6,1)
# 方式2,使用window子句
select visited_on,amount,round(amount/7,2) as average_amount from
(
select max(visited_on) over s as visited_on,sum(amount) over s as amount from
(select visited_on,sum(amount) as amount from Customer group by visited_on) t
window s as (rows between 6 PRECEDING AND CURRENT ROW)
) t1
having visited_on>=(select visited_on from Customer group by visited_on limit 6,1)
-
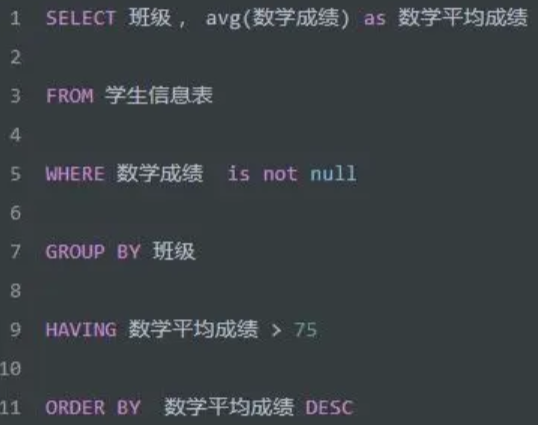
通过上图可以得出一个伪SQL查询语句
!重点,where与having的作用是相同的,但是由于作用的时间段不一样,会导致having可以针对聚合计算结束的内容来进行判断,如下所示,having可以针对数学平均乘积筛选,而where是不能的,其只能针对原始数据筛选
-
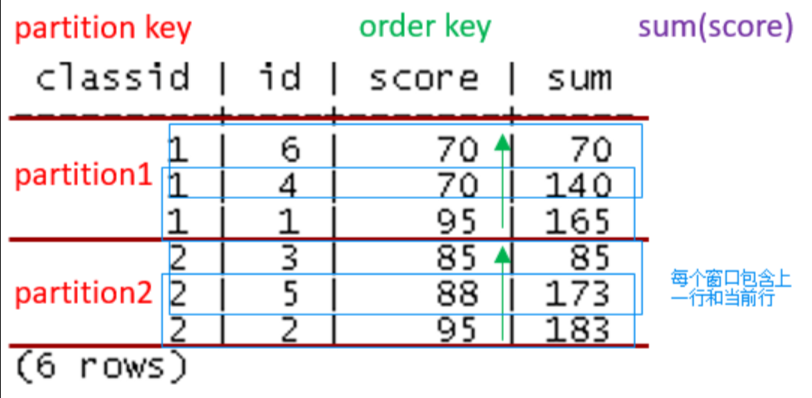
sql操作的窗口函数
窗口函数(Window Function),又被叫做分析函数(Analytics Function),通常在需要对数据进行分组汇总计算时使用,因此与聚集函数有一定的相似性。但与聚集函数不同的是,聚集函数通过对数据进行分组,仅能够输出分组汇总结果,而原始数据则无法展现在结果中。而窗口函数则可以同时将原始数据和聚集分析结果同时显示出来
常见的形式如
SUM(SCORE) OVER (PARTITION BY CLASSID ORDER BY SCORE ROWS BETWEEN 1 PRECEDING AND CURRENT ROW),即上面一些题,用到了over啥的都是窗口函数PARTITION BY CLASSID意思是先按CLASSID分为很多大划分
ORDER BY SCORE意思是在每个大划分下进行按照列SCORE来排序
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW意思是排序完成后,在每个大划分中进行,按照当前行与当前行前一行为一个窗口来进行小划分
针对每个小划分来进行SUM(SCORE)操作
具体如下图所示
其中最后小划分的方式有如下格式
RANGE|ROWS [BETWEEN] <rows_loc> [AND <rows_loc>] 或 RANGE|ROWS <rows_loc>中间的
<rows_loc>可以为- UNBOUNDED PRECEDING表示该大划分的第一行
- UNBOUNDED FOLLOWING表示该大划分的最后一行
- CURRENT ROW表示当前行
- PRECEDING表示从当前行往前数数量的行,其中不能包含变量,RANGE选项禁用
- FOLLOWING表示从当前行往后数数量的行,其中不能包含变量,RANGE选项禁用
举例:
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 以该分组(也即大划分)所有元组为窗口
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 以该分组起始行到当前行为窗口
ROWS BETWEEN 10 PRECEDING AND 5 FOLLOWING 以该分组当前行前10行到后5行为窗口(不能超过起始行和结束行)
-
窗口函数的window子句
有时,一个查询会出现多个窗口函数,而内容还相同,那么可以使用window子句了,即使用一个
window s as (rows between 6 PRECEDING AND CURRENT ROW),然后其余要用到窗口函数的直接over s即可 -
limit的新用法
limit n offset m表示从第m+1行开始读取n行,简单的写法可以写为limit m,n
585.2016年的投资
SELECT
*
FROM
insurance
WHERE
insurance.TIV_2015 IN
(
SELECT
TIV_2015
FROM
insurance
GROUP BY TIV_2015
HAVING COUNT(*) > 1
)
AND CONCAT(LAT, LON) IN
(
SELECT
CONCAT(LAT, LON)
FROM
insurance
GROUP BY LAT , LON
HAVING COUNT(*) = 1
)
;
- having后可以接聚合函数,作用域上面一道题已经显示了having的运行位置
- concat函数用于连接两个字符串形成一个字符串
185.部门工资前三高的所有员工
select d.name as Department, e.name as Employee, e.salary as Salary
from Employee e
left join
(select *
from (select departmentId,
salary,
ROW_NUMBER() OVER (PARTITION BY departmentId ORDER BY salary DESC) AS rn
FROM (select distinct departmentId,
salary
from Employee) as t1) as t2
where rn <= 3) t3
on e.departmentId = t3.departmentId and e.salary = t3.salary
left join
Department d
on e.departmentId = d.id
where t3.departmentId is not null
-
如何将每个部门分开并且求每个部门的前三高的工资是多少,分为两步:
-
第一步将每个部门相同的薪水去掉
select distinct departmentId,salary from Employee结果如下:
departmentId salary 1 85000 2 80000 2 60000 1 90000 1 69000 1 70000 -
第二部使用聚合函数中的ROW_NUMBER与窗口函数来分组标号
select departmentId, salary, ROW_NUMBER() OVER (PARTITION BY departmentId ORDER BY salary DESC) AS rn FROM (select distinct departmentId, salary from Employee) as t1结果如下:
departmentId salary rn 1 90000 1 1 85000 2 1 70000 3 1 69000 4 2 80000 1 2 60000 2 即按departmentId分组,每组按salary倒序,然后每组进行标号操作,标号操作后作为rn列
-
最后一个就是再套一个select取rn小于等于3的即可
-
1667.修复表中的名字
select user_id,concat(upper(left(name,1)),lower(substring(name, 2))) as name from Users order by user_id
-
mysql字符串截取常用函数有
-
left(str,length)
从左边第一位开始截取指定长度字符串
-
right(str,length)
从右边第一位开始截取指定长度字符串
-
substring(str,index,length)
从指定开始位置截取指定长度字符串,如果不给length那么就从index截取后面全部长度,index可以为负数,负数就是相对于右边第一位的偏移
-
substr与mid函数的功能与substring类似
-
substring_index(str,dim,length)
从指定字符位置开始截取指定长度字符串。
length可正可负,若正那么就是相对于左边第length个dim,若负就是相对于右边第length个dim。正的取dim前所有字符串,负数取dim后所有字符串
若找不到dim那么返回所有字符串
-
-
upper是字符串变大写,lower是字符串变小写
-
concat是连接两个字符串操作
1527.患某种疾病的患者
select * from Patients p where p.conditions REGEXP '\\bDIAB1.*'
-
mysql正则表达式使用
p.conditions REGEXP '\\bDIAB1.*'即匹配了\bDIAB1.*的字符串都会被查询出,注意\b需要使用\\b才行\b是匹配一个单词边界\B是匹配一个非单词边界\w是匹配一个字母、数字或下划线。等价于 [A-Za-z0-9_].表示匹配除换行符 \n 之外的任何单字符*表示零次或多次.*在一起就表示任意字符出现零次或多次
196.删除重复的电子邮箱
DELETE
FROM
Person
WHERE
id NOT IN
(SELECT
tmp.mid
FROM
(
SELECT
MIN(id) mid
FROM
Person
GROUP BY
email
) tmp
)
- 只保留重复数据id小的一个项,那么可以使用这个方法,即先分组求id最小,然后只删除不在这些id中的项即可
1484.按日期分组销售产品
select sell_date, count(sell_date) as num_sold,group_concat(product order by product) as products
from (select distinct sell_date, product from Activities) t
group by sell_date
-
group_concat与group by搭配使用,并且其内部能搭配使用order by
sell_date product 2020-05-30 Headphone 2020-06-01 Pencil 2020-06-02 Mask 2020-05-30 Basketball 2020-06-01 Bible 2020-06-02 Mask 2020-05-30 T-Shirt 第一步去掉重复项,使用distinct即
select distinct sell_date, product from Activitiessell_date product 2020-05-30 Headphone 2020-06-01 Pencil 2020-06-02 Mask 2020-05-30 Basketball 2020-06-01 Bible 2020-05-30 T-Shirt 第二步分组,使用count与group_concat,group_concat会自动使用逗号来连接,即可得到答案
sell_date num_sold products 2020-05-30 3 Basketball,Headphone,T-Shirt 2020-06-01 2 Bible,Pencil 2020-06-02 1 Mask
1327.列出指定时间段内所有的下单产品
select p.product_name, sum_unit as unit
from Products p
left join
(select product_id, order_date, sum(unit) as sum_unit
from Orders
where DATE_FORMAT(order_date, "%m") = 2
group by DATE_FORMAT(order_date, "%Y年%m月"), product_id
having sum_unit >= 100) t on p.product_id = t.product_id
where t.product_id is not null
- 可以使用
where DATE_FORMAT(order_date, "%m") = 2的方式将月份为2的找出来
1517.查找拥有有效邮箱的用户
select * from Users where mail regexp "^[a-zA-Z]+[\\w|\\-|\\.]*@leetcode\\.com"
- 在mysql中使用正则表达式要使用
\\来表示\即上面的^[a-zA-Z]+[\\w|\\-|\\.]*@leetcode\\.com实际正则表达式是^[a-zA-Z]+[\w|\-|\.]*@leetcode\.com ^表示正则表达式的其实位置,如果不加这个那么.shapo@leetcode.com也会被匹配















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











