







 本文深入探讨了Spark中DAG(有向无环图)的生成过程与State的划分,详细解释了RDD间的窄依赖与宽依赖关系,以及它们如何影响任务的执行流程。通过了解Spark的DAG和Task机制,读者可以更好地优化Spark作业,提升大数据处理效率。
本文深入探讨了Spark中DAG(有向无环图)的生成过程与State的划分,详细解释了RDD间的窄依赖与宽依赖关系,以及它们如何影响任务的执行流程。通过了解Spark的DAG和Task机制,读者可以更好地优化Spark作业,提升大数据处理效率。
目录
DAG是什么
如果一个有向图无法从任意顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。Spark的计算过程,很多时候都有先后顺序,受制于某些任务必须比另一些任务较早执行的限制,必须对任务进行排队,形成一个队列的任务集合,这个队列的任务集合就是DAG图。每一个定点就是一个任务,每一条边代表一种限制约束(Spark中的依赖关系)。
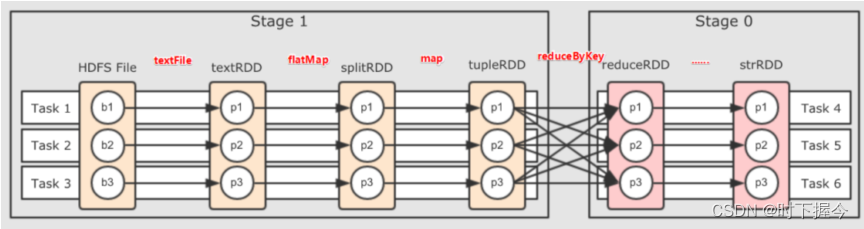
Spark中DAG生成过程的重点是对Stage的划分,Stage的划分依赖RDD宽窄依赖,当Driver程序提交后,Spark调度器将所有的RDD看成是一个Stage,然后对此Stage进行从后往前的回溯,遇到Shuffle就断开,形成一个新的State,遇到窄依赖,则归并到同一个Stage。等到所有的步骤回溯完成,便生成一个DAG图
RDD间存在什么样的依赖关系
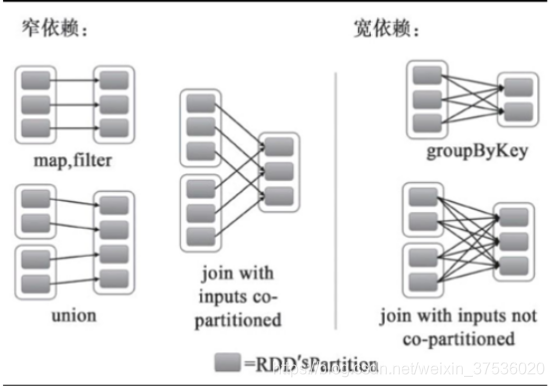
RDD之间的依赖关系分为窄依赖和宽依赖
窄依赖:父分区和子分区存在一对一的关系,比如:map 、filter、union函数。不会引入Shuffle的概念,不会发生磁盘IO读写。DAG连续多个窄依赖,会放到到同一台机器的内存中完成。
宽依赖:父分区和子分区存在多对多的关系,比如groupBy、sortByKey等带分组功能的一些懒加载函数。引入了Shuffle的概念,会发生磁盘IO读写。宽依赖数据丢失时,可以从Shuffle临时文件恢复数据
DAG的State是什么
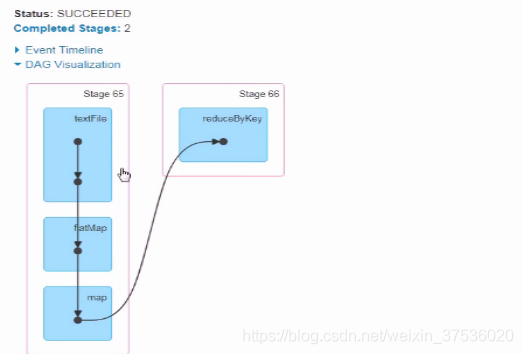
Spark执行JOB任务(一个Action操作对应一个JOB任务),根据依赖关系,将DAG划分为不同的阶段。下面是划分流程
- Spark在执行Transformation类型操作时,都不会立即执行,而是懒计算
- 执行若干步Transformation类型操作后,一旦遇到Action操作,才会真正触发计算
- 划分时,从当前Action往前回溯,如果遇到的是窄依赖则应用流水线优化(即连续的多个窄依赖会放到一起执行),继续往前找,直到遇到一个宽依赖
- 宽依赖要进行Shuffle,不执行流水线优化,所以将这一阶段执行过程组装为一个State
- 再从当前宽依赖开始向前找,重复刚才的步骤,从而将整个DAG划分为若干State
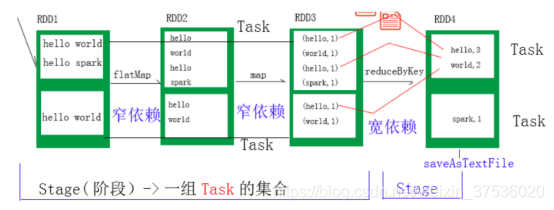
Task:对应宽依赖中的一个分区,或者窄依赖中的一个平行流水线。一个Task由一个线程运行。流水线内的多个平行分区可以并行执行
上图存在RDD1->RDD3的两个Task(流水线优化成了2个Task)和RDD4的两个Task,总共4个Task

















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









