







精确的说话人分类(Speaker Diarization)与监督学习
原文网址:https://ai.googleblog.com/2018/11/accurate-online-speaker-diarization.html
作者:Chong Wang,Reseach Scientist, Google AI; 发布时间:2018.11.12
说话人分类是语音识别系统的一个重要组成部分,它是将一个由多人组成的音频流划分为与每个人相关的同质段的过程。通过解决说话者何时说话的问题,说话人分类在许多重要场景中都有应用,比如理解医学对话、视频字幕等等。然而,与标准的监督分类任务不同,使用监督学习方法训练这些系统是具有挑战性的,一个鲁棒的分类模型需要能够将新的个体与不同的语音片段联系起来,而这些语音片段并没有参与训练。重要的是,这限制了在线和离线分类系统的质量。在线系统通常遭受的损失更大,因为它们需要实时的分类结果。

在全监督说话人分类 [ 1 ] ^{[1]} [1]中,我们描述了一个新的模型,该模型寻求以更有效的方式使用监督说话人标签。这里充分说明说话人分类系统中的所有组件,包括对扬声器数量的估计,都是在监督的方式下进行训练的,因此可以从增加可用的标记数据量中获益。在NIST SRE 2000 CALLHOME [ 2 ] ^{[2]} [2]基准测试中,我们的分类错误率(DER)低至7.6%,而之前基于聚类的方法 [ 3 ] ^{[3]} [3]和深度神经网络嵌入方法 [ 4 ] ^{[4]} [4]的分类错误率(DER)分别为8.8%和9.9%。此外,我们的方法基于在线解码实现了较低的误码率,特别适合于实时应用。因此,我们在论文中开放了核心算法的源代码 [ 5 ] ^{[5]} [5],以加速这方面的更多研究。
聚类与交织状态RNN(Clustering versus Interleaved-state RNN)
现代说话人分类系统通常基于k均值或谱聚类等聚类算法。由于这些聚类方法是无监督的,不能很好地利用数据中的监督说话人标签。此外,在线聚类算法在音频输入流的实时分类应用中通常质量较差。该模型与常用的聚类算法的关键区别在于,该方法采用参数共享递归神经网络(RNN)对所有的说话人嵌入进行建模,并利用不同的RNN状态在时域内交错区分不同的说话人。
要理解这是如何工作的,考虑下面的例子,其中有四种可能的说话者:蓝色、黄色、粉色和绿色(这是任意的,事实上,我们的模型可能使用更多的中餐馆流程 [ 6 ] ^{[6]} [6]来容纳未知数量的说话者)。每个说话人从它自己的RNN实例开始(所有说话人共享一个公共初始状态),并根据这个说话人的新嵌入不断更新RNN状态。在下面的示例中,蓝色说话人不断更新其RNN状态,直到另一个黄色说话人出现。如果blue稍后再次说话,它将继续更新其RNN状态。(这只是下图中y7段的一种可能性。如果新的说话人green进入,它将以一个新的RNN实例开始。)
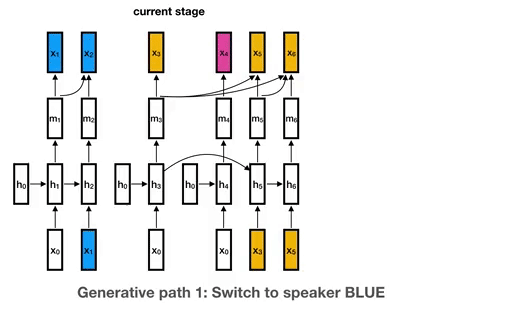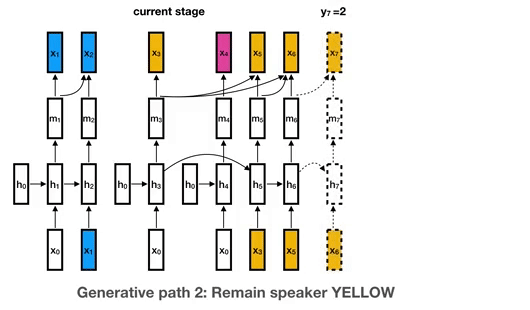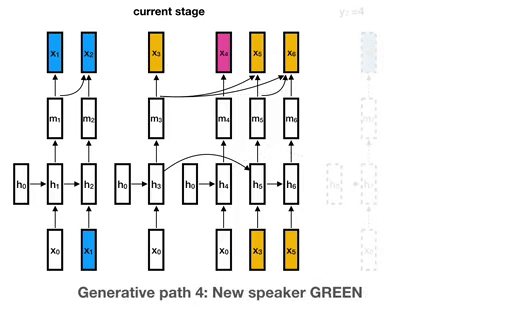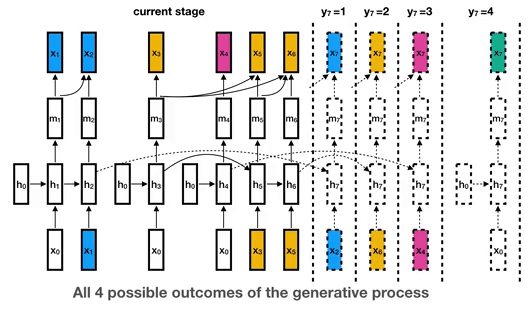
将说话者表示为RNN状态,使我们能够使用RNN参数学习不同说话者和话语之间共享的高层次知识,这保证了更多标记数据的有用性。相比之下,常用的聚类算法几乎总是独立地处理每一个单独的话语,因此很难从大量的标记数据中获益。
所有这些的结果是,给定有时间戳的说话者标签(即我们知道谁在什么时候说话),我们可以用标准的随机梯度下降算法训练模型。一个训练好的模型可以用于对未听过的说话者的新语音进行扩频。此外,使用在线解码使其更适合于延迟敏感的应用程序。
未来的工作
虽然我们已经用这个系统取得了令人印象深刻的分类性能,但我们目前仍在探索许多令人兴奋的方向。首先,我们正在改进我们的模型,使其能够很容易地集成上下文信息来执行脱机解码。这可能会进一步降低DER,这对于延迟不敏感的应用程序更有用。其次,我们想要直接建模声学特征,而不是使用d向量。通过这种方式,可以对整个说话人分类系统进行端到端的训练。
要了解更多关于这项工作的信息,请参阅我们的论文 [ 1 ] ^{[1]} [1]。要下载本系统的核心算法,请访问Github页面 [ 5 ] ^{[5]} [5]。
致谢
这项工作是由谷歌人工智能和Speech &公司紧密合作完成的助理团队。投稿者包括张楠(实习生)、王泉、朱正耀和王冲。
参考文献
[1] Fully Supervised Speaker Diarization https://arxiv.org/abs/1810.04719
[2] NIST SRE 2000 CALLHOME https://catalog.ldc.upenn.edu/LDC2001S97
[3] Speaker Diarization with LSTM https://arxiv.org/abs/1710.10468
[4] Speaker diarization using deep neural network embeddings https://ieeexplore.ieee.org/document/7953094
[5] github UIS-RNN 项目链接 https://github.com/google/uis-rnn
[6] 概率论中,中餐馆过程(Chinese restaurant process)是一个离散的随机过程。对任意正整数n,在时刻n时的随机状态是集合{1,2,…,n}的一个分化 B n B_n Bn。
-
在时刻1, B 1 = { { 1 } } B_1=\{\{1\}\} B1={{1}}的概率为1;
-
在时刻n+1,n+1并入下列之一:
- B n B_n Bn的元素之一,选中每个元素b的概率正比于其包含数字的个数,即 ∣ b ∣ / ( n + 1 ) |b|/(n+1) ∣b∣/(n+1)。
- 成为 B n B_n Bn的一个新元素,概率为 1 n + 1 \frac{1}{n+1} n+11。















 1647
1647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









