






zookeeper的简介
Apeche Zookeeper是由Apache Hadoop的子项目,起源于雅虎研究院的一个研究小组开发的一个无单点问题的分布式协同服务系统,这就是zookeeper,主要提供:统一命名服务、组成员管理、配置管理和分布式锁等分布式的基础服务(分布式应用程序可以基于zookeeper实现诸如数据发布和订阅、负载均衡、命名服务、分布式协调和通知、集群管理、Master选举,分布式锁和分布式队列等功能) ,是Goole Chubby的开源实现,将复杂而容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并提供简单的接口供用户使用
zookeeper的基本使用
zookeeper服务
应用使用zookeeper客户端库来使用zookeeper服务,zookeeper客户端负责和zookeeper集群交互,事实上就是一个client-server的架构,zookeeper集群有两种模式:standalone模式和quorum模式,处于standalone模式的zookeeper集群中只有一个独立运行的zookeeper节点,处于quorum模式的zookeeper集群包含多个zookeeper节点,通常一个zookeeper集群通常有一组机器组成,一般3-5台机器就可以组成一个可用的zookeeper集群,组成zookeeper集群的每台机器都会在内存维护当前服务器的状态,并且每台机器之间都保持着通信,只要有超过一半的机器能够正常工作,整个zookeeper集群就能正常对外提供服务,zookeeper的客户端会选择与集群中的任意一个机器创建一个session(TCP连接),而一旦客户端和某台zookeeper服务器之间断开连接后,客户端会自动连接到集群中的其他机器。具体如下:

zookeeper中的基本概念
集群角色
在分布式系统中,构建集群的每个机器都有自己的角色,典型的集群模式就是Master/Slave(主备模式),Master节点操作写请求 ,然后通过异步复制的方式同步给Slave,Slave节点提供读服务,在zookeeper中,没有采用传统的主备模式,而是引入了Leader、Follower和Observer三种角色,zookeeper集群中所有机器通过Leader选举过程来选定一台Leader节点。
Leader:Leader作为整个ZooKeeper集群的主节点,负责响应所有对ZooKeeper状态变更的请求(写请求)。它会将每个状态更新请求进行排序和编号,以便保证整个集群内部消息处理的FIFO,写操作都走leader,先到达leader的写请求会先被处理,leader决定写请求的执行顺序。
Follower:除了响应本服务器上的读请求外,follower还要处理leader的提议,并在leader提交该提议时在本地也进行提交。follower在接到写请求时会把写请求转发给Leader来处理,另外需要注意的是,leader和follower构成ZooKeeper集群的法定人数,也就是说,只有他们才参与新leader的选举、响应leader的提议。
Observer:如果ZooKeeper集群的读取负载很高,或者客户端多到跨机房,可以设置一些observer服务器,以提高读取的吞吐量。是特殊的“Follower”,其可以接收客户端 reader 请求,但不参与选举。(扩容系统支撑能力,提高读取速度)因为他不接受任何同步的写入请求,只负责 leader 同步数据;其次是observer不需要将事务持久化到磁盘,一旦observer被重启,需要从leader重新同步整个名字空间。
Session 会话
Session是指客户端会话,在zookeeper中,一个客户端连接是指客户端和服务器之间的一个TCP长连接,zookeeper对外的服务端口默认是2181,客户端在启动的时候,首先会与服务器建立一个TCP连接,从第一次连接建立开始,客户端会话的生命周期开始,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向zookeeper服务器发送请求并接受响应,还可以接收来自服务器的watch事件通知,其中Session Timeout这个值用来设置客户端会话的超时时间,当由于服务器压力太大,网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在session Timeout规定的时间内重新连接上集群,这个会话依然有效
数据模型
ZooKeeper 的数据模型是层次模型(Google Chubby 也是这么做的)。层次模型常见于文件系统。层次模型和 key-value 模型是两种主流的数据模型。ZooKeeper 的层次模型称作 znode tree。由斜杠(/)进行分割的路径,znode tree 的每个节点叫作数据节点- znode,每个znode都可以都会保存自己的数据内容,同时还会保存一些列属性信息,zookeeper中所有数据都是存储在内存中,每个节点都有一个版本(version)。版本从 0 开始。
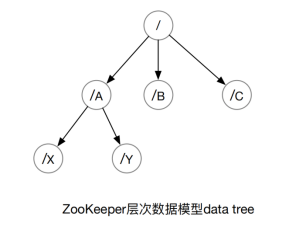
在zookeeper中,znode可以分为持久节点和临时节点两类 ,持久节点指的是一旦这个znode被创建了,除非主动进行znode删除,否则一直保存在zookeeper上,而临时节点的生命周期与客户端的会话绑定,一旦客户端会话失效,这个客户端所创建的所有临时节点将会倍一处,除此之外,每个节点还可以添加一个特殊的属性:SEQUENTIAL,一旦一个节点标记上这个属性,那么这个节点在创建的时候,zookeeper会自动在节点后面追加一个整型数字,这个整型数字是一个由父节点维护的单调自增数字,所以在zookeeper中一个节点可以分为以下:
1. 持久性的 znode (PERSISTENT): ZooKeeper 宕机,或者 client 宕机,这个 znode 一旦创建就不会丢失。只能通过调用delete来进行删除
2. 临时性的 znode (EPHEMERAL): 当创建该节点的客户端崩溃或关闭了与 ZooKeeper的连接时,或者 client 在指定的 timeout 时间内没有连接 server ,这个节点就会被删除(临时节点不允许有子节点)
3. 持久顺序性的 znode(PERSISTENT_SEQUENTIAL): znode 除了具备持久性 znode 的特点之外,znode 的名字具备顺序性。
4. 临时顺序性的 znode(EPHEMERAL_SEQUENTIAL): znode 除了具备临时性 znode 的特点之外,znode 的名字具备顺序性。
znode一共有以上4种类型:持久的(persistent)、临时的 (ephemeral)、持久有序的(persistent_sequential)和临时有序的 (ephemeral_sequential)
状态信息
通过zookeeper上的数据节点进行数据的写入和子节点的创建,事实上,每个数据节点除了存储了数据内容之外,还存储了数据节点的一些状态信息,可以通过ls2获取节点,通过ls2命令显示的就是节点的状态信息,这其实就数据节点的Stat对象的格式化输出,如果就是zookeeper中的Stat类的数据结构

Stat类包含了zookeeper上一个数据节点的所有状态信息,包括 事务ID、版本信息和子节点个数,如下:
| 状态属性 | 说明 |
| czxid | 即Created ZXID,表示该数据节点被创建时的事务ID |
| mzxid | 即Modified ZXID,表示该节点最新一次更新发生时的事务ID |
| ctime | 即Created Time,表示节点创建时的时间 |
| mtime | 即Modified Time,表示节点最新一次更新发生时的时间 |
| version | 数据节点的版本号 |
| cversion | 子节点的版本号 |
| aversion | 节点ACL(授权信息)的版本号
|
| ephemeralOwner | 创建该临时节点的会话的sessionID,如果该节点是持久节点,那么该属性值为0 |
| dataLength | 节点数据的长度 |
| numChildren | 当前节点子节点个数. |
| pzxid | 表示该节点的子节点列表最后一次被修改时的事务ID,注意只有子节点列表变更才会变更pzxid,子节点内容变更不影响pzxid |
数据版本
zookeeper在每个znode上都会维护一个叫做Stat的数据结构,Stat中记录了这个znode的三个数据版本,分别是version(当前znode的版本),cversion(当前znode的子节点的版本)以及aversion(当前znode的ACL版本),在zookeeper中,version属性是实现的乐观锁机制,在zookeeper服务器的PrepRequestProcessor处理器类中,在处理每个数据更新(setDataRequest)请求时,会进行版本检验,如下:
version = setDataRequest.getVersion();
currentVersion = nodeRecord.stat.getVersion();
if (version != -1 && version != currentVersion) {
throw new BadVersionException(path);
}
version = currentVersion + 1;
从上面可以看出,在进行一次setDataRequest请求处理时,首先进行了版本检查:zookeeper会从setDataRequest请求中获取当前版本的version,如果version为-1就说明客户端不要求使用乐观锁,如果不是-1,且版本不对,则抛出BadVersionException
Watcher
Watcher是事件监听器,是zookeeper的一个重要特性,zookeeper允许用户在指定节点上注册一些Watcher,并且在一些特定的事件触发的时候,zookeeper服务端会将事件通知到客户端上,另外watcher的通知是一次性的,即一旦触发了一次通知后,Watcher就会失效,因此客户端需要反复的注册Watcher。
zookeeper的Watcher机制主要包括了客户端线程、客户端WatcherManager和zookeeper服务器,具体的工作流程:客户端在向zookeeper服务器注册Watcher的同时,会将Watcher对象存储在客户端的WatcherManager中。当zookeeper服务器端触发Watcher事件后,会向客户端发送通知,客户端线程从WatcherManager中取出对应的Watcher对象执行回调逻辑。
Watcher接口
在zookeeper中,接口类Watcher用于处理标准的事件处理器,定义事件通知相关逻辑,包含了KeeperState枚举类代表通知状态
和EventType代表事件类型的枚举,同时定义了事件的回调方法:process(WatcherEvent event)
Watcher事件
同一个事件类型在不同的通知状态代表的含义不同,具体如下:

此前提到NodeDataChanged事件中节点的数据内容和数据的版本号dataversion,因此即使相同的数据内容来更新还是会触发这个通知,因为对于zookeeper来说,无论数据内容是否变更,一旦有客户端调用数据更新的接口去,且更新成功就会更新dataversion值;NodeChildrenChanged事,件会在数据节点的子节点变更时触发,即新增或者删除子节点,子节点内容变化不会会触发,对于AuthFailed这个事件,触发条件不是因为当前客户端会话没有权限而是授权失败,如下:
ZooKeeper zooKeeper = new ZooKeeper("localhost:2181", 5000, null);
zooKeeper.addAuthInfo("digest","root:123".getBytes());
List acls = new ArrayList();
zooKeeper.create("/zookeeper", "".getBytes(), acls, CreateMode.EPHEMERAL);
/*使用正确的shcema:digest,使用错误的Auth*/
ZooKeeper zooKeeper_error = new ZooKeeper("localhost:2181", 5000, null);
zooKeeper_error.addAuthInfo("digest","abc:123".getBytes());
zooKeeper_error.getData("/zookeeper", true,null);
/*使用错误的shcema:digest2,使用错误的Auth*/
ZooKeeper zooKeeper_error2 = new ZooKeeper("localhost:2181", 5000, null);
zooKeeper_error2.addAuthInfo("digest2","abc:123".getBytes());
zooKeeper_error2.getData("/zookeeper", true,null);以上2个程序都使用了错误的Auth,root:123,运行第一个程序,会抛出NoAuthExeception,而第二个程序运行后抛出AuthFailedException异常,同时会收到对应的Watcher事件通知:(AuthFailed,Node)
回调方法process()
process方法是Watcher接口中的一个回调方法,当zookeeper想客户端发送一个watcher事件通知时,客户端就会相应的process方法进行回调,从而实现对事件的处理
public interface Watcher {
void process(WatchedEvent var1);
}
public class WatchedEvent {
private final KeeperState keeperState;
private final EventType eventType;
private String path;
}其中WatcherEvent包含了每一个事件的三个基本属性:通知状态(KeeperState)、事件类型(eventType)和节点路径(path)
zookeeper使用WatchedEvent对象用来封装服务端事件并传递给Watcher,从而方便的回调方法process对服务端事件进行处理
除了WatchedEvent,还有一个WatcherEvent实体,笼统的说两者表示的是同一个事物,都是对一个服务端事件的封装,不同的是WatchedEvent是一个逻辑事件,用于服务端和客户端程序执行过程中所需的逻辑对象,而WatcherEvent因为实现了序列化接口,可以用于网络传输,如下:
public class WatcherEvent implements Record {
private int type;
private int state;
private String path;
}服务端在生成WatchedEvent事件之后,会调用getWrapper方法将自己包装成可序列化的WatcherEvent事件,以便通过网络传输到客户端,客户端接收到服务端的事件对象后,首先会将WatcherEvent事件还原成一个WatchedEvent事件并传递给process方法处理。无论是WatchedEvent还是WatcherEvent,zookeeper封装都是简单的,服务端会发送给客户端一个“ZNode数据内容变”事件客户端只能够接收到如下信息:
KeeperState:syncConnected
EventType:NodeDataChanged
Path:/zookeeper
Watcher的工作机制
zookeeper的Watcher机制,总的来说可以概括以下三个过程:
- 客户端注册Watcher
- 服务端处理Watcher
- 客户端回调Watcher
客户端注册Watcher
在创建一个Zookeeper客户端对象实例的时候,可以向构造方法中传入要给默认的Wathcer:
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher)这个Watcher将作为整个Zookeeper会话期间的默认Watcher,会一直保存在客户端ZKWatchManager的defaultWatcher中,另外Zookeeper客户端也可以通过getData、getChildren和exist三个接口来向Zookeeper服务器注册Watcher,三者注册Watcher的工作原理是一致的,以getData接口为例:
public void getData(String path, Watcher watcher, DataCallback cb, Object ctx)
public void getData(String path, boolean watch, DataCallback cb, Object ctx)第二个接口的boolean参数来标识是否使用上文中提到的默认Watcher来进行注册,注册逻辑和第一个接口是一致的
Watcher特性总结
一次性:无论是客户端还是服务端,一旦一个Watcher被触发,Zookeeper都会将其从相应的存储中删除,因此Watcher的使用需要反复注册,这样的设计有效减轻服务端的压力
客户端串行执行:客户端Watcher回调的过程是一个串行同步的过程,保证有序,注意不要因为一个Watcher的处理逻辑影响了整个客户端的Watcher回调。
轻量:WatchedEvent是zookeeper整个Watcher通知机制的最小通知单元,这个数据结构只有三部分内容:通知状态,事件类型和节点路径,而没有事件的具体内容,客户端需要主动去获取事件的变更内容,此外客户端向服务端注册Watcher的时候,并不会把真实的Watcher对象传递到服务器,仅仅是在客户端请求中使用boolean类型属性进行标记,同时服务端仅仅保存了当前连接的ServerCnxn对象。
zookeeper的ACL
zookeeper提供了一套完善的ACL(Access Control List)权限控制机制来保障数据的安全,权限控制中,如Unix/Linux文件系统中,使用的是目前最广泛的权限控制方式-UGO(User,Group,Other)权限控制机制,简单的说UGO是针对一个文件和目录,对创建者(User)、创建者所在的组(Group)、和其他用户(Other)分别配置不同的权限,是一种粗粒度的文件系统权限控制模式,UGO无法做到同组的不同用户拥有不同的权限
ACL是访问控制列表,是一种粒度较细的权限管理方式,可以针对任意用户和组进行细粒度的权限控制,Linux从2.6支持这个特性,zookeeper的ACL和Unix/Linux的ACL有一些区别,主要从三个方面描述ACL机制:
- 权限模式Schema
- 授权对象ID
- 权限Permission
权限模式
用来确定权限验证过程中使用的检验策略,在zookeeper中最多使用的是以下四种权限策略:
IP
IP模式通过IP地址粒度来进行权限控制,如配置"ip:192.160.30.10",则表示权限控制室针对这个IP地址的,同时也支持按照网段的方式进行配置,如"ip:192.160.30.1/24"表示192.160.30.*这个IP段进行权限控制
Digest
是最常用的权限控制模式,类似:"userName:password"形式的权限标识进行权限配置,便于区分不同应用,当我们通过"userName:password"形式标识后,zookeeper会对其先后进行两次编码处理,分别是SHA-1算法加密和BASE64编码,具体实现由:DigestAuthenticationProvider.generateDigest(String idPassword)函数进行封装,如下
public static void main(String[] args) throws Exception{
System.out.println(DigestAuthenticationProvider.generateDigest("root:abc123"));
}允许结果:"root:VVSTY9k7e0y1gfT9P5MZ33kTrlA=",可以看出"root:abc1234 "最终变成一个无法辨认的字符串了
World
World是一种最开放的权限控制模式,数据节点的访问权限对所有用户开放,即所有用户都可以在不进行任何权限校验的情况下操作zookeeper上的数据,world模式可以看成一种特殊的Digest模式,它只有一个权限标识即"world:anyone"
Super
Super模式就是超级用户的意思,也是一种特殊的Digest模式,在Super模式下,超级用户可以对任意Zookeeper上的数据节点进行任何操作,存在以下这种情况,如果一个持久数据节点包含了ACL权限控制,而其创建者客户端已经退出或者不再使用,这些数据的清理就需要ACL模式的超级管理员来处理,要使用超级管理员权限,首先需要在zookeeper服务器上开启Super模式,方法是在zookeeper服务器启动的时候,添加如下系统属性:
-Dzookeeper.DigestAuthenticationProvider.superDigest=root:VVSTY9k7e0y1gfT9P5MZ33kTrlA=
完成对zookeeper服务器的Super模式开启后,就可以在应用程序上使用了。
授权对象ID
授权对象指的是权限赋予的用户或一个指定实体,例如IP地址或是机器等,在不同的权限模式下,授权对象是不同的,关系如下:
| 权限模式 | 授权对象 |
| IP | 通常是一个IP地址或者IP段 |
| Digest | 自定义,通常是“userName:Base64(SHA-1(userName:password))” |
| World | 只有一个ID:“anyone“ |
| Super | 与Digest一致 |
权限:Permission
权限就是指那些通过权限检查后背允许运行的操作,在zookeeper中所有对数据的操作权限分为以下五大类:
- CREATE: 允许授权对象在该数据节点下创建子节点
- READ:允许授权对象访问数据节点并读取其数据内容和列出其子节点
- WRITE:允许授权对象对数据节点进行更新操作
- DELETE: 允许授权对象删除该数据节点的子节点
- ADMIN: 允许授权对象对数据节点进行ACL相关设置操作
设置ACL
通过zkCli脚本登陆zookeeper服务器后,可以通过两种方式设置ACL,一种是在数据节点创建的同时进行ACL权限设置,命令如下:
create [-s] [-e] path data acl
另外一种是通过使用setACL命令针对已经存在的数据节点进行ACL设置
setAcl path acl
自定义权限控制器
实现自定义权限控制器非常简单,zookeeper定义了一个标准权限控制器需要实现的接口:
org.apache.zookeeper.server.auth.DigestAuthenticationProvider
public class DigestAuthenticationProvider implements AuthenticationProvider {
public String getScheme() {
}
public boolean isAuthenticated() {
}
public boolean isValid(String id) {
}
public boolean matches(String id, String aclExpr) {
}
}用户可以基于该接口实现自定义的权限控制器,而上述的几个权限模式队友的就是zookeeper自带的DigestAuthenticationProvider和IPAuthenticationProvider两个权限控制器
注册自定义权限控制器
zookeeper支持通过系统属性和配置文件两种方式来注册自定义权限控制器:
系统属性-Dzookeeper.authProvider.X
即在zookeeper启动参数中添加如下的系统属性:-Dzookeeper.authProvider.1=com.zkbook.MyAuthenticationProvider
配置文件方式
在zoo.cfg配置文件中添加如下配置项:
authProvider.1=com.zkbook.MyAuthenticationProvider
对于权限控制器的注册,zookeeper采用了延迟加载的策略,即只有在第一次处理包含权限控制的客户端请求时,才会进行权限控制的初始化,同时,zookeeper还会将所有的权限控制器都注册到ProviderR egistry中去,在具体实现中,zookeeper首先会将DigestAuthenticationProvider和IPAuthenticationProvider这两个控制器初始化,然后通过扫描zookeeper.authProvider. 这一属性获取到用户配置的自定义权限控制器,完成初始化
zookeeper的ZAB协议
在zookeeper中没有完全采用Paxos算法,而是使用了一种称为Zookeeper Atomic Broadcast(ZAB,zookeeper原子消息广播协议)的协议作为其数据一致性的核心算法,ZAB协议是为分布式协调服务zookeeper专门设计的一种支持崩溃可恢复的原子广播协议,基于该协议,zookeeper实现了一种主备模式的系统架构来保持集群中个副本之间数据的一致性,zookeeper使用一个单一的主进程来接收并处理客户端的所有事务请求,并采用ZAB的原子广播协议,将服务器数据的状态变更以事务Proposal的形式广播到所有的副本进程上去。
ZAB协议的核心就是定义了对于那些会改变zookeeper服务器数据状态的事务请求的处理方式,即:
所有事务请求必须有一个全局唯一的服务器来协调处理,这样的服务器被称为Leader服务器,而剩下的其他服务器组成Follower服务器,Leader服务器负责将一个客户端事务请求转换成一个事务提议(Proposal),并将该Proposal分发给集群中所有的Follower服务器,并等待所有的Follower的响应,一旦超过半数的Follower服务器进行了正确的响应,那么Leader就会再次向所有的Follower发起Commit消息,要求将前一个Proposal进行提交
ZAB协议包括两种基本的过程(模式):崩溃恢复和消息广播,当整个服务框架启动过程中,或是当Leader服务器出现网络终端、崩溃推出或者重启等异常情况,ZAB协议就会进入恢复模式并选举出新的Leader服务器,当选举产生新的Leader服务器,同时集群中有过半的机器与该Leader服务器完成了状态同步之后,ZAB协议就会退出恢复模式,其中状态同步是指数据同步,用来保证集群中存在过半机器能够和Leader服务器的数据状态保持一致。
当集群中已经有了过半的Follower服务器完成了和Leader的状态同步,那么整个服务框架就可以进入消息广播模式,当一台同样遵守ZAB协议的服务器启动后加入到集群中,如果此时集群中已经存在一个Leader服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到Leader所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去,因为在zookeeper只能有一个Leader服务器来处理事务请求,所以当Leader服务器接收到客户端的事务请求后,会生成对应的事务提案并发起一轮广播协议,而如果是集群中的其他机器收到客户端的事务请求,那么这些非Leader服务器会首先将这个事务请求转发给Leader服务器
消息广播
ZAB协议的消息广播过程使用的是一个原子广播协议,类似于一个二阶段提交的过程,针对客户端的事务请求,Leader服务器会为其自动生成对应的事务Proposal,并将其发送给集群中的其他机器,然后会收集各自的选票,最后进行事务提交,与二阶段提交的区别是移除了中断逻辑,所有的Follower服务器要么正常反馈Leader提出的事务Proposal,要么就抛弃Leader服务器,同时,ZAB协议可以在过半的Follower响应反馈后就提交事务Proposal,而不需要等待集群所有的Follower服务器都反馈响应,整个消息广播协议是基于具有FIFO特性的TCP协议来进行网络通信的,因此能够很容易的保证消息广播过程中消息的接收和发送的顺序性,Leader服务器会为每个事务请求生成对应的Proposal来进行广播,并且在广播事务Proposal之前,Leader服务器会首先为这个事务Proposal分配一个全局单递增的唯一ID,称为事务ID(ZXID),由于ZAB协议需要保证每个消息的严格因果关系,所以必须将每个事务Proposal按照其ZXID的先后顺序来进行排序处理,具体的是在消息广播过程中,Leader服务器会为每个Follower服务器都各自分配一个单独的队列,然后将需要广播的事务Proposal依次放到这些队列中去,并且根据FIFO策略进行消息发送,每个Follower接收到事务Proposal之后,首先会将其以事务日志的形式写到本地磁盘中去,并且在写入成功后反馈给Leader服务器一个ACK响应,当Leader服务器接收到过半的Follower的ACK响应后,就会广播一个Commit消息给所有的Follower服务器通知其进行事务提交,同时Leader自身也会完成对事务的提交,而每个Follower在接收到Commit之后也会完成对事务的提交
崩溃恢复
当Leader服务器出现崩溃或者重启,亦或是集群中Leader服务器失去与过半的Follower失去联系,那么在重新开始新的一轮原子广播事务操作之前,所有的进程首先会使用崩溃恢复协议来达到一个一致的状态,那么就会进入崩溃恢复模式,在ZAB协议中为了保证程序的正确运行,整个恢复过程结束后需要选举出一个新的Leader服务器,在崩溃恢复过程中为了保证数据的一致性需要做到以下:
- ZAB协议需要确保那些已经在Leader服务器上提交的事务最终被所有服务器都提交(假如一个事务在Leader服务器上被提交了,并且得到了过半的Follow服务器的ACK反馈,但是在它将Commit消息发送给所有Follower机器之前,Leader服务器挂了,ZAB协议能够确保这个事务最终被所有服务器都提交成功,否则将出现不一致)
- 如果在崩溃恢复过程中出现一个需要被丢弃的提案,那么在崩溃恢复结束后需要跳过该事务Proposal(假如初始的Leader服务器提出一个事务就崩溃退出,从而导致集群中其他的服务器都没有收到这个事务的Proposal,于是当Leader服务器恢复过来再次加入集群,ZAB协议需要保证丢弃这个事务)
Leader选举算法:为了确保满足以上:提交已经被Leader提交的事务Proposal,同时丢弃已经被跳过的事务Proposal,只需要保证Leader选举算法选举出来的Leader服务器拥有集群中所有机器最高编号(即ZXID最大)的事务Proposal,就可以保证这个心选举出来的Leader一定具有所有已经提交的提案,同时也省去了Leader服务器检查Proposal的提交和丢弃工作。
数据同步:完成Leader选举,正式工作(接收客户端事务请求,然后提出新的提案)之前,Leader服务器首先确认事务日志中所有的Proposal是否都已经被集群中过半的机器提交了,即是否完成数据同步。
数据同步详情:Leader服务器会为每个Follower服务器都准备一个队列,并将那些没有被各Follower服务器同步的事务以Proposal消息的形式逐个发送给Follower服务器,并在每个Proposal消息后紧接着发送一个Commit消息,表示该事务已经被提交,等到Follower服务器将所有其尚未同步的事务Proposal都从Leader服务器上同步过来并成功应用到本地数据库后,Leader服务器就会将该Follower服务器加入到真正可用的Follower列表中,开始其他流程。
ZAB协议中的事务编号ZXID是一个64位的数字,其中低32位可以看作是一个简单的单调递增的计数器,针对客户端的每一个事务请求,Leader服务器在产生一个新的事务Proposal的时候,都会针对该计数器进行加1,而高32位则代表了Leader周期的epoch号,每当选举出新的Leader服务器,就会从这个Leader服务器上取出其本地日志中最大事务Proposal的ZXID,并从该ZXID中解析出对应的epoch值,然后在加1,之后以此编号作为新的epoch,并将低32位0来开始生成新的ZXID,以此来通过epoch编号区分Leader周期的变化,避免不同的Leader服务器错误的使用相同的ZXID提出不同的事务Proposal的异常情况。
基于这样的策略,当一个包含上一个Leader周期中尚未提交过的事务Proposal的服务器启动时,其肯定无法成为Leader,因为当前集群中肯定包含一个Quorum集合,该集合中的机器包含了更高的epoch的事务Proposal,因此这台机器的事务Proposal肯定不是最高的,而且无法成为Leader,当这台机器加入集群中,以Follower角色连接到Leader之后,Laeder服务器会根据自己服务器上最后被提交的Proposal来和Follower服务器的Proposal进行对比,从而Leader会要求Follower进行回退到一个确实已经被集群过半机器提交的最新的事务Proposal
zookeeper的搭建
略
安装Zookeeper及使用zookeeper命令
直接使用docker 安装zookeeper的单机版,启动容器后(zookeeper服务),进入容器,运行客户端服务./zkCli.sh(Zookeeper的一个简易客户端),连接服务端成功,若连接不同的主机,可使用如下命令:./zkCli.sh -server ip:port,可以使用帮助命令help来查看客户端的操作
客户端尝试连接到客户端发送的连接串 localhost/127.0.0.1:2181中的一个服务器。随后一个确认信息说明客户端与本地的 ZooKeeper服务器建立了TCP连接。后面的日志信息确认了会话的建 立,并告诉我们会话ID为:0x13b6fe376cd0000。最后客户端库通过 SyncConncted事件通知了应用。应用需要实现Watcher对象来处理这个
JLine support is enabled
2019-09-15 09:34:04,848 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@879] - Socket connection established to localhost/127.0.0.1:2181, initiating session
[zk: localhost:2181(CONNECTING) 0] 2019-09-15 09:34:04,993 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1299] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x101178770b40008, negotiated timeout = 30000
命令操作演示:
创建节点:使用create命令,可以创建一个Zookeeper节点, 如
create [-s] [-e] path data acl
其中,-s或-e分别指定节点特性,顺序或临时节点,若不指定,则表示持久节点;acl用来进行权限控制。
- 创建持久节点,不指定参数,默认是持久的
[zk: localhost:2181(CONNECTED) 3] create /app1 1
Created /app1
- 创建持久顺序节点
使用 create -s /app2 2 命令创建app2顺序节点,可以看到创建的app2节点后面添加了一串数字以示区别。
[zk: localhost:2181(CONNECTED) 6] create -s /app2 2
Created /app20000000001
- 创建临时节点
[zk: localhost:2181(CONNECTED) 8] create -e /app3 3
Created /app3
- 创建临时顺序节点:-s -e 指定即可
ls / 查看所有节点:
[zk: localhost:2181(CONNECTED) 9] ls /
[app1, app20000000001, app3, zookeeper]
使用quit退出客户端,在使用zkCli连接到zk服务,再次查看所有节点,发现app3这个临时节点没有了
[zk: localhost:2181(CONNECTED) 0] ls /
[app1, app20000000001, zookeeper]
读取节点:与读取相关的命令有ls 命令和get 命令,ls命令可以列出Zookeeper指定节点下的所有子节点,只能查看指定节点下的第一级的所有子节点;get命令可以获取Zookeeper指定节点的数据内容和属性信息。其用法分别如下
ls path [watch]:查看path下所有子节点
get path [watch]:获取path节点保存的数据
ls2 path [watch]:
若获取根节点下面的所有子节点,使用ls / 命令即可,前面演示过了
[zk: localhost:2181(CONNECTED) 1] ls /
[app1, app20000000001, zookeeper]
[zk: localhost:2181(CONNECTED) 2] get /app1
1
[zk: localhost:2181(CONNECTED) 3] ls2 /app20000000001
'ls2' has been deprecated. Please use 'ls [-s] path' instead.
[]
cZxid = 0x3
ctime = Wed Sep 11 02:39:15 UTC 2019
mZxid = 0x3
mtime = Wed Sep 11 02:39:15 UTC 2019
pZxid = 0x3
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 1
numChildren = 0
[zk: localhost:2181(CONNECTED) 4]
Ls2命令主要用来获取根节点数据内容和属性信息(已经过期推荐使用ls -s来替
java客户端API的使用
zookeeper作为分布式服务框架,提供简单的分布式原语,并对多种语言提供了API,下面介绍java客户端的API的使用方式
创建会话
客户端可以通过一个Zookeeper(org.apache.zookeeper)实例来连接zookeeper服务器,Zookeeper的4种构造方法如下:
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher)
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, boolean canBeReadOnly)
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, long sessionId, byte[] sessionPasswd)
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, long sessionId, byte[] sessionPasswd, boolean canBeReadOnly)参数说明:
| 参数名 | |
| connectString | 指zookeeper服务器列表,由host:port字符串组成,每一个都代表一个zookeeper机器,如:192.168.1.110:2181,192.168.1.111:2182,192.168.1.112:2183,代表为客户端指定三台服务器的地址,另外也可以设置连接上zookeeper后的根目录,如:host:port/zookeeper,指定连接服务器后所有对zookeeper操作的都是基于这个/zookeeper目录 |
| sessionTimeout | 会话超时时间,以“毫秒”为单位的整型值,在一个会话周期内zookeeper客户端和服务端之间会通过心跳检测机制来维持会话的有效性,一旦在sessionTimeout时间内没有进行心跳检测,会话失效 |
| watcher | Zookeeper允许客户端在构造方法中传入一个接口Watcher(org.apache.zookeeper.Watcher)的实现类对象作为默认的Watcher事件通知处理器,当然可以设置为null,表示不需要默认的Watcher处理器 |
| canBeReadOnly | 标识当前会话是否支持“read-only”,默认情况下,zookeeper集群中一个机器如果和集群中过半及以上机器失去网络连接,那么这个机器将不再处理客户端请求(包括读写),但是在某些场景下,当zookeeper发生故障,我们希望zookeeper服务器能够提供读服务 |
| sessionId和sessionPasswd | 代表会话ID和会话密钥i,这2个参数唯一确定一个会话,同时客户端使用这2个参数可以实现客户端的会话复用,已达到恢复会话的效果,当第一次连接上Zookeeper服务器时,通过调用Zookeeper对象实例的两个接口ukeyi获取当前会话ID和密钥 long getSessionId(); byte [] getSessionPasswd(); 下次创建Zookeeper对象时传入即可 |
注意:Zookeeper客户端和服务端会话的建立时一个异步的过程,构造方法会在处理完客户端初始化工作后立即返回,大多数情况下此时并没有真正建立好一个可用的会话,此时处于会话生命周期的"CONNECTING"的状态,当会话真正创建完,Zookeeper服务端会向客户端发送一个事件通知,此时才算真正建立了会话,demo如下:在接受到服务端发来的SyncConnected事件之后,解除主程序的等待阻塞。
static CountDownLatch latch = new CountDownLatch(1);
public static void main(String[] args) throws Exception{
ZooKeeper zooKeeper = new ZooKeeper("localhost:2181", 5000, new Watcher() {
public void process(WatchedEvent event) {
if(event.getState() == Event.KeeperState.SyncConnected){
latch.countDown();
}
}
});
System.out.println(zooKeeper.getState());
try{
latch.await();
}catch (Exception e){
}
}创建节点
客户端使用Zookeeper的API来创建一个数据节点,有如下两个接口:
public String create(String path, byte[] data, List<ACL> acl, CreateMode createMode)
public void create(String path, byte[] data, List<ACL> acl, CreateMode createMode, StringCallback cb, Object ctx)
参数说明:
| 参数名 | 说明 |
| path | 需要创建的数据节点的节点路径 |
| data[] | 节点创建后的初始内容,节点内容只支持字节数组,zookeeper不负责节点内容的序列化 |
| acl | 节点的acl策略 |
| createMode | 节点类型,是一个枚举类型,通常有4种节点类型
|
| cb | 注册一个异步回调函数,需要实现StringCallback接口,重写void processResult(int rc,String path,Object ctx,String name) 当服务端节点创建完毕后,zookeeper客户端会自动调用这个方法,处理相关业务逻辑 |
| ctx | 用于传递一个对象,可以在上面的回调方法执行的时候使用,通常放一个上下文(Context)信息 |
可以看出上面2个创建节点的方法,一个是同步一个是异步的,无论同步还是异步,zookeeper都不支持递归创建,即无法在父节点不存在的情况下创建子节点,另外如果一个节点已经存在,创建同名节点,抛出NodeExistsException异常
异步创建接口时候需要实现AsyncCallback.StringCallback()接口,AsyncCallback包含了StatCallback、DataCallback、ACLCallback、ChildrenCallback、Children2Callback、StringCallback和VoidCallback七种不同的回调接口,可以在不同的异步接口中实现不同的接口,和同步接口的区别是节点的创建过程(包含网络通信和服务端的节点创建过程)是异步的,并且在同步接口调用过程中,需要关注接口抛出异常的可能,而异步接口中,接口本事不会抛出异常,所有的异常都会在回调函数中的Result Code(响应码)来体现,主要是void ProcessResult(int rc, String path, Object ctx, String name)方法的执行,参数说明如下:
| 参数名 | 说明 |
| rc | Result Code 服务端响应码,客户端可以从这个响应码中识别API调用的结果,常见响应码如下 0(ok):接口调用成功 -4(ConnectionLoss):客户端和服务端连接已断开 -110(NodeExists):指定节点已存在 -112(SessionExpired):会话已过期 |
| path | 接口调用时传入API的数据节点的节点路径参考值 |
| ctx | 接口调用时传入API的ctx参考值 |
| name | 实际在服务端创建的节点名,如创建顺序节点时,在回调方法中服务端会返回这个数据节点的完整节点路径 |
删除节点
客户端可以通过zookeeper的API来删除一个节点,有如下两个接口:同样一个是同步删除一个是异步删除
public void delete(String path, int version)
public void delete(String path, int version, VoidCallback cb, Object ctx)参数说明:
| 参数名 | 说明 |
| path | 指定数据节点的节点路径 |
| version | 指定节点的数据版本,即表明本次删除操作是针对该数据版本进行的 |
| cb | 注册一个异步回调函数 |
| ctx | 用于传递上下文信息的对象 |
注意:在zookeeper中只允许删除叶子节点,如果一个节点存在至少一个子节点,该节点无法删除,必须先删除其所有的子节点后才能删除
读取节点
读取数据包括子节点列表的获取和节点数据的获取,子节点列表的获取,使用getChildren()方法获取,而节点数据的内容使用getData()方法获取。
getChildren:有以下8个重载方法,其中包括了同步和异步:
public List<String> getChildren(String path, Watcher watcher)
public List<String> getChildren(String path, boolean watch)
public void getChildren(String path, Watcher watcher, ChildrenCallback cb, Object ctx)
public void getChildren(String path, boolean watch, ChildrenCallback cb, Object ctx)
public List<String> getChildren(String path, Watcher watcher, Stat stat)
public List<String> getChildren(String path, boolean watch, Stat stat)
public void getChildren(String path, Watcher watcher, Children2Callback cb, Object ctx)
public void getChildren(String path, boolean watch, Children2Callback cb, Object ctx)方法参数的定义:
| 参数名 | 说明 |
| path | 指定数据节点的节点路径,即API调用的目的是获取该节点的子节点列表 |
| watcher | 注册的Watcher,一旦在本次的子节点获取之后,子节点列表发生变更,那么就会向客户端发送通知,可以为null |
| watch | 表明是否注册一个Watcher,如果为true,则表示使用默认的Watcher(创建zookeeper时指定的Watcher),如果为false,表明不需要注册Watcher |
| cb | 注册一个异步回调函数 |
| ctx | 用于传递上下文信息的对象 |
| stat | 指定数据节点的节点状态信息,用法是在接口中传入一个旧的stat变量,该stat变量会在方法执行过程中被来自服务端响应的新的stat对象替换 |
具体的,在获取子节点列表时,如果Zookeeper客户端在获取到指定节点的子节点列表后还需要订阅这个子节点列表的变化通知,那么就可以通过注册一个Watcher来实现,当有子节点被添加或者删除,服务端就会向客户端发送一个NodeChildrenChanged(EventType.NodeChildrenChanged)类型的事件通知,但这个通知并不包含新的子节点列表,必须手动在获取一次子节点列表,另外节点状态信息对象stat中记录了一个节点的基本属性信息,包含节点创建时候事务ID(cZxid)、最后一次修改的事务ID(mZxid)和节点的内容长度(dataLength)等,当我们需要获取节点最新的节点状态信息,我们可以通过传入一个旧的stat变量到API接口,在执行过程中,它会被服务端响应的新的stat对象替换。
getData有以下4个重载方法,具体如下
public byte[] getData(String path, Watcher watcher, Stat stat)
public byte[] getData(String path, boolean watch, Stat stat)
public void getData(String path, Watcher watcher, DataCallback cb, Object ctx)
public void getData(String path, boolean watch, DataCallback cb, Object ctx)具体的参数说明和getChildren的基本一致,只是getChildren是获取节点的列表,返回的是List<String>,而getData是获取该节点的数据内容,返回的是数据的Byte[],因为在数据只支持这种类型的存储,所有获取数据时也返回该类型。另外需要注意的是节点数据的变化是指数据的版本变化,而不是数据值的变化,就算设置相同的值也会触发通知(注册通知的前提)
更新数据
客户端通过zookeeperde API来更新一个节点的数据内容,使用setData方法,同步和异步2种:
public void getData(String path, boolean watch, DataCallback cb, Object ctx)
public Stat setData(String path, byte[] data, int version)参数说明:
| 参数名 | 说明 |
| path | 指定数据节点的节点路径,API调用的目的是更新该节点的数据内容 |
| data[] | 一个字节数组,即需要使用该数据内容来覆盖节点现在的数据内容 |
| version | 指定节点的数据版本,表明本次更新操作是针对该数据的这个版本进行的,一个乐观锁 |
| cb | 注册的一个异步回调函数 |
| ctx | 传递上下文信息的对象 |
上面的version参数,可以有效的避免分布式更新的并发问题,在使用setData传入version的时候,当传入的值是“-1”,是可以更新成功的,在zookeeper中版本都是从0开始的计数的,严格的说“-1"不是一个版本号而是一个标识符,就是告诉zookeeper服务器,客户端需要基于数据最新版本进行操作,如果对zookeeper数据节点的更新操作没有原子性要求,就可以使用“-1”。
检测节点是否存在
有以下4个重载方法判断节点是否存在,带有StatCallback的是异步接口
public Stat exists(String path, Watcher watcher)
public Stat exists(String path, boolean watch)
public void exists(String path, Watcher watcher, StatCallback cb, Object ctx)
public void exists(String path, boolean watch, StatCallback cb, Object ctx) 参数说明:
| 参数名 | 说明 |
| path | 指定数据节点的节点路径,即API调用的目的是检测该节点是否存在 |
| watcher | 注册的watcher,用于监听以下三类事件:
|
| watch | 指定是否复用zookeeper中默认的watch |
exists方法主要检测节点是否存在,返回值是一个stat对象,另外如果在调用的该接口的时候注册Watcher的话,还可以对节点是否存在进行监听----一旦节点被创建或者被删除或被更新都会通知客户端
权限控制
在zookeeper的实际应用中,我们的做法往往是搭建公用的一个zookeeper集群为了保证不同应用之间的数据安全性,需要对zookeeper上的数据访问进行权限控制(Access Control),zookeeper提供了ACL的权限控制机制,简单的说就是通过设置zookeeper服务器上数据节点的ACL来控制客户端对其的访问权限,如果一个客户端符合该ACL机制,那么就可以对其进行访问,否则无法操作。
zookeeper提供了多个权限控制模式(Scheme),分别是world、auth、digest、ip和super
- world:默认方式,相当于全世界都能访问
- auth:代表已经认证通过的用户(cli中可以通过addauth digest user:pwd 来添加当前上下文中的授权用户)
- digest:即用户名:密码这种方式认证,这也是业务系统中最常用的
- ip:使用Ip地址认证
ACL支持权限:
- CREATE: 能创建子节点
- READ:能获取节点数据和列出其子节点
- WRITE: 能设置节点数据
- DELETE: 能删除子节点
- ADMIN: 能设置权限
在使用zookeeper的权限控制功能,需要在创建zookeeper会话后给该会话添加相关的权限信息(AuthInfo),zookeeper客户端提供了以下API接口来进行权限信息的设置
addAuthInfo(Sting scheme, byte[] auth)其中:scheme:权限控制模式,分为world、auth、digest、ip和super;auth:是具体的权限信息,如下:
ZooKeeper zooKeeper = new ZooKeeper("localhost:2181", 5000, null);
zooKeeper.addAuthInfo("digest","root:123".getBytes());
需要注意的是:删除节点的权限控制比较特殊,当客户端对一个数据节点添加权限信息后,对于删除操作而言,其作用的范围是其子节点,也就是说当我们对一个数据节点添加权限信息后依然可以删除这个节点,但是对于这个节点的子节点,就必须使用响应的权限信息才能够删除。
常见的开源客户端:
zkClient
zookeeper的应用场景
数据发布和订阅(配置中心)
发布者将数据发布到zookeeper的一个或一系列节点上,供订阅者进行数据订阅,从而达到动态的获取数据的目的,实现配置信息的集中管理和动态更新
一般发布/订阅模式有两种设计模式,分别是:
推模式(push):在推模式,服务端主动将数据更新发送给所有订阅的客户端
和拉模式(pull):拉模式则是由客户端主动发起请求去获取最新的数据,通常客户端采用的是定时进行轮询拉取
而zookeeper采用的是二者相结合的方式:客户端想服务端注册自己需要关注的节点,一旦节点数据发生变更,那么服务端就会向相应的客户端发送watcher事件通知,客户端收到通知后,主动到服务端拉取最新的数据,一般我们可以在应用启动的时候主动到zookeeper的服务端进行一次配置的获取,同时注册一个watcher监听,当配置发生变化的时候,服务端会通知所有订阅的客户端,从而达到获取最新配置的目的。
分布式全局唯一ID
所谓的ID就是一个能够唯一标识某个对象的标识符,在我们熟悉的关系型数据库中,各个表的主键就是唯一ID,在分库分表的情况下auto_increment属性仅能针对单一表中的记录自动生成ID,而无法做到分布式环境下全局唯一,通常UUID是非常不错的全局唯一ID的生成方式,UUID是通用唯一标识码的简称,能够非常简单的保证分布式环境中的唯一性,一个标准的UUID是一个包含32位字符和4个短线_的字符串,但是UUID也有不好的地方,主要如下:
- 长度过长,存储UUID需要花费更多的空间
- 含义不明,看不出这个ID表达的含义
当然zookeeper可以实现这种全局唯一ID,主要利用就是zookeeper的API接口创建一个顺序节点,生成全局唯一ID,步骤如下:
- 所有客户端都会根据自己的任务类型,通过create()接口创建一个顺序节点,如:“user-”节点
- 节点创建完毕后,create()接口会返回一个完整的字节名,如“user-0000000003”
- 客户端你啊到这个返回值,拼接上type类型就可以作为一个全局ID,如:“sh-user-0000000003”
在zookeeper中,每一个数据节点都能够维护一份子节点的顺序顺列,当客户端对其创建一个顺序子节点的时候,zookeeper会自动以后缀的形式在其子节点上添加一个序号。
Master选举
Master选举是一个在分布式系统常见的应用场景,分布式最核心的特性就是能够将独立计算能力的系统单元部署在不同的机器上,构成一个分布式系统,在分布式系统中,Master往往是用来协调集群中其他系统单元,具有对分布式系统状态变更的决定权,如在读写分离的应用场景中,客户端的些请求往往由Master处理,通常来说Master都会处理一些复杂的逻辑,并将结果同步给集群中的其他系统单元。
在集群中所有机器中选举一台机器作为Master,通常情况下我们可以选择常见的关系型数据库中的主键特性来实现:即集群中所有的机器都向数据库插入一条相同主键ID的记录,数据库帮助我们进行主键冲突检查,只有一个机器能够成功插入,那么这个成功插入的机器我们就可以看作是Master,但是如果Master挂了我们就无法知道并继续选举新的Master了,基于zookeeper的强一致性,保证在分布式高并发情况下节点的创建一定能够保证全局唯一性,即zookeeper将会保证客户端无法重复创建一个已经存在的数据节点,也就是说如果多个客户端请求创建同一个节点,最终只有一个客户端能够请求成功,利用这个特性可以轻松完成Master选举
具体步骤:
- 集群中的多个客户端每天定时创建一个临时节点/master_election/2020-02-02/master,只有一个客户端能够成功创建成功并且成为Master
- 同时没有创建成功的客户端都会在/master_election/2020-02-02上注册一个子节点变更的Watcher,用于监控当前Master机器是否存活,一旦Master挂了,其余客户端重新进行Master选举(即创建master节点)
基于zookeeper即可实现集群Master的动态选举。
分布式锁
分布式锁匙控制分布式系统之间同步访问共享资源的一种方式,如果不同的系统或是同一个系统不同主键之间共享一个或一组资源,那么访问这些资源的时候往往需要通过一些互斥手段保证彼此之间的干扰,以保证一致性,这时候就需要使用到分布式锁。
一般情况下,我们可以利用关系型数据库固有的排他性来实现不同进程之间的互斥(分布式锁),但是分布式系统的性能瓶颈都集中在数据库上,如果出了业务之外再添加一些额外的行锁或者表锁,使得数据库更加不堪重负,可以基于zookeeper实现分布式锁,主要分为排他锁和共享锁
排他锁
排他锁(Exclusive 简称X锁),又称为写锁或者独占锁,表明如果事务T1对数据对象O1加了排他锁,在加锁期间,只允许事务T1对O1的读取和更新,其他事务都无法对这个对象进行任何操作。
定义锁
在java中常见的排他锁有两种常见的方式:synchronized关键字和ReentrantLock对象,在zookeeper中通过一个数据节点表示一个锁,创建一个节点成功就代表加锁成功
获取锁
- zookeeper获取排他锁就是调用create()方法创建一个临时节点,比如在/exclusive_lock下创建临时子节点/exclusive_lock/lock,zookeeper会保证只有一个客户端能够创建成功,该客户端获取锁。
- 同时,在没有获取所得客户端就需要在/exclusive_lock节点上注册一个子节点变更的watcher监听,达到实时监听lock节点变更的情况
释放锁
因为在获取锁的时候创建的是要给临时节点,所以有以下两种情况会释放锁:
- 当前获取锁的客户端机器宕机,zookeeper移除这个临时节点,释放锁
- 正常执行逻辑后,客户端调用delete主动删除这个临时节点,也释放锁
无论什么情况下移除lock节点,zookeeper都会通知/exclusive_lock节点上注册Watcher监听的所有客户端,这些客户端在收到通知后重新发起获取锁的请求,重复执行!具体的流程图如下:

共享锁
共享锁(Shared Locks,简称S锁),又称读锁,表明如果事务T1对数据对象O1加上共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁,直到该数据对象上所有的共享锁都被释放
共享锁和排他锁的区别在于,加了排他锁之后数据对象只对一个事务可见,而加了共享锁的数据对所有事务可见。此外需要注意的是,对于排他锁的节点是临时节点,创建节点成功就是上锁成功,而共享锁的节点是临时顺序节点,创建节点成功后需要根据节点的操作类型和顺序来决定是否上锁成功。
定义锁:
通过zookeeper的一个数据节点表示一个锁,是一个类似于“/shared_lock/hostName-请求类型-序号”的临时顺序节点,如:创建了:/shared_lock/192.168.0.1-R-0000000001,/shared_lock/192.168.0.2-W-0000000002,这些个节点代表了共享锁。
获取锁:
获取共享锁就是所有客户端都会在/shared_lock节点下创建一个临时顺序节点,如果当前是读请求就创建如:/shared_lock/192.168.0.1-R-0000000001,如果是写请求就创建如:/shared_lock/192.168.0.2-W-0000000001的节点
判断读写顺序
根据共享锁的定义,不同的事务都可以对同一个数据对象进行都操作,而更新操作必须是在当前没有任何事务进行读写的情况下进行,基于此确定的读写顺序步骤如下:
- 创建完节点后,获取所有/shared_lock节点下所有子节点,并对该节点注册子节点变更的Watcher监听
- 确定自己在节点序号在所有子节点的顺序
- 对于都请求:如果没有比自己序号小的子节点,或所有比自己序号小的子节点都是都请求,表明成功获取锁,执行读逻辑;如果有比自己序号小的子节点中有写请求,那么就进入等待;对于写请求:如果自己不是序号最小的子节点,那么就需要进入等待
- 收到Watcher通知后,重复步骤1
释放锁:同排他锁一致
执行的流程图如下:

羊群效应:当某台机器完成读操作,并删除节点,其他机器在收到节点删除的通知后,重新在/shared_lock节点上获取一份新的子节点列表,判断自己的读写顺序,其中最小的序号的机器将获取锁,执行操作,其他的机器发现没有轮到自己读取或者更新,将继续等待。事实上所有的客户端在收到节点删除的通知,只有一个最小序号的客户端才会拿到锁,而其他的客户端基本不需要做任何操作,所以在整个分布式锁的竞争过程中,大量的"watcher通知"和子节点列表的获取都是重复无效的操作,且绝大数的客户都按判断的结果都是自己并非最小序号节点,而继续等待下一次通知。在集群规模比较大的情况下,这种情况不仅对zookeeper服务器造成巨大的性能影响和网络冲击,严重的是如果同一时间多个节点对应的客户端完成事务或者中断事务引起的节点消失,zookeeper就会在短时间内向其余客户端发送大量的事件通知,这就是所谓的
改进:只要将每个锁竞争者只关注/shared_lock节点下序号比自己小的那个节点是否存在即可,具体步骤:
- 客户端调用create()方法创建要给类似于"/shared_lock/host-请求类型-序号"的临时顺序节点
- 客户端调用getChildren()接口获取所有已经创建的子节点列表,注意,这里不注册任何watcher
- 判断读写顺序(同前),如果无法获取共享锁,那么调用exist()来对比自己小的那个节点注册watcher,这里分为读或者写请求读请求:向比自己序号小的最后一个写请求节点注册Watcher监听写请求:向比自己序号小的最后一个节点注册Watcher监听
- 等待watcher通知,重复步骤2
分布式队列
分布式队列,简单的讲究分为两大类,一种是常规的先进先出队列,另外一种则是要等到队列元素集聚之后才同意安排执行的Barrier模型
FIFO先进先出
使用zookeeper实现FIFO队列和实现共享锁的实现非常类似,FIFO队列就类似于一个全写的共享锁模型,思路如下:所有客户端都会到/queue_fifo这个节点下面创建一个临时顺序节点,如:/queue_fifo/192.168.0.1-000000001,/queue_fifo/192.168.0.2-000000002,/queue_fifo/192.168.0.3-000000003,创建完节点之后,按照4个步骤执行顺序:
- 通过调用getChildren()接口来获取/queue_fifo/节点下所有子节点,即获取队列中所有的元素
- 确定自己的节点序号在所有子节点的顺序
- 如果自己不是序号最小的子节点,那么就需要进入等待,同时比向自己序号小的最后一个节点注册watcher监听
- 接收到watcher通知后,重复步骤1
Barrier:分布式屏障
Barrier的意思是障碍物,屏障,在分布式系统中,特制系统之间的一个协调田间,规定一个队列的元素必须都集聚后才能统一安排,否则一直等待,应用在分布式并行计算上:最终的合并计算需要基于很多并行计算的自结果来进行,基于zookeeper的实现思想如下:在/queue_barrier节点的数据内容赋值为一个数字n来代表Barrier值,如n=10表示当/queue_barrier节点下的子节点个数达到10后,才会打开Barrier,所有客户端都会到/queue_barrier节点下创建一个临时节点,节点创建完后按照如下:
- 通过调用getData()接口获取/queue_barrier节点的数据内容:10
- 通过调用getChildren()接口获取/queue_barrier节点下的所有子节点,即获取队列中的所有元素,同时注册对子节点列表变更的Warcher监听
- 统计子节点的个数
- 如果子节点个数还不足10个,进入等待
- 接收到Watcher通知后,重复步骤2
Master-Worker架构
Master-Worker模式是常用的并行模式之一。它的核心思想是,系统由两类进程协作工作:Master进程和Worker进程。Master进程为主要进程,主要负责接收和分配任务,它维护了一个Worker进程队列、子任务队列和子结果集,Worker进程负责处理子任务。不停地从任务队列中提取要处理的子任务,并将子任务的处理结果写入结果集, 当各个Worker进程将子任务处理完成后,将结果返回给Master进程,由Master进程做归纳和汇总,从而得到系统的最终结果,其处理过程如图所示:
Master-Worker模式的好处,它能够将一个大任务分解成若干个小任务,并且执行,从而提高系统的吞吐量。而对于系统请求者Client来说,任务一旦提交,Master进程会分配任务并立即返回,并不会等待系统全部处理完成后再返回,其处理过程是异步的。因此Client不会出现等待现象。
需要注意的是:
- 在任何时候,系统最多只能有一个master,不可以出现两个master的情况,多个master共存会导致脑裂
- 系统中除了处于active状态的master还有一个backup master,在active master失败的时候backup master可以很快的进入active状态
- master实时监控worker状态,能够及时收到worker成员变化通知,master在收到worker成员变化通知后,通常重新进行任务分配
使用zookeeper实现master-worker架构
- 使用一个临时节点/master表示master,master在行使master的智能前,首先创建这个master的节点,如果创建成功,则进入active状态,否则的话进入backup状态,使用watch机制监控/master,在系统中存在active master和backup master的情况下,如果active master挂了,那么创建的/master节点就会被zookeeper自动删除,这时候backup master收到通知,通过再次创建/master节点成为新的active master
- worker通过在/workers下面创建临时节点加入集群
- 处于active状态的master会通过watch机制监控/workers节点下面的znode列表来实时获取worker成员的变化

Zookeeper的技术
序列化和协议
zookeeper的客户端和服务端之间会进行一系列的网络通信来实现数据的传输,对于一个网络通信,首先要解决的就是对数据的序列化和反序列化,在zookeeper中,使用Jute这一序列化组件来进行数据的序列化和反序列化操作
Jute是zookeeper中序列化组件,最初也是Hadoop中默认的序列化组件,使用Jute进行序列化和反序列化操作,如下:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class MockRequest implements Record {
private Long id;
private String type;
}
//序列化
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BinaryOutputArchive archive = BinaryOutputArchive.getArchive(baos);
new MockRequest(1L,"INT").serialize(archive,"request");
//tcp网络传输对象
ByteBuffer buffer = ByteBuffer.wrap(baos.toByteArray());
//反序列化
ByteBufferInputStream bbis = new ByteBufferInputStream(buffer);
BinaryInputArchive inArchive = BinaryInputArchive.getArchive(bbis);
MockRequest mockRequest = new MockRequest();
mockRequest.deserialize(inArchive,"request");
bbis.close();
baos.close();上述代码实现对MockRequest对象的序列化和反序列化,总的来说分为4步:
- 实体类需要实现Record接口的serialize和deserialize方法
- 构建一个序列化其BinaryOutputArchive
- 执行序列化,调用实体类的serialize方法,将其对象序列化到指定的tag中去,如上的将MockRequest对象序列化到header中去
- 执行反序列化,调用实体类的deserialize,从指定的tag中反序列化出数据内容
zookeeper客户端
zookeeper客户端是开发人员使用zookeeper的最主要的途径,zookeeper的客户端主要由以下以下几个核心组件组成
Zookeeper实例:客户端入口
ClientWatcherManager:客户端Watcher管理器
HostProvider:客户端地址列表管理器
ClientCnxn:客户端地址列表管理器:客户端核心线程,内部包含两个线程,即SendThread和EventThread,前者是一个I/O线程,主要负责Zookeeper客户端与服务端的I/O通信,后者是一个事件线程,主要负责对服务端事件进行处理
zookeeper客户端的初始化和启动环节,实际上就是zookeeper对象的实例化过程,客户端的整个初始化和启动过程大体分为以下3个步骤:
- 设置默认的Watcher
- 设置Zookeeper的服务器地址列表
- 创建ClientCnxn
如果在zookeeper的构造方法中传入一个Watcher对象的话,那么zookeeper就会将这个Watcher对象保存在ZKWatcherManager的defaultWatcher中,作为整个客户端会话期间默认的Watcher
一次会话的创建过程:主要分为3个阶段:
初始化阶段-会话创建阶段-响应处理阶段
初始化阶段:
- 初始化Zookeeper对象,通过调用Zookeeper的构造方法来实例化一个zookeeper对象,在初始化过程中会创建一个客户端的Watcher管理器:ClientWatchManager
- 设置会话默认的Watcher,如果传入一个Watcher,就会将他作为默认的Watcher保存在ClientWatcherManager中
- 构造Zookeeper服务器地址列表管理器:HostProvider,对于在构造方法中传入服务器地址,客户端会将其存放在服务器地址列表管理器HostProvider中
- 创建并初始化客户端网络连接器:ClientCnxn,用来管理客户端和服务端的网络交互,在创建ClientCnxn的同时,还会初始化两个核心队列outgoingQueue和pendingQueue,分别作为客户端的请求发送队列和服务端响应的等待队列
- 客户端还会初始化SendThread和EventThread,分别用来管理客户端和服务端之间的所有网络I/O和进行客户端的事件处理,同时客户端将ClientCnxnSocket分配给SendThread作为底层网络I/O处理器,并初始化EventThread的待处理事件队列waitingEvents,用于存放所有等待被客户端处理的事件。
会话创建阶段
- 启动SendThread和EventThread,SendThread首先会判断当前客户端的状态,进行一些了的清理工作,为客户端发送“会话创建”请求做准备
- 获取一个服务器地址,在开始创建TCP连接之前,SendThread首先需要获取一个Zookeeper服务器的目标地址,通常是从HostProvider中随机获取一个地址,然后委托给ClientCnxnSocket去创建与zookeeper服务器之间的TCP连接
- 获取一个服务器地址后,ClientCnxnSocket负责和服务器创建一个TCP长连接
- 构造ConeentRequest请求,上面的步骤只是纯粹的从网络TCP 层面完成客户端和服务端之间的Socket连接,但还没完成Zookeeper客户端会话的创建,SendThread会负责根据当前客户端的实际设置构造出一个ConnectRequest请求,代表客户端与服务器之间创建的一个会话,同时Zookeeper客户端还会进一步将带请求包装成网络I/O层的Packet对象,放入请求发送队列OutgoingQueue中去
- 发送请求,在准备完毕后,就开始向服务端发送请求了,ClientCnxnSocket负责从outgoingQueue中取出一个待发送的Packet对象,将其序列化成ByteBuffer,向服务端进行发送
响应处理阶段
接收服务端的响应,ClientCnxnSocket接收到服务端的响应后,会首先判断当前客户端的状态是否是“已初始化”,如果尚未完成初始化,则认定该响应一个是会话创建请求的响应,直接交给readConnectResult方法来处理该响应
处理Response,ClientCnxnSocket会首先接收服务端的响应进行反序列化,得到ConnectResponse对象,从中获取到zookeeper服务端分配的会话sessionId
连接成功后,一方面通知SendThread线程,进一步对客户端进行会话参数设置,包括readTimeout和connectTimeout等,并更新客户端的状态,另一方面,通知地址管理器HostProvider当前成功连接的服务器地址
生成事件:SyncConnected-None,为了能够让上层应用感知会话创建成功,SendThread会生成一个事件SyncConnected-None,代表客户端和服务器会话创建成功,并将该事件传递给EventThread线程
查询Watcher,在EventThread线程收到事件后,会从ClientWatcherManager管理器中查询对应的Watcher,针对SyncConnected-Node事件,找到存储的默认Watcher,然后将其放到EventThread的waitingEvents队列中去
处理时间,EventThread不断的从waitingEvents队列中取出待处理的Watcher对象,然后直接调用该对象的process接口方法,触发Watcher
密















 3081
3081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









