







 本文探讨了编译器优化导致的编译乱序问题及其解决方案,并介绍了处理器执行时可能产生的执行乱序现象。通过具体示例展示了如何使用编译屏障避免编译乱序,同时讨论了内存屏障指令在解决执行乱序中的作用。
本文探讨了编译器优化导致的编译乱序问题及其解决方案,并介绍了处理器执行时可能产生的执行乱序现象。通过具体示例展示了如何使用编译屏障避免编译乱序,同时讨论了内存屏障指令在解决执行乱序中的作用。
往期链接:
本期主题:
编译乱序和执行乱序
1.从实际例子引出编译乱序
1.为什么会有编译乱序?
编译器的工作就是帮我们优化代码性能,在不改变程序行为的情况下重新排序一些指令。但是有一个关键问题在于,编译器并不知道什么代码需要关注线程安全,它只会按照单线程的方式来处理这些指令,所以这样就存在了编译乱序的问题,因此,我们如果清楚知道哪些代码不应该被优化,我们就需要明确的告诉编译器。
看实际例子:
int a, b;
#define barrier() __asm__ __volatile__("": : :"memory")
void test_func(void)
{
a = b + 1;
b = 0;
}
int main(void)
{
test_func();
return 0;
}
gcc默认为O0编译,我们先看下O0编译完之后的目标文件反汇编的结果:
jason@ubuntu:~/WorkSpace/2.Linux_Driver/1.compile$ arm-none-linux-gnueabi-gcc -O0 main.c
jason@ubuntu:~/WorkSpace/2.Linux_Driver/1.compile$ arm-none-linux-gnueabi-objdump -d a.out > O0.asm
O0反汇编的结果表明与代码是一致的,没有乱序
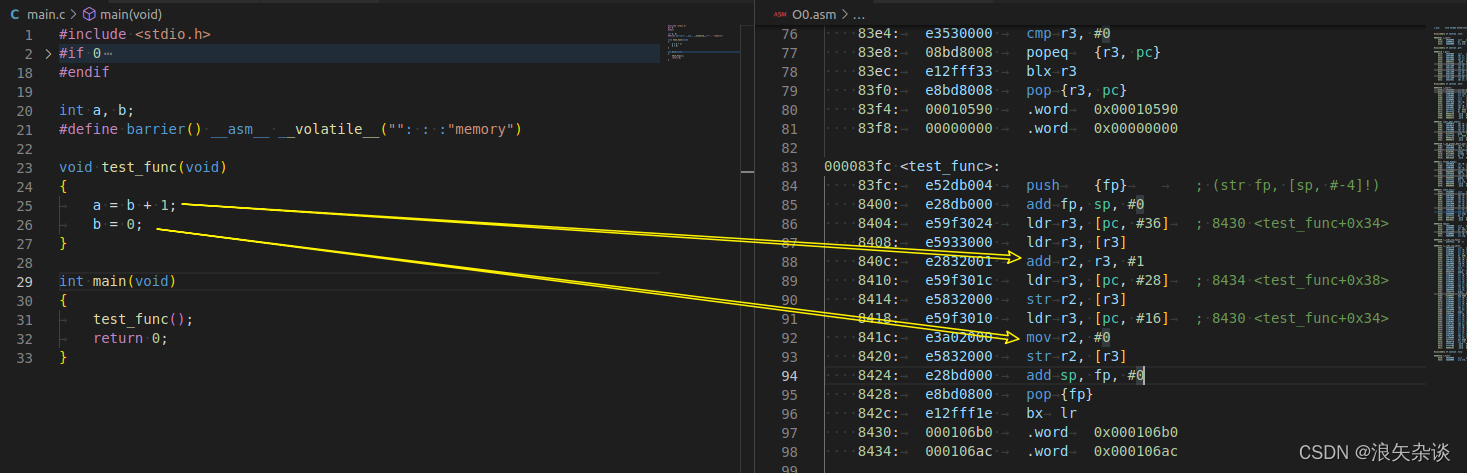
用同样的方式测试O2优化过后的结果:
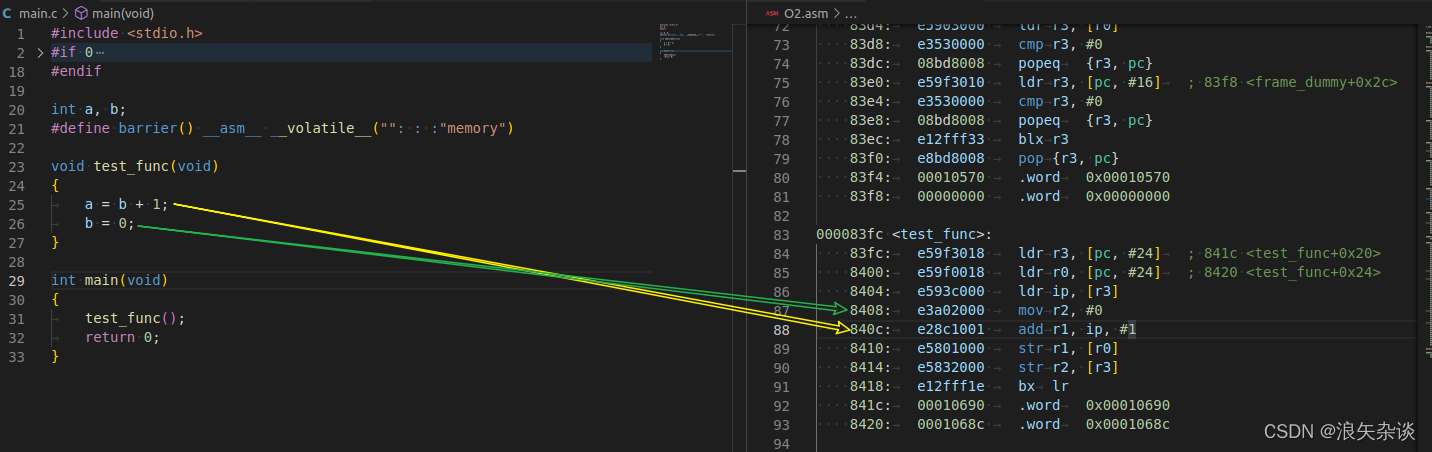
发现经过O2优化的代码,反汇编出来的指令执行顺序有改变,这是编译器的优化结果。
2.编译屏障barrier()设置
可以使用编译屏障barrier()来保证上述指令不会被优化。
__asm__表示这是内嵌汇编,内嵌汇编的语法如下:__asm__(汇编语句模板: 输出部分: 输入部分: 描述部分),其中memory描述表示直接从内存取,而不要用原来寄存器中的缓存;有一篇文章关于内嵌汇编讲得比较好 gcc内嵌汇编简单介绍- 需要注意的是,C语言内的volatile关键字和这个意义并不完全相同,C语言的volatile主要是避免了内存访问的合并行为,告诉了编译器,这个变量是有可能被外部修改的,因此需要重新读一下,不能用寄存器中的缓存值;

实验验证,添加了barrier()之后,O2编译的顺序也是正确的
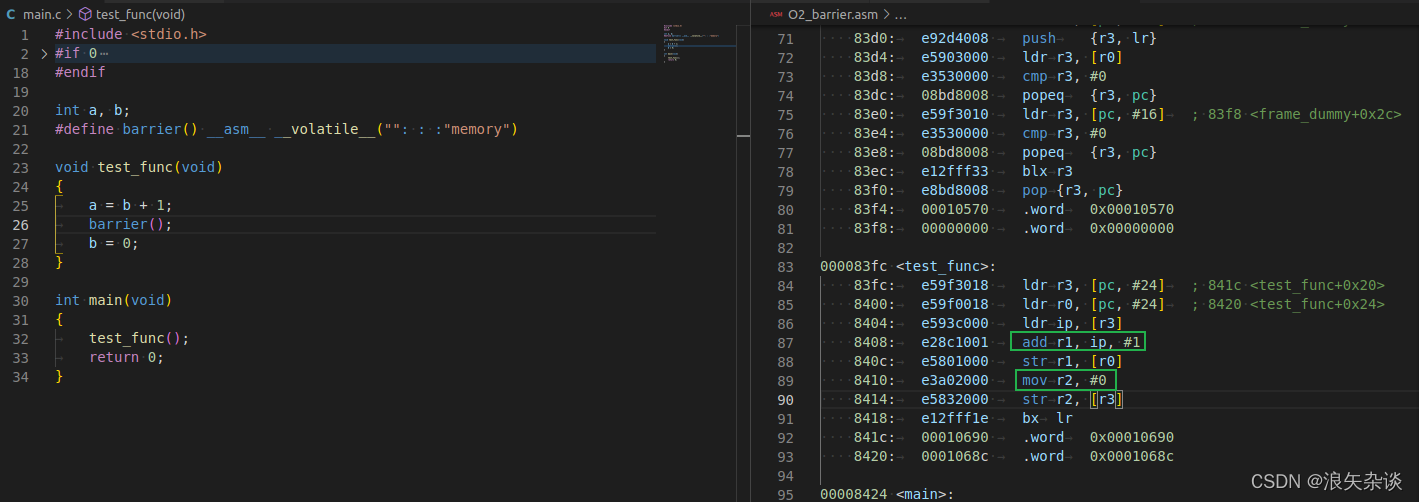
2.执行乱序
编译乱序是编译器的优化行为,而执行乱序是处理器运行时的行为。
高级的CPU会根据自己处理器的缓存特性,将访问、存储指令重新排序,例如连续地址的访问可能会先执行,因为这样缓存的效率会更高。
因此有一个结论:
即便是编译顺序看起来正确的指令,其在处理器上的执行顺序也是未知的。
所以当我们遇到这种问题时,可以从这个方面进行考虑。
尤其是在SMP处理器上,可能存在这种问题,因为一个核的内存行为对另外一个核是可见的,在IPC通信时,这种可见可能会导致一些意想不到的情况发生。
因此处理器为了解决这种问题,引入了一些内存屏障的指令。
例如ARM处理器的内存屏障指令:
- DMB(数据内存屏障):在DMB之后的显式内存访问执行前,保证所有在DMB指令之前的内存访问完成
- DSB(数据同步屏障):等待所有在DSB指令之前的指令完成(位于此指令前的所有显式内存访问均完成,位于此指令前的所有缓存、跳转预测和TLB维护操作全部完成)
- ISB(指令同步屏障):Flush流水线,使得所有ISB之后执行的指令都是从缓存或内存中获得的

















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









