







开始写爬虫前,我们先来分析一下该网站https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
的页面结构,网页的左侧是教程的目录大纲,每个 URL 对应到右边的一篇文章,右侧上方是文章的标题,中间是文章的正文部分,正文内容是我们关心的重点,我们要爬的数据就是所有网页的正文部分,下方是用户的评论区,评论区对我们没什么用,所以可以忽略它。
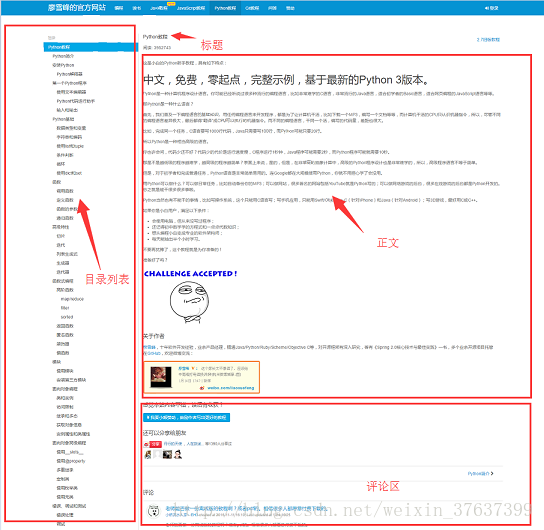
工具准备
弄清楚了网站的基本结构后就可以开始准备爬虫所依赖的工具包了。requests、beautifulsoup 是爬虫两大神器,reuqests 用于网络请求,beautifusoup 用于操作 html 数据。有了这两把梭子,干起活来利索,scrapy 这样的爬虫框架我们就不用了,小程序派上它有点杀鸡用牛刀的意思。此外,既然是把 html 文件转为 pdf,那么也要有相应的库支持, wkhtmltopdf 就是一个非常好的工具,它可以用适用于多平台的 html 到 pdf 的转换,pdfkit 是 wkhtmltopdf 的Python封装包。首先安装好下面的依赖包,接着安装 wkhtmltopdf
pip install requests
pip install beautifulsoup
pip install pdfkit
安装 wkhtmltopdf
Windows平台直接在 wkhtmltopdf 官网[2]下载稳定版的进行安装,安装完成之后把该程序的执行路径加入到系统环境 $PATH 变量中,否则 pdfkit 找不到 wkhtmltopdf 就出现错误 “No wkhtmltopdf executable found”。Ubuntu 和 CentOS 可以直接用命令行进行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









