







文章目录
Convolution Layers
卷积层主要有卷积、转置卷积(一种特殊的卷积)以及用于实现卷积的 Fold()、Unfold()。
nn.Conv1d | Applies a 1D convolution over an input signal composed of several input planes. |
|---|---|
nn.Conv2d | Applies a 2D convolution over an input signal composed of several input planes. |
nn.Conv3d | Applies a 3D convolution over an input signal composed of several input planes. |
nn.ConvTranspose1d | Applies a 1D transposed convolution operator over an input image composed of several input planes. |
nn.ConvTranspose2d | Applies a 2D transposed convolution operator over an input image composed of several input planes. |
nn.ConvTranspose3d | Applies a 3D transposed convolution operator over an input image composed of several input planes. |
nn.Unfold | Extracts sliding local blocks from a batched input tensor. |
nn.Fold | Combines an array of sliding local blocks into a large containing tensor. |
nn.Conv2d
卷积函数的参数都差不多,这里以二维卷积为例说明。
torch.nn.Conv2d(in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int, int]],
stride: Union[int, Tuple[int, int]] = 1,
padding: Union[int, Tuple[int, int]] = 0,
dilation: Union[int, Tuple[int, int]] = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = 'zeros')
- in_channels:输入通道数
- out_channels:输出通道数,等价于卷积核个数
- kernel_size:卷积核尺寸
- stride:步长
- padding:填充个数,默认填充 0.
- dilation:空洞卷积设置,用于控制内核点之间的距离。
- groups:分组卷积设置
- bias:偏置
一些说明:
1、
kernel_size, stride, padding, dilation 的参数设置
- 可以是 a single int,比方说 3,这样卷积核就是 3 × 3 3\times 3 3×3
- 也可以是 a tuple of two ints – in which case, the first int is used for the height dimension, and the second int for the width dimension(注:如果是三维卷积则是 a tuple of three ints)
2、
这里介绍一下空洞卷积(Dilated Convolution)。
空洞卷积的一个作用就是扩大 kernel 的感受野,但保持 kenel 的参数数量不变。
dilation 默认等于 1。如下图,是 dilation = 2 时,
3
∗
3
3* 3
3∗3 卷积核的示意图,可以看到,参数仍是 9 个,但感受野为
5
×
5
5\times 5
5×5。

3、
下面介绍一下用于分组卷积的参数 groups。
groups 控制了输入输出之间的连接(connections)的数量。in_channels 和 out_channels 必须能被 groups 整除。举个栗子,
-
当 groups=1, 即普通卷积。此 Conv2d 层会使用一个卷积层进行所有输入到输出的卷积操作。
-
当 groups=2, 此时 Conv2d 层会产生两个并列的卷积层。同时,输入通道被分为两半,两个卷积层分别处理一半的输入通道,同时各自产生一半的输出通道。最后这两个卷积层的输出会被 concatenated 一起,作为此 Conv2d 层的输出。
-
当 groups=
in_channels, 每个输入通道都会被单独的一组卷积层处理。
group conv 最早出现在 AlexNet[1] 中,因为显卡显存不够,只好把网络分在两块卡里,于是产生了这种结构;Alex 认为 group conv 的方式能够增加 filter 之间的对角相关性,而且能够减少训练参数,不容易过拟合,这类似于正则的效果 [2]。
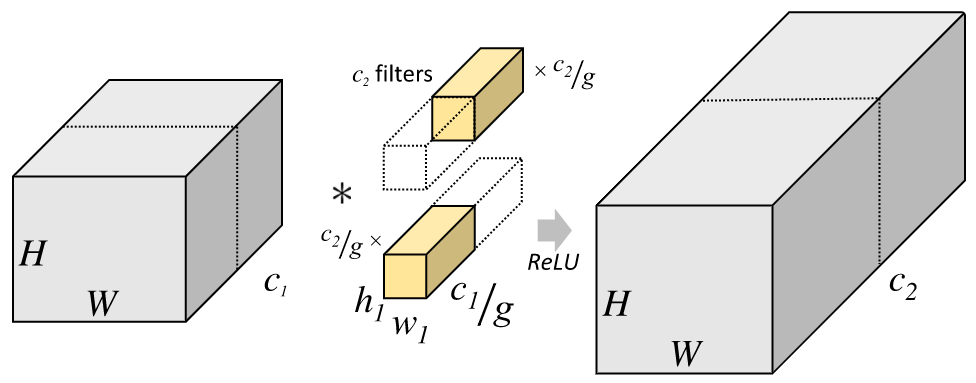
图片来源:https://blog.yani.io/filter-group-tutorial/
图片注释:A convolutional layer with 2 filter groups. Note that each of the filters in the grouped convolutional layer is now exactly half the depth, i.e. half the parameters and half the compute as the original filter.
注意:在上图中,C1 表示的是 input channel 数量,depth 默认省略。
此处参考:https://www.zhihu.com/question/60484190/answer/308079202。
4、
最后一个参数 bias:当 bias=True,则在卷积后得到的 feature map 会加上一个偏置 b,这是一个标量,由模型自动学习。
nn.Fold 和 nn.Unfold
滑动操作在大多数的深度学习框架中,都被封装的很好,以至于我们并不需要显式地调用便可以实现卷积网络的这个操作。但 Pytorch 也提供了这个 API。
简单说,Conv = Unfold + matmul + Fold。
这个 Unfold(展开)就相当于把卷积运算转换为矩阵运算的过程。这也正是卷积核 “滑动” 的本质。
如下,4x4 的输入,卷积 Kernel 为 3x3,no Padding,no Stride, 则输出为 2x2。

输入矩阵可展开为 16 维向量,记作
x
x
x
输出矩阵可展开为 4 维向量,记作
y
y
y
卷积运算可表示为
y
=
C
x
y=Cx
y=Cx
不难想象 C C C 其实就是如下的稀疏阵:
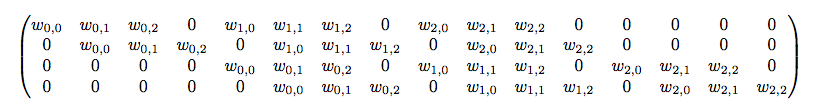
卷积神经网络中的正向传播就是转换成了如上矩阵运算。
本节参考:https://blog.csdn.net/LoseInVain/article/details/88139435。
Pooling layers
官方实现的池化层大概分以下几种
- MaxPool:最大池化
- AvgPool:平均池化
- LPPool:正则池化
- FractionalMaxPool:分数阶最大池化(一种新的池化方法,可参考 Ben Graham 等人的 paper)
- MaxUnpool:最大反池化
- AdaptivePool:自适应池化
nn.MaxPool1d | Applies a 1D max pooling over an input signal composed of several input planes. |
|---|---|
nn.MaxPool2d | Applies a 2D max pooling over an input signal composed of several input planes. |
nn.MaxPool3d | Applies a 3D max pooling over an input signal composed of several input planes. |
nn.MaxUnpool1d | Computes a partial inverse of MaxPool1d. |
nn.MaxUnpool2d | Computes a partial inverse of MaxPool2d. |
nn.MaxUnpool3d | Computes a partial inverse of MaxPool3d. |
nn.AvgPool1d | Applies a 1D average pooling over an input signal composed of several input planes. |
nn.AvgPool2d | Applies a 2D average pooling over an input signal composed of several input planes. |
nn.AvgPool3d | Applies a 3D average pooling over an input signal composed of several input planes. |
nn.FractionalMaxPool2d | Applies a 2D fractional max pooling over an input signal composed of several input planes. |
nn.LPPool1d | Applies a 1D power-average pooling over an input signal composed of several input planes. |
nn.LPPool2d | Applies a 2D power-average pooling over an input signal composed of several input planes. |
nn.AdaptiveMaxPool1d | Applies a 1D adaptive max pooling over an input signal composed of several input planes. |
nn.AdaptiveMaxPool2d | Applies a 2D adaptive max pooling over an input signal composed of several input planes. |
nn.AdaptiveMaxPool3d | Applies a 3D adaptive max pooling over an input signal composed of several input planes. |
nn.AdaptiveAvgPool1d | Applies a 1D adaptive average pooling over an input signal composed of several input planes. |
nn.AdaptiveAvgPool2d | Applies a 2D adaptive average pooling over an input signal composed of several input planes. |
nn.AdaptiveAvgPool3d | Applies a 3D adaptive average pooling over an input signal composed of several input planes. |
nn.MaxPool2d
池化函数的参数都差不多,这里以二维最大池化为例说明。
torch.nn.MaxPool2d(kernel_size: Union[int, Tuple[int, ...]],
stride: Union[int, Tuple[int, ...], None] = None,
padding: Union[int, Tuple[int, ...]] = 0,
dilation: Union[int, Tuple[int, ...]] = 1,
return_indices: bool = False,
ceil_mode: bool = False)
- kernel_size:池化核尺寸
- stride:滑动步长,默认值是
kernel_size,即不重叠池化 - padding:填充个数
- dilation:池化核间隔大小
- ceil_mode:输出信号向上取整。当
ceil_mode=False,向下取整。 - return_indices:记录池化像素索引(搭配反池化使用,后面会介绍)
nn.AvgPool2d
torch.nn.AvgPool2d(kernel_size: Union[int, Tuple[int, int]],
stride: Union[int, Tuple[int, int], None] = None,
padding: Union[int, Tuple[int, int]] = 0,
ceil_mode: bool = False,
count_include_pad: bool = True,
divisor_override: bool = None)
- count_include_pad:填充值是否参与计算
- divisor override:除法因子(设置后不再除以池化核尺寸大小,而是除法因子)
nn.MaxUnpool2d
对二维信号(图像)进行最大值池化上采样
torch.nn.MaxUnpool2d(kernel_size: Union[int, Tuple[int, int]],
stride: Union[int, Tuple[int, int], None] = None,
padding: Union[int, Tuple[int, int]] = 0)
- kernel_size:池化核尺寸
- stride:步长
- padding:填充个数
上采样要记录最大值的索引,所以在forward的时候需要传入index参数。
下面给出一个反池化的使用例子。
>>> pool = nn.MaxPool2d(2, stride=2, return_indices=True)
>>> unpool = nn.MaxUnpool2d(2, stride=2)
>>> input = torch.tensor([[[[ 1., 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[13, 14, 15, 16]]]])
>>> output, indices = pool(input)
>>> unpool(output, indices)
tensor([[[[ 0., 0., 0., 0.],
[ 0., 6., 0., 8.],
[ 0., 0., 0., 0.],
[ 0., 14., 0., 16.]]]])
>>> # specify a different output size than input size
>>> unpool(output, indices, output_size=torch.Size([1, 1, 5, 5]))
tensor([[[[ 0., 0., 0., 0., 0.],
[ 6., 0., 8., 0., 0.],
[ 0., 0., 0., 14., 0.],
[ 16., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.]]]])
nn.AdaptiveMaxPool2d
自适应池化,比如说自适应二维最大池化,本质上和二维最大池化并没有区别,只是简化了要输入的参数。这种思想类似于 reshape(3, -1) 中的 -1。
下面给出一个自适应池化的例子。
>>> # target output size of 5x7
>>> m = nn.AdaptiveMaxPool2d((5,7))
>>> input = torch.randn(1, 64, 8, 9)
>>> output = m(input)
>>> # target output size of 7x7 (square)
>>> m = nn.AdaptiveMaxPool2d(7)
>>> input = torch.randn(1, 64, 10, 9)
>>> output = m(input)
>>> # target output size of 10x7
>>> m = nn.AdaptiveMaxPool2d((None, 7))
>>> input = torch.randn(1, 64, 10, 9)
>>> output = m(input)
Padding Layers
官方实现的 Padding 类型
- ReflectionPad:镜像填充
- ReplicationPad:复制填充
- ZeroPad:零填充
- ConstantPad:常数填充
nn.ReflectionPad1d | Pads the input tensor using the reflection of the input boundary. |
|---|---|
nn.ReflectionPad2d | Pads the input tensor using the reflection of the input boundary. |
nn.ReplicationPad1d | Pads the input tensor using replication of the input boundary. |
nn.ReplicationPad2d | Pads the input tensor using replication of the input boundary. |
nn.ReplicationPad3d | Pads the input tensor using replication of the input boundary. |
nn.ZeroPad2d | Pads the input tensor boundaries with zero. |
nn.ConstantPad1d | Pads the input tensor boundaries with a constant value. |
nn.ConstantPad2d | Pads the input tensor boundaries with a constant value. |
nn.ConstantPad3d | Pads the input tensor boundaries with a constant value. |
Non-linear Activations (weighted sum, nonlinearity)
这部分推荐看官方 Documentation,有图有公式。
nn.ELU | Applies the element-wise function: |
|---|---|
nn.Hardshrink | Applies the hard shrinkage function element-wise: |
nn.Hardsigmoid | Applies the element-wise function: |
nn.Hardtanh | Applies the HardTanh function element-wise |
nn.Hardswish | Applies the hardswish function, element-wise, as described in the paper: |
nn.LeakyReLU | Applies the element-wise function: |
nn.LogSigmoid | Applies the element-wise function: |
nn.MultiheadAttention | Allows the model to jointly attend to information from different representation subspaces. |
nn.PReLU | Applies the element-wise function: |
nn.ReLU | Applies the rectified linear unit function element-wise: |
nn.ReLU6 | Applies the element-wise function: |
nn.RReLU | Applies the randomized leaky rectified liner unit function, element-wise, as described in the paper: |
nn.SELU | Applied element-wise, as: |
nn.CELU | Applies the element-wise function: |
nn.GELU | Applies the Gaussian Error Linear Units function: |
nn.Sigmoid | Applies the element-wise function: |
nn.Softplus | Applies the element-wise function: |
nn.Softshrink | Applies the soft shrinkage function elementwise: |
nn.Softsign | Applies the element-wise function: |
nn.Tanh | Applies the element-wise function: |
nn.Tanhshrink | Applies the element-wise function: |
nn.Threshold | Thresholds each element of the input Tensor. |
Non-linear Activations (other)
nn.Softmin | Applies the Softmin function to an n-dimensional input Tensor rescaling them so that the elements of the n-dimensional output Tensor lie in the range [0, 1] and sum to 1. |
|---|---|
nn.Softmax | Applies the Softmax function to an n-dimensional input Tensor rescaling them so that the elements of the n-dimensional output Tensor lie in the range [0,1] and sum to 1. |
nn.Softmax2d | Applies SoftMax over features to each spatial location. |
nn.LogSoftmax | Applies the \log(\text{Softmax}(x))log(Softmax(x)) function to an n-dimensional input Tensor. |
nn.AdaptiveLogSoftmaxWithLoss | Efficient softmax approximation as described in Efficient softmax approximation for GPUs by Edouard Grave, Armand Joulin, Moustapha Cissé, David Grangier, and Hervé Jégou. |
Normalization Layers
目前的标准化层有
- BatchNorm:批标准化
- GroupNorm:组标准化
- InstanceNorm:实例标准化
- LayerNorm:层标准化
- SyncBatchNorm:同步批标准化
- LocalResponseNorm:局部响应标准化
nn.BatchNorm1d | Applies Batch Normalization over a 2D or 3D input (a mini-batch of 1D inputs with optional additional channel dimension) as described in the paper Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift . |
|---|---|
nn.BatchNorm2d | Applies Batch Normalization over a 4D input (a mini-batch of 2D inputs with additional channel dimension) as described in the paper Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift . |
nn.BatchNorm3d | Applies Batch Normalization over a 5D input (a mini-batch of 3D inputs with additional channel dimension) as described in the paper Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift . |
nn.GroupNorm | Applies Group Normalization over a mini-batch of inputs as described in the paper Group Normalization |
nn.SyncBatchNorm | Applies Batch Normalization over a N-Dimensional input (a mini-batch of [N-2]D inputs with additional channel dimension) as described in the paper Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift . |
nn.InstanceNorm1d | Applies Instance Normalization over a 3D input (a mini-batch of 1D inputs with optional additional channel dimension) as described in the paper Instance Normalization: The Missing Ingredient for Fast Stylization. |
nn.InstanceNorm2d | Applies Instance Normalization over a 4D input (a mini-batch of 2D inputs with additional channel dimension) as described in the paper Instance Normalization: The Missing Ingredient for Fast Stylization. |
nn.InstanceNorm3d | Applies Instance Normalization over a 5D input (a mini-batch of 3D inputs with additional channel dimension) as described in the paper Instance Normalization: The Missing Ingredient for Fast Stylization. |
nn.LayerNorm | Applies Layer Normalization over a mini-batch of inputs as described in the paper Layer Normalization |
nn.LocalResponseNorm | Applies local response normalization over an input signal composed of several input planes, where channels occupy the second dimension. |
BatchNorm
y
=
x
−
E
(
x
)
V
a
r
(
x
)
+
ϵ
∗
α
+
β
y=\frac{x-E(x)}{\sqrt {Var(x)+\epsilon}}*\alpha+\beta
y=Var(x)+ϵx−E(x)∗α+β
BatchNorm 系列的函数参数相同,区别在于调用时传入张量的维度。
但不管输入的张量的维度如何,输出的张量的维度 = 输入张量的维度。因为 Norm 是一种数据校准,并不会改变数据维度。
所谓 BN,其实就是
下面依次介绍 1D、2D、3D。
torch.nn.BatchNorm1d(num_features,
eps=1e-05,
momentum=0.1,
affine=True,
track_running_stats=True)
- num_features:一个样本的特征数量
- eps:防止分母为零,默认 eps=1e-5
- momentum:指数加权平均估计当前 mean/var,默认 momentum=0.1
- affine:是否需要 affine transform,默认是 True。为 True 时,仿射函数中的 α , β \alpha,\beta α,β 由框架自动学习。
- track_running_stats:是训练状态(True),还是测试状态(False)
Shape:
-
Input: (N, C) or (N, C, L)
-
Output: (N, C) or (N, C, L) (same shape as input)
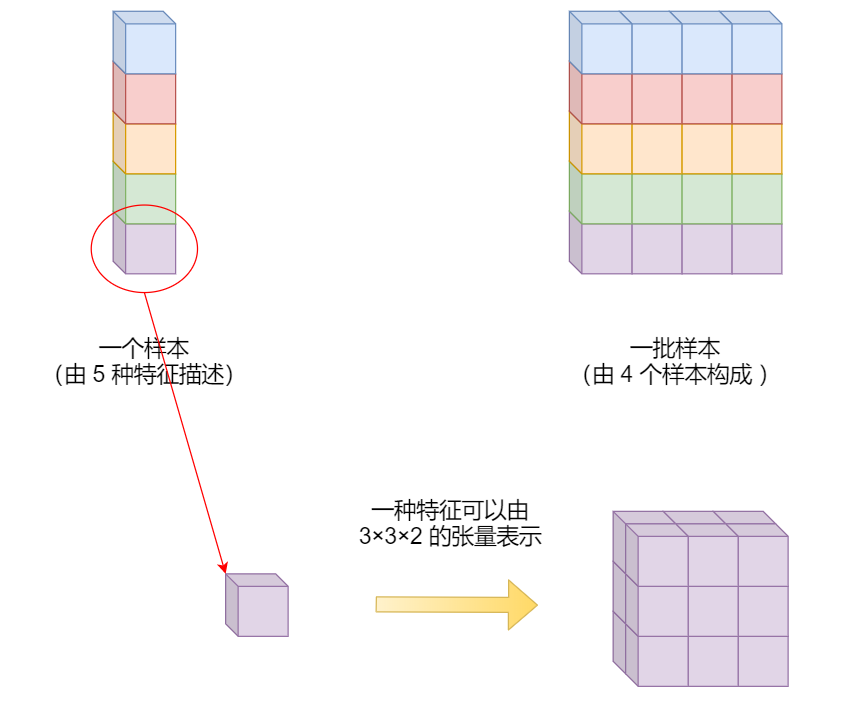
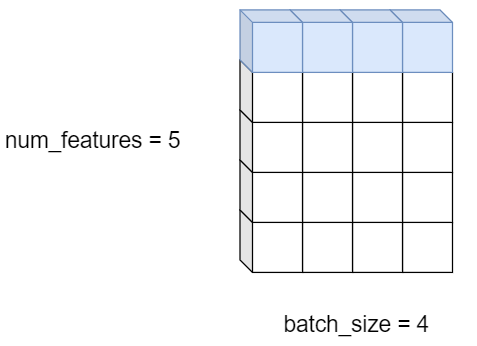
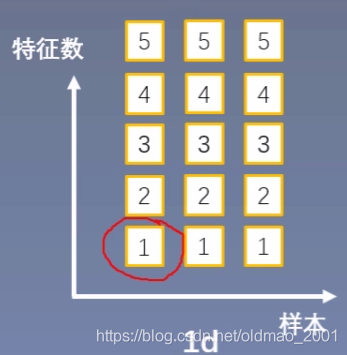
注:N,C,L 分别代表 batch_size、features_num、feature_dim。
如下图,(N, C, L) = (3, 5, 1),即 batch_size 为 3,一个样本有 5 种特征,每种特征用 1x1 的矩阵描述。因为特征的维度为 1,因此也可以省略 1,从而写成 (N, C) = (3, 5)。
torch.nn.BatchNorm2d(num_features,
eps=1e-05,
momentum=0.1,
affine=True,
track_running_stats=True)
Shape:
-
Input: (N, C, H, W)
-
Output: (N, C, H, W)
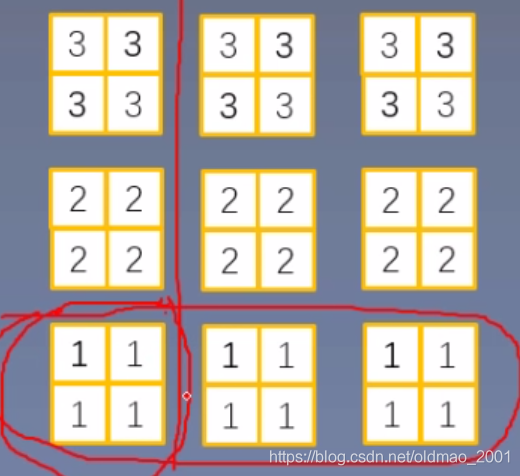
如下图,input_shape 为 (3, 3, 2, 2),即 batch_size 为 3,一个样本有 3 种特征,每种特征用 2x2 的矩阵描述。
torch.nn.BatchNorm3d(num_features,
eps=1e-05,
momentum=0.1,
affine=True,
track_running_stats=True)
Shape:
-
Input: (N, C, D, H, W)
-
Output: (N, C, D, H, W)
如下图,input_shape 为 (3, 4, 2, 2, 3),即 batch_size 为 3,一个样本有 4 种特征,每种特征用 2x2x3 的矩阵描述。

Recurrent Layers
nn.RNNBase | |
|---|---|
nn.RNN | Applies a multi-layer Elman RNN with \tanhtanh or \text{ReLU}ReLU non-linearity to an input sequence. |
nn.LSTM | Applies a multi-layer long short-term memory (LSTM) RNN to an input sequence. |
nn.GRU | Applies a multi-layer gated recurrent unit (GRU) RNN to an input sequence. |
nn.RNNCell | An Elman RNN cell with tanh or ReLU non-linearity. |
nn.LSTMCell | A long short-term memory (LSTM) cell. |
nn.GRUCell | A gated recurrent unit (GRU) cell |
Transformer Layers
nn.Transformer | A transformer model. |
|---|---|
nn.TransformerEncoder | TransformerEncoder is a stack of N encoder layers |
nn.TransformerDecoder | TransformerDecoder is a stack of N decoder layers |
nn.TransformerEncoderLayer | TransformerEncoderLayer is made up of self-attn and feedforward network. |
nn.TransformerDecoderLayer | TransformerDecoderLayer is made up of self-attn, multi-head-attn and feedforward network. |
Linear Layers
nn.Identity | A placeholder identity operator that is argument-insensitive. |
|---|---|
nn.Linear | Applies a linear transformation to the incoming data: y = x A T + b y = xA^T + b y=xAT+b |
nn.Bilinear | Applies a bilinear transformation to the incoming data: y = x 1 T A x 2 + b y = x_1^T A x_2 + b y=x1TAx2+b |
Dropout Layers
nn.Dropout | During training, randomly zeroes some of the elements of the input tensor with probability p using samples from a Bernoulli distribution. |
|---|---|
nn.Dropout2d | Randomly zero out entire channels (a channel is a 2D feature map, e.g., the jj -th channel of the ii -th sample in the batched input is a 2D tensor \text{input}[i, j]input[i,j] ). |
nn.Dropout3d | Randomly zero out entire channels (a channel is a 3D feature map, e.g., the jj -th channel of the ii -th sample in the batched input is a 3D tensor \text{input}[i, j]input[i,j] ). |
nn.AlphaDropout | Applies Alpha Dropout over the input. |
Sparse Layers
nn.Embedding | A simple lookup table that stores embeddings of a fixed dictionary and size. |
|---|---|
nn.EmbeddingBag | Computes sums or means of ‘bags’ of embeddings, without instantiating the intermediate embeddings. |
Vision Layers
nn.PixelShuffle | Rearranges elements in a tensor of shape (, C \times r^2, H, W)(∗,C×r2,H,W) to a tensor of shape (, C, H \times r, W \times r)(∗,C,H×r,W×r) . |
|---|---|
nn.Upsample | Upsamples a given multi-channel 1D (temporal), 2D (spatial) or 3D (volumetric) data. |
nn.UpsamplingNearest2d | Applies a 2D nearest neighbor upsampling to an input signal composed of several input channels. |
nn.UpsamplingBilinear2d | Applies a 2D bilinear upsampling to an input signal composed of several input channels. |
DataParallel Layers (multi-GPU, distributed)
nn.DataParallel | Implements data parallelism at the module level. |
|---|---|
nn.parallel.DistributedDataParallel | Implements distributed data parallelism that is based on torch.distributed package at the module level. |
Convolution layers 卷积层
关于各种卷积的动图演示:https://github.com/vdumoulin/conv_arithmetic
API 结构:

参考文献
[1] https://blog.csdn.net/oldmao_2001/article/details/102844727
[2] 什么是「Grouped Convolution」? - 无痕的回答 - 知乎















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









