







1.Hbase的数据类型


Rowkey
与nosql数据库们一样,row key是用来检索记录的主键。访问HBASE table中的行,只有三种方式:
1.通过单个row key访问
2.通过row key的range(正则)
3.全表扫描
Row key行键 (Row key)可以是任意字符串(最大长度 是 64KB,实际应用中长度一般为 10-100bytes),在HBASE内部,row key保存为字节数组。存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
列簇:
HBASE表中的每个列,都归属于某个列族。列族是表的schema的一部 分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如 courses:history,courses:math都属于courses 这个列族
列:
由{row key, columnFamily, version} 唯一确定的单元。cell中 的数据是没有类型的,全部是字节码形式存贮。
关键字:无类型、字节码
时间戳:
HBASE 中通过rowkey和columns确定的为一个存贮单元称为cell。每个 cell都保存 着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由HBASE(在数据写入时自动 )赋值,此时时间戳是精确到毫秒 的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版 本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBASE提供 了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段 时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
2. Hbase命令
hbase shell进入:

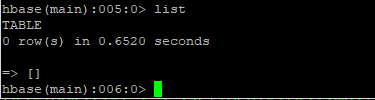
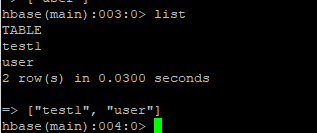
查看表:list
创建一个表:


查看表结构:

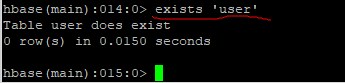
判断表是否存在:
删除表: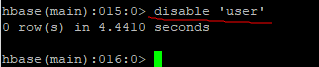

添加纪录:

除了scan全表扫描以外,还可以单条查询数据:
查询记录rowkey下所有的记录:
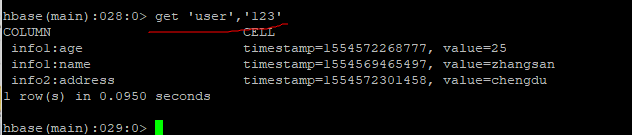
获取某个列族:

删除数据:
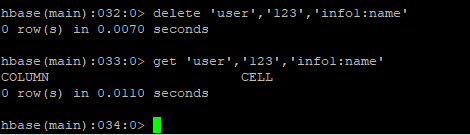
删除整行:

相关命令:
| 名称 | 命令表达式 |
| 创建表 | create '表名', '列族名1','列族名2','列族名N' |
| 查看所有表 | list |
| 描述表 | describe ‘表名’ |
| 判断表存在 | exists '表名' |
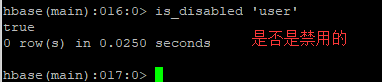
| 判断是否禁用启用表 | is_enabled '表名' is_disabled ‘表名’ |
| 添加记录 | put ‘表名’, ‘rowKey’, ‘列族 : 列‘ , '值' |
| 查看记录rowkey下的所有数据 | get '表名' , 'rowKey' |
| 查看表中的记录总数 | count '表名' |
| 获取某个列族 | get '表名','rowkey','列族' |
| 获取某个列族的某个列 | get '表名','rowkey','列族:列’ |
| 删除记录 | delete ‘表名’ ,‘行名’ , ‘列族:列' |
| 删除整行 | deleteall '表名','rowkey' |
| 删除一张表 | 先要屏蔽该表,才能对该表进行删除 第一步 disable ‘表名’ ,第二步 drop '表名' |
| 清空表 | truncate '表名' |
| 查看所有记录 | scan "表名" |
| 查看某个表某个列中所有数据 | scan "表名" , {COLUMNS=>'列族名:列名'} |
| 更新记录 | 就是重写一遍,进行覆盖,hbase没有修改,都是追加 |
查看zookeeper上的节点信息:

很明显这里的user表并不是拿来保存数据的,meta表示用来做定位的,namespace是名称空间,叫库,就是通过zookeeper,可以知道我要放的id,放到哪个hbase的从节点上。所以找数据是连接zookeeper找,而不是Hmaster.
3.java API操作hbase
1.创建表:
package com.wx.hbase1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.Table;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class Hbase1 {
/*
连接hbase集群使用api操作数据
*/
//配置ss
static Configuration configuration=null;
private Connection connection=null;
private Table table=null;
@Before
public void init () throws Exception
{
configuration = HBaseConfiguration.create();//分布式集群一定要先来配置
//要通过zoookeeper来操作
configuration.set("hbase.zookeeper.quorum","zookeeper1");//zookeeper地址
configuration.set("hbase.zookeeper.property.clientPort","2181");//zookeeper端口
connection = ConnectionFactory.createConnection(configuration);
table=connection.getTable(TableName.valueOf("user"));
}
//创建表
@Test
public void createTable() throws Exception
{
//创建表的管理类
HBaseAdmin hBaseAdmin = new HBaseAdmin(configuration);
//创建表的描述类
TableName tableName = TableName.valueOf("test1");
HTableDescriptor descriptor = new HTableDescriptor(tableName);
//创建列族的描述类
HColumnDescriptor family1 = new HColumnDescriptor("info");// 列族
// 将列族添加到表中
descriptor.addFamily(family1);
HColumnDescriptor family2 = new HColumnDescriptor("info2"); // 列族
// 将列族添加到表中
descriptor.addFamily(family2);
// 创建表
hBaseAdmin.createTable(descriptor); // 创建表
}
@After
public void close() throws Exception {
table.close();
connection.close();
}
}
创建成功:
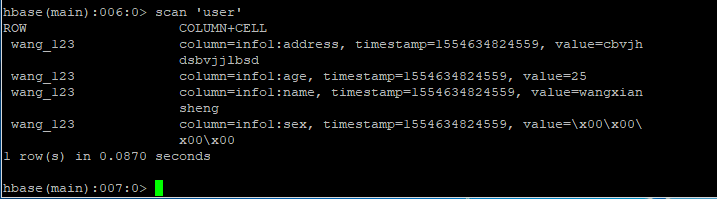
2.添加数据,上面是连接user表
@Test
public void insertData() throws Exception {
Put put = new Put(Bytes.toBytes("wang_123"));
put.add(Bytes.toBytes("info1"), Bytes.toBytes("name"), Bytes.toBytes("wangxiansheng"));
put.add(Bytes.toBytes("info1"), Bytes.toBytes("age"), Bytes.toBytes("25"));
put.add(Bytes.toBytes("info1"), Bytes.toBytes("sex"), Bytes.toBytes(0));
put.add(Bytes.toBytes("info1"), Bytes.toBytes("address"), Bytes.toBytes("cbvjhdsbvjjlbsd"));
table.put(put);
} 
3.删除
@Test
public void deleteData() throws Exception {
Delete delete = new Delete(Bytes.toBytes("wang_123"));
table.delete(delete);
}

只删除某一个列族:

只删除某一列:

查询:
单条查询:

全表扫描:可以查询某一列,也可以查某某个区间的数据
@Test
public void scanData() throws Exception {
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
byte[] name = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("name"));
byte[] sex = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("sex"));
byte[] age = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("age"));
byte[] address = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("address"));
System.out.println(Bytes.toString(name));
System.out.println(Bytes.toInt(sex));
System.out.println(Bytes.toString(age));
System.out.println(Bytes.toString(address));
}
} 
过滤器 过滤器的种类:
列植过滤器—SingleColumnValueFilter
过滤列植的相等、不等、范围等
列名前缀过滤器—ColumnPrefixFilter
过滤指定前缀的列名
多个列名前缀过滤器—MultipleColumnPrefixFilter
过滤多个指定前缀的列名
rowKey过滤器—RowFilter
通过正则,过滤rowKey值。
全表扫描的列值过滤器:
@Test
public void scanDataByFilter() throws Exception {
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(Bytes.toBytes("info1"), Bytes.toBytes("name"), CompareFilter.CompareOp.EQUAL, Bytes.toBytes("zhangsan"));
Scan scan = new Scan();
scan.setFilter(singleColumnValueFilter);
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
byte[] name = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("name"));
byte[] sex = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("sex"));
byte[] age = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("age"));
byte[] address = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("address"));
System.out.println(Bytes.toString(name));
System.out.println(Bytes.toInt(sex));
System.out.println(Bytes.toString(age));
System.out.println(Bytes.toString(address));
}
}

列名前缀过滤器—ColumnPrefixFilter:
过滤器—ColumnPrefixFilter
ColumnPrefixFilter 用于指定列名前缀值相等
ColumnPrefixFilter f = new ColumnPrefixFilter(Bytes.toBytes("values"));
s1.setFilter(f);
rowKey过滤器—RowFilter:
RowFilter 是rowkey过滤器
通常根据rowkey来指定范围时,使用scan扫描器的StartRow和StopRow方法比较好。
Filter f = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^1234")); //匹配以1234开头的rowkey
s1.setFilter(f);
多个过滤器串着用:

@Test
public void scanDataByFilter1() throws Exception {
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
//rowKey过滤器,过滤rowkey为wang_1234开头的数据
Filter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^wang_1234"));
//列值过滤器,
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(Bytes.toBytes("info1"), Bytes.toBytes("name"), CompareFilter.CompareOp.EQUAL, Bytes.toBytes("zhangsan"));
filterList.addFilter(filter);
filterList.addFilter(singleColumnValueFilter);
Scan scan = new Scan();
scan.setFilter(filterList);
ResultScanner resultScanner = table.getScanner(scan);
for (Result result : resultScanner) {
byte[] name = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("name"));
byte[] sex = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("sex"));
byte[] age = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("age"));
byte[] address = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("address"));
System.out.println(Bytes.toString(name));
System.out.println(Bytes.toInt(sex));
System.out.println(Bytes.toString(age));
System.out.println(Bytes.toString(address));
}
} 
















 551
551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











