







从零打造高通平台hexagon dsp profiling性能分析工具-7
前言
前面写了系列文章
从零打造高通平台hexagon dsp profiling性能分析工具-1
从零打造高通平台hexagon dsp profiling性能分析工具-2
从零打造高通平台hexagon dsp profiling性能分析工具-3
从零打造高通平台hexagon dsp profiling性能分析工具-4
从零打造高通平台hexagon dsp profiling性能分析工具-5
从零打造高通平台hexagon dsp profiling性能分析工具-6
剖析了itrace是怎么做的,也分析了自研profiling分析工具的大体实现思路。本文开始逐渐细化,先讲有哪些profiling指标,如何由pmu信息计算这些指标。
如何用pmu信息构造profiling观测数据
以v69 4hvx core,6scale core为例子进行说明。
hvx/hmx核是由标量核调起来的,qurt也是跑在标量核上,v69 6个标量核即6个HW线程的负载情况是最先应该关注的一个dsp指标。
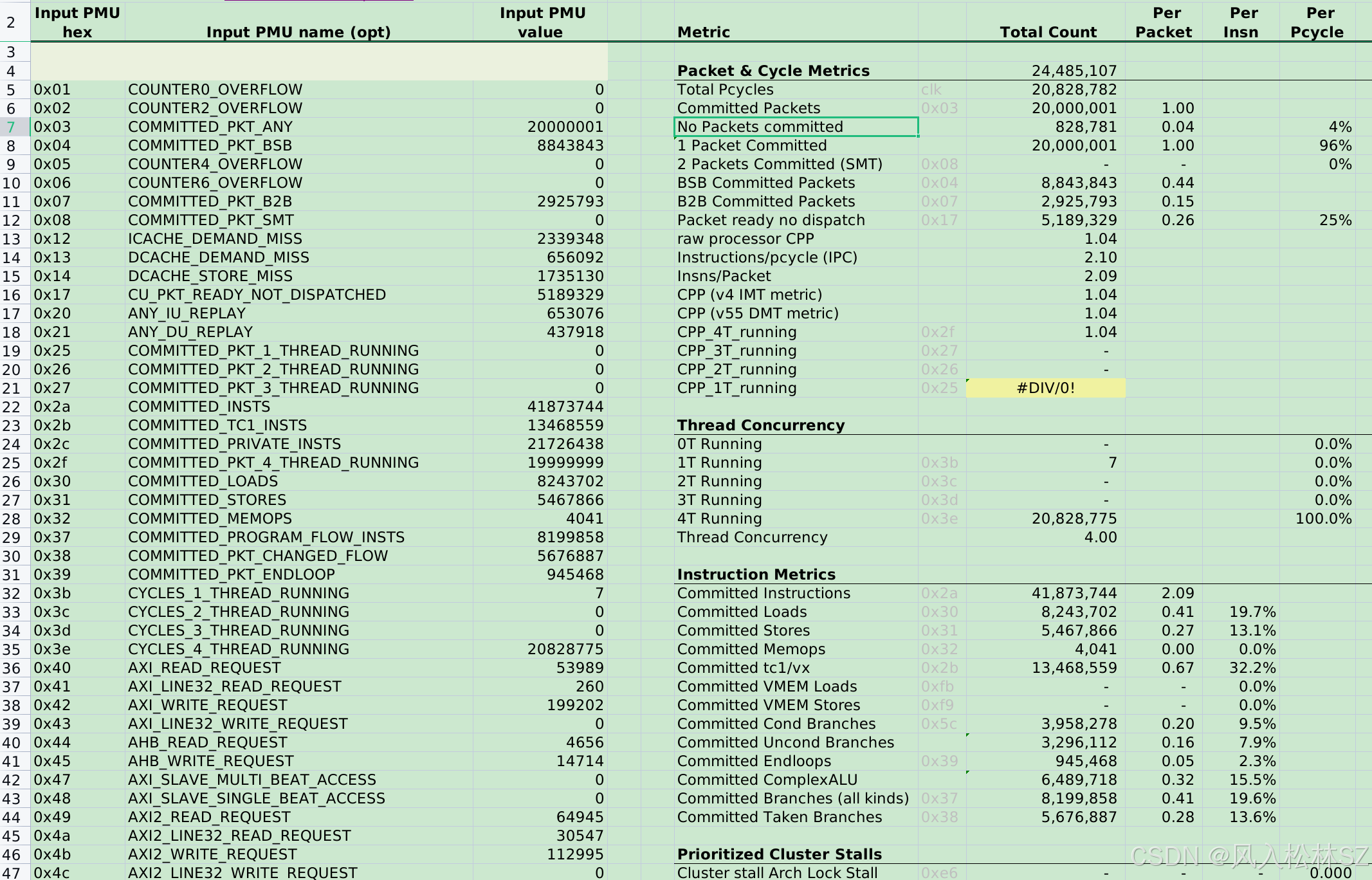
1.硬件线程并发数指标及平均pCPP指标
hw_thread_concurrency并发数指标:
是一个在[1,6]之间取值的数,反映了观测时间内6个硬件线程中有几个处于繁忙状态。
pCPP(average process cycles taken per packet)指标:
是一个平均指标,值越大,说明有比较严重的stall,需要关注访存瓶颈,通过提高总线频率,提高cache命中率可以降低此指标,使在同样core clock主频下能执行更多pacckets,干更多的活。
nT_pCPP是更细的具体到几个并发线程的pCPP,需要再多读出COMMITTED_PKT_n_THREAD_RUNNING 这些pmu值才能计算,这会使一个group超出8个pmu 。
多线程情况下,会出现总线竞争、缓存竞争及冲突,通常相比单线程会恶化,因此也是一个值得关注的指标。
pmu0=COMMITTED_PKT_ANY;
pmu1=CYCLES_1_THREAD_RUNNING;
pmu2=CYCLES_2_THREAD_RUNNING;
pmu3=CYCLES_3_THREAD_RUNNING;
pmu4=CYCLES_4_THREAD_RUNNING;
pmu5=CYCLES_5_THREAD_RUNNING;
pmu6=CYCLES_6_THREAD_RUNNING;
total_cycles=pmu1+pmu2+pmu3+pmu4+pmu5+pmu6;
hw_thread_concurrency=(pmu1+pmu2*2+pmu3*3+pmu4*4+pmu5*5+pmu6*6)/total_cycles
pCPP=total_cycles/pmu0;
nT_pCPP=CYCLES_n_THREAD_RUNNING/COMMITTED_PKT_n_THREAD_RUNNING;
2. 硬件线程负载情况
nT_%Load指标:
% of packets executed per second when n threads are active
与hw_thread_concurrency一样是刻画同一个事务的不同方面,但能更细的反映指令在硬件线程中空间分布情况。
pmu0=COMMITTED_PKT_ANY;
pmu1=COMMITTED_PKT_1_THREAD_RUNNING;
pmu2=COMMITTED_PKT_2_THREAD_RUNNING;
pmu3=COMMITTED_PKT_3_THREAD_RUNNING;
pmu4=COMMITTED_PKT_4_THREAD_RUNNING;
pmu5=COMMITTED_PKT_5_THREAD_RUNNING;
pmu6=COMMITTED_PKT_6_THREAD_RUNNING;
1T_%Load=pmu1/pmu0;
2T_%Load=pmu2/pmu0;
3T_%Load=pmu3/pmu0;
4T_%Load=pmu4/pmu0;
5T_%Load=pmu5/pmu0;
6T_%Load=pmu6/pmu0;
nT_%Loadd之和为100%
3. IPC指标
IPC指标:
反应平均每条指令消耗process cycles数。
由于hexagon dsp是两个标量核一个簇, PMU_COMMITTED_INSTS每个cycle增加8。
PMU_COMMITTED_INSTS计数器没有包括endloop指令,因此需要单独加上它,且需要乘以2。
特别注意:多线程多任务并发情况下,缓存、DDR压力都会变大,这个指标可能会恶化。反过来,这个指标变大也可能指示了仿存压力,但不影响MIPS。
pmu0=COMMITTED_PKT_ANY;
pmu1=CYCLES_1_THREAD_RUNNING;
pmu2=CYCLES_2_THREAD_RUNNING;
pmu3=CYCLES_3_THREAD_RUNNING;
pmu4=CYCLES_4_THREAD_RUNNING;
pmu5=CYCLES_5_THREAD_RUNNING;
pmu6=CYCLES_6_THREAD_RUNNING;
pmu7=COMMITTED_INSTS;
pmu8=COMMITTED_PKT_ENDLOOP;
total_cycles=pmu1+pmu2+pmu3+pmu4+pmu5+pmu6;
IPC=(pmu7+2*pmu8)/total_cycles;
4. MIPS指标
MIPS指标:
反应单位时间内执行的指令总数。
由于hexagon dsp是两个标量核一个簇, PMU_COMMITTED_INSTS每个cycle增加8。
PMU_COMMITTED_INSTS计数器没有包括endloop指令,因此需要单独加上它,且需要乘以2。
特别注意:对算法处理满足帧率要求的实时系统,MIPS是一个常数值,不随硬件主频而变化,只有优化算法降低计算法算复杂度MIPS指标才能够降低。
pmu1=COMMITTED_INSTS;
pmu2=COMMITTED_PKT_ENDLOOP;
delta_t=measured_time_interval;//pmu采样时间间隔,单位us
MIPS=(pmu1+2*pmu2)/delta_t;
5. MPPS指标
MPPS指标:
反应单位时间间内执行的指令包总数。
进一步区分hvx/hmx指令包可以读取HVX_PKT_THREAD及HMX_PKT_THREAD寄存器
pmu1=COMMITTED_PKT_ANY;
delta_t=measured_time_interval;//pmu采样时间间隔,单位us
MPPS=pmu1/delta_t;
6. VLIW packet density
packet density指标:
反映VLIW指令包内指令并行程度,即指令包内内平均指令数量,对hexagon dsp架构,此上限是4。
pmu0=COMMITTED_INSTS;
pmu1=COMMITTED_PKT_ANY;
packet density=Insns/Packet=pmu0/pmu1
总结
本文介绍了hw_thread_concurrency、pCPP、硬件线程负载情况、IPC、MIPS、MPPS、packet density 这几个指标基于pmu信息的计算方法。后面的文章会介绍dsp Q6核utilization、dsp hvx核utilization、dsp hmx核utilization等指标的计算。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









