







1.特点:优雅,明确,简单
2.适合的领域
A.web网站和各种网络服务
B.系统工具和脚本
C.作为胶水语言把其他语言开发的模块包装起来方便实用
3.不适合的领域
贴近硬件的代码(首选C)
移动开发
游戏开发:(c,C++)
4.对比
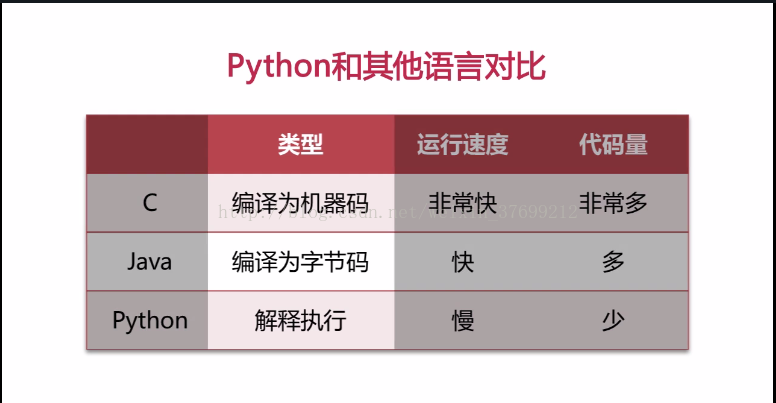
虽然运行速度慢:但是现在CPU的计算能力很强大,因此本身的影响不大,瓶颈在于带宽和数据库的访问,这些问题每个语言都会遇到
5.安装Pytlhon(跨平台)
2.7与3.3 不兼容:因为一些第三方库不兼容3.3版本
官网:www.python.org 选择对应的平台进行下载
Windows64位下载:
下载完成后傻瓜式安装
然后配置Python.exe进行环境变量的配置
打开CMD 输入python

以下为总结的与java不同的基础知识点
1.字符串
用’’或者””表示
‘Learn “打印双引号”’
“python’打印单引号’”
‘learn\’单引号\’\”双引号\”’
\n换行
\t 表示一个制表符
包含很多转义符: r’\(--)/\(--)/’
多行字符串 ‘’’第一行
第二行
第三行’’’
Unicode表示:u’中文’
2.布尔为True和False 首字母大写 0、空字符串''和None看成 False,其他数值和非空字符串都看成 True
3.空值 表示为None
4.and,or,not 具有短路运算特性
5.Print打印语句
print ‘hello world’,100+100
hello world 200 #运行结果 , 会变成一个空格 #为注释6.如果出现UnicodeDecodeError 是因为.py文件保存的格式有问题,可以在文件的第一行添加注释
# -*- coding: utf-8 -*-目的是告诉python解释器,用Utf-8编码读取源代码
7.list 有序集合
_list = [1,1.0,True,'hello']
print _list[0] #打印第一个1
print _list[-1] #打印最后一个元素 -2为倒数第二...
_list.append(“新元素”) #添加到最后
_list.insert(0,“插入到第一个”)
_list.pop()#删除最后一个 带参数表示要删除的索引
_list[-1] = “新元素”8.tuple 有序列表,元组,与list不同的是 tuple一旦创建就不能修改了
_tuple = (1,True,1.0,’tuple)
_tuple = (1,) #单元素添加, 9.If
具有相同缩进的代码被视为代码块严格按照Python的习惯写法:4个空格,不要使用Tab,更不要混合Tab和空格
if elif elif # if else if10.for
L = [“name1”,’name2’]
for name in L: #遍历tuple类似11.while 没啥不同
while true:#死循环12.dict 类似于java的map
d = {
“dog”:0,
“pig”:1,
“me”,100
}
d[“pig”] #访问1 存在返回 不存在报错:KeyError
d.get(“pig”) #访问2 存在返回 不存在返回None
if “pig” in d:
print d[“pig”]dict特点:
A.查找速度快,无论元素多少,查找速度一样快
B.占用内存大,浪费内容
C.dict按照key查找,在一个dict中key不可以重复
D.Key-value序对是没有顺序的
13.Set
元素不能重复
S = set([‘A’,2,”b”]) #创建方式是往()中传入一个list,list的元素将作为set的元素访问
‘A’ in s # True
‘C’ in s #false
S.add(3)
S.remove(‘A’)#加判断 不然会报错 KeyError特点:
A.set的内部结构和dict类似,区别是没value,因此判断一个元素是否在set中的速度很快
B.Set存储的元素是没有顺序的 和dict类似
14.函数
查询预定义的函数文档链接:http://docs.python.org/2/library/functions.html#abs
也可以通过help(abs)查看abs的信息
在调用函数的时候如果传入的参数数量不对,会报TypeError错误
如果传入的参数类型不能被函数接受,也会报TypeError
编写函数:
def method_name(x):
return 1如果没有return语句,函数执行完毕后会返回及结果,只是结果为None return None 等于 return
Python函数可以返回多值
def demo():
return 1,2
x,y = demo() #但其实返回的是一个tuple 内部有加工处理
函数默认值Demo:
def green(name='world'):
print 'hello',name
green()
green(u"姓名")
可变参数:
def fn(*args):#args为tuple 可传入0 1,n个参数
print args
15.list进行切片
取list前几个元素
两种方法
A.
r = []
n = 3
for i in range(n)
R.append(l[i])B.
L[0:3]#从L集合中提取0到3的数据包0不含3 如果从0开始还可以省略0 L[:3]
L[:]#从头到尾 因此L[:]相当于复制了一份L
L[0:4:2]#从0开始到4(不含4)每2个元素取第一个
16.迭代
有序集合:list,tuple,str和unicode;
无序集合:set
无序集合并且具有 key-value 对:dict
索引迭代:需要在迭代的时候拿到有序集合的索引
L = ['Adam', 'Lisa', 'Bart', 'Paul']
for index, name in enumerate(L):#enumerate()将有序集合变成了类似
#[(k1,v1),(k2,v2)]因此迭代的每一个其实是tuple
print index, '-', name
for t in enumerate(L)
print t[0],’-’,t[1]
迭代dict的value
A.dict有values()方法,将dict的value生成一个list
B.Dict有itervalues()方法,效果一样
区别:
A.values()方法实际上把一个dict转换成了包含value的list
B.Itervalues()方法不会转换,它会在迭代过程中依次从dict中取出value,所以itervalues()方法比values()方法节省了生成list所需要的内存
C.对dict的k v一起迭代 通过dict的items()方法
for key, value in d.items():
print key, ':', value17.生成列表
A.range(1,100)#生成一个[1....100]的list
B.[x * x for x range(1,11)] #[1,4,9,16....]写列表生成式时,把要生成的元素 x * x 放到前面,后面跟 for 循环,就可以把list创建出来
18.复杂表达式
假设有如下的dict:
d = { 'Adam': 95, 'Lisa': 85, 'Bart': 59 }
完全可以通过一个复杂的列表生成式把它变成一个 HTML 表格:
tds = ['<tr><td>%s</td><td>%s</td></tr>' % (name, score) for name, score in d.iteritems()]
print '<table>'
print '<tr><th>Name</th><th>Score</th><tr>'
print '\n'.join(tds)
print '</table>'注:字符串可以通过 % 进行格式化,用指定的参数替代 %s。字符串的join()方法可以把一个 list 拼接成一个字符串。
把打印出来的结果保存为一个html文件,就可以在浏览器中看到效果了:
<table border="1">
<tr><th>Name</th><th>Score</th><tr>
<tr><td>Lisa</td><td>85</td></tr>
<tr><td>Adam</td><td>95</td></tr>
<tr><td>Bart</td><td>59</td></tr>
</table>
EG1:
请编写一个函数,它接受一个 list,然后把list中的所有字符串变成大写后返回,非字符串元素将被忽略。
def toUppers(L):
return [x.upper() for x in L if isinstance(x,str) ]
print toUppers(['Hello', 'world', 101])
EG2:
利用 3 层for循环的列表生成式,找出对称的 3 位数。例如,121 就是对称数,因为从右到左倒过来还是 121。
print [x*100 + y * 10 + z for x in range(1,10) for y in range(1,10) for z in range(1,10) if x == z ]















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









