









目录
背景
在阅读shardingjdbc-4.1.1代码时,发现一段sql解析的逻辑,好奇它的实现,查阅相关资料发现解析引擎基于Antlr4实现,便有了此文

官方文档中也描述了解析引擎的迭代过程
SQL解析作为分库分表类产品的核心,其性能和兼容性是最重要的衡量指标。 ShardingSphere的SQL解析器经历了3代产品的更新迭代。
第一代SQL解析器为了追求性能与快速实现,在1.4.x之前的版本使用Druid作为SQL解析器。经实际测试,它的性能远超其它解析器。
第二代SQL解析器从1.5.x版本开始,ShardingSphere采用完全自研的SQL解析引擎。 由于目的不同,ShardingSphere并不需要将SQL转为一颗完全的抽象语法树,也无需通过访问器模式进行二次遍历。它采用对SQL半理解的方式,仅提炼数据分片需要关注的上下文,因此SQL解析的性能和兼容性得到了进一步的提高。
第三代SQL解析器则从3.0.x版本开始,ShardingSphere尝试使用ANTLR作为SQL解析的引擎,并计划根据DDL -> TCL -> DAL –> DCL -> DML –>DQL这个顺序,依次替换原有的解析引擎,目前仍处于替换迭代中。 使用ANTLR的原因是希望ShardingSphere的解析引擎能够更好的对SQL进行兼容。对于复杂的表达式、递归、子查询等语句,虽然ShardingSphere的分片核心并不关注,但是会影响对于SQL理解的友好度。 经过实例测试,ANTLR解析SQL的性能比自研的SQL解析引擎慢3-10倍左右。为了弥补这一差距,ShardingSphere将使用PreparedStatement的SQL解析的语法树放入缓存。 因此建议采用PreparedStatement这种SQL预编译的方式提升性能。–----摘自官网
由此可见,采用Antlr4更好地兼容sql,方便解析引擎对sql的理解,而Antlr4的产物,便是抽象语法树(AST,Abstract Syntax Tree),下面介绍相关概念
相关概念
| 名词 | 解释 | 备注 |
|---|---|---|
| AST | 抽象语法树(AST,Abstract Syntax Tree)是一种用于表示编程语言代码结构的树状数据结构。它将源代码解析为树状的层次结构,每个节点表示代码中的一个语法元素,例如变量、操作符、语句等,通过遍历和操作AST树,程序可以更轻松地理解和操纵源代码 |
|
| ANTLR | ANTLR (ANother Tool for Language Recognition) 是一个用于生成语法分析器和编译器的强大工具。ANTLR 4 是ANTLR的第四个版本,它提供了许多功能,使得创建和维护语法分析器更加简单 |
|
| LL(*) | 一种语法分析方法,它是基于LL(左到右,从左到右的扫描)语法分析的扩展。LL(*)语法分析器允许更灵活地处理上下文敏感语法,而不受传统LL(k)语法分析器中固定向前看符号数限制的约束 |
|
| 二义性 | 是语法分析和语言处理中的一个概念,指的是在给定的语法规则下,一个输入字符串可以有多种不同的解释或分析方式 意味着语法规则无法唯一确定输入字符串的语法结构,即存在多个可能的分析树或解析路径 | java的二义性如两个不同接口名,方法A一致,实现类调用A时就有歧义 再比如sql中select user from user group by user,里面的user表达也有歧义 |
| Lexer | 词法分析器,负责将源代码文本分解成词法单元(token),词法单元通常是编程语言中的最小语法单元,如关键字、标识符、操作符、常量等 | Lexer会扫描源代码字符流,识别和标记出各个词法单元,通常使用正则表达式或有限状态机等技术来实现。 词法分析器将生成的词法单元传递给解析器(Parser),供后者进行语法分析 |
| Parser | 语法分析器负责将词法单元构建成抽象语法树(AST),这是一种树状结构,用于表示源代码的语法结构 |
|
| Visitor | 访问者模式,主动遍历,推荐 |
|
| Listener | 观察者模式,通过节点监听,触发处理方法 |
|
对以上名词有一定了解之后,下面说说antlr4生成AST的流程
流程说明
整体流程主要分为两个部分,词法分析
- 词法分析----根据lexer-rule对输入进行拆分,形成token字符
将字符聚集为单词或者符号(词法符号,token)的过程称为词法分析(lexical analysis)或者词法符号化(tokenizing)。
我们把可以将输入文本转换为词法符号的程序称为词法分析器(lexer)。
词法分析器可以将相关的词法符号归类,例如INT(整数)、ID(标识符)、FLOAT(浮点数)等。当语法分析器不关心单个符号,而仅关心符号的类型时,词法分析器就需要将词汇符号归类。
词法符号包含至少两部分信息:词法符号的类型(从而能够通过类型来识别词法结构)和该词法符号对应的文本。--Antlr4权威指南-译本
- 语法解析----根据parser-rule对拆分后的token进行解析,形成AST树
第二个阶段是实际的语法分析过程,在这个过程中,输入的词法符号被"消费"以识别语句结构,在上例中即为赋值语句。
默认情况下,ANTLR生成的语法分析器会建造一种名为语法分析树parse tree或者句法树syntax tree的数据结构,该数据结构记录了语法分析器识别出输入语句结构的过程,以及该结构的各组成部分。--Antlr4权威指南-译本
解析流程示例,一个表达式经词法分析后,形成单词或符号,而后通过parser流程形成抽象树
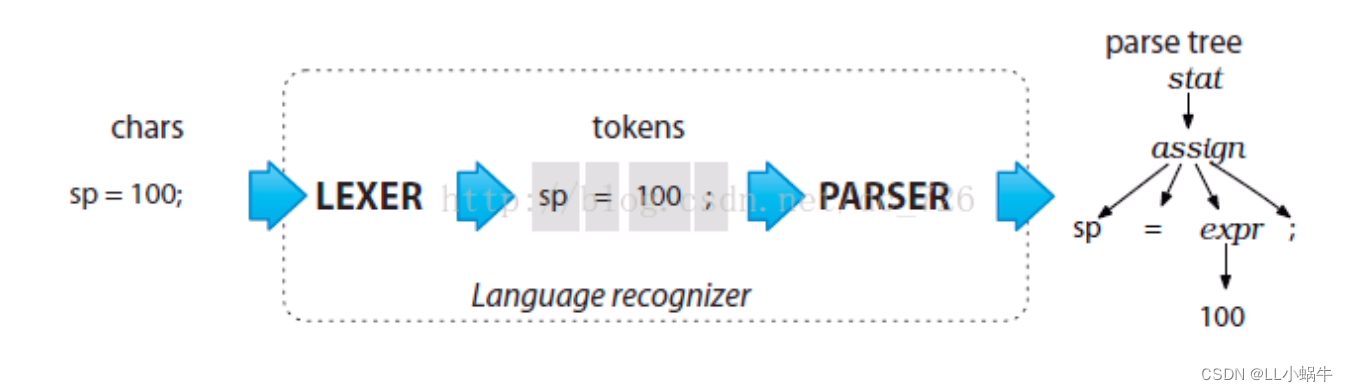
生成AST后,可以对AST进行遍历,在Antlr4提供的访问器或监听器上做对应的逻辑处理
入门示例
在本节中会实现两个功能
1.一个支持简易的计算器,支持负数、小数的四则运算
2.实现对java8方法的内容收集
简易计算器
我们定义\n是一个表达式的终止,并允许用前面的结果作为变量用于后面的计算
输入
a=3+2-1.1\nb=a*-2.2\n输出 8.58
在开始前需要先做一些准备工作
环境准备
- 下载idea plugins
- maven工程,引入依赖(antlr4-runtime)&插件(antlr4-maven-plugin)
<dependencies>
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4-runtime</artifactId>
<version>4.13.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.antlr</groupId>
<artifactId>antlr4-maven-plugin</artifactId>
<version>4.13.1</version>
<executions>
<execution>
<goals>
<goal>antlr4</goal>
</goals>
<phase>none</phase>
</execution>
</executions>
<configuration>
<outputDirectory>src/main/java</outputDirectory>
<!--<listener>true</listener>-->
<visitor>true</visitor>
<!--<treatWarningsAsErrors>true</treatWarningsAsErrors>-->
</configuration>
</plugin>
</plugins>
</build>开发
首先定义语法文件
grammar Expr;
/* 起始规则,语法分析的起点 */
prog: stat+;
stat: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| NUMBER # number
| '-' NUMBER # negative
| ID #id
| '(' expr ')' #parens
;
NUMBER : DECIMAL|INT; //数字
fragment DECIMAL : INT '.' INT; //匹配小数
ID: [a-zA-Z]+; // 匹配标识符
fragment INT: [0-9]+; // 匹配整数
NEWLINE: 'r'? '\n'; // 告诉语法分析器一个新行的开始(即语句终止标志)
WS: [\t]+ -> skip; // 丢弃空白字符
MUL: '*';
DIV: '/';
ADD: '+';
SUB: '-';通过插件的preview功能,观察AST树如下

通过插件生成语法文件对应的代码
可以看到生成了监听者&访问者模式,用于响应节点遍历事件,或直接用来遍历AST树

这里继承访问者,实现计算的逻辑,生成的方法在上面语法文件都有标识
import java.math.BigDecimal;
import java.util.HashMap;
import java.util.Map;
public class ExprCalVisitor extends ExprBaseVisitor<BigDecimal>{
Map<String, BigDecimal> memory = new HashMap<String, BigDecimal>();
@Override
public BigDecimal visitId(ExprParser.IdContext ctx) {
String id = ctx.ID().getText();
if (memory.containsKey(id))
return memory.get(id);
return BigDecimal.ZERO;
}
/**
* expr newline
* @param ctx the parse tree
* @return
*/
@Override
public BigDecimal visitPrintExpr(ExprParser.PrintExprContext ctx) {
BigDecimal value = visit(ctx.expr());
System.out.println(value);
return BigDecimal.ZERO;
}
/* ID '=' expr NEWLINE */
@Override
public BigDecimal visitAssign(ExprParser.AssignContext ctx) {
String id = ctx.ID().getText();
BigDecimal value = visit(ctx.expr());
memory.put(id, value);
return value;
}
/* expr op=('*'|'/') expr */
@Override
public BigDecimal visitMulDiv(ExprParser.MulDivContext ctx) {
BigDecimal left = visit(ctx.expr(0));
BigDecimal right = visit(ctx.expr(1));
if (ctx.op.getType() == ExprLexer.MUL)
return left.multiply( right);
return left .divide(right,4,BigDecimal.ROUND_HALF_UP);
}
/* expr op=('+'|'-') expr */
@Override
public BigDecimal visitAddSub(ExprParser.AddSubContext ctx) {
BigDecimal left = visit(ctx.expr(0));
BigDecimal right = visit(ctx.expr(1));
if(ctx.op.getType()==ExprLexer.ADD){
return left.add(right);
}
return left.subtract(right);
}
@Override
public BigDecimal visitNumber(ExprParser.NumberContext ctx) {
String text = ctx.getText();
return new BigDecimal(text);
}
@Override
public BigDecimal visitParens(ExprParser.ParensContext ctx) {
return visit(ctx.expr());
}
@Override
public BigDecimal visitNegative(ExprParser.NegativeContext ctx) {
return new BigDecimal(ctx.getText());
}
}执行测试代码
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CodePointCharStream;
import org.antlr.v4.runtime.CommonTokenStream;
import java.math.BigDecimal;
import java.util.Arrays;
import java.util.List;
public class ExprDemo {
public static void main(String[] args) {
List<String> testSet = Arrays.asList(
"a=1+2\nb=a*3\n",
"res=1+2\n",
"res=(1+0.01)*2.3*100/(15-5)\n",
"a=-1*3-4\nb=-2*a\n"
);
ExprCalVisitor visitor = new ExprCalVisitor();
for (int i = 0; i < testSet.size(); i++) {
// 构建字符流
CodePointCharStream charStream = CharStreams.fromString(testSet.get(i));
// 从字符流分析词法, 解析为token
ExprLexer lexer = new ExprLexer(charStream);
// 从token进行分析
ExprParser parser = new ExprParser(new CommonTokenStream(lexer));
// 使用监听器,遍历语法树,根据语法定义,prog为语法树的根节点
ExprParser.ProgContext prog = parser.prog();
// 使用visitor,生成自定义的对象
BigDecimal res = visitor.visit(prog);
System.out.println(res);
}
}
}结果如下
自此,已实现简易计算器的功能
java8方法提取
同样需要定义语法文件,由于java8的语法文件规则较为繁杂,所以直接从官网上拷贝java8语法
同样用插件生成对应的代码信息
然后继承对应的visitor类,编写解析逻辑
import com.xl.redisaux.demo.springmvc.antlr4.java.Java8Parser;
import com.xl.redisaux.demo.springmvc.antlr4.java.Java8ParserBaseVisitor;
import lombok.Data;
import lombok.Getter;
import lombok.Setter;
import org.springframework.util.CollectionUtils;
import java.util.*;
public class Java8DemoVisitor extends Java8ParserBaseVisitor<Map<String, Object>> {
private final Map<String, Object> res = new HashMap<>();
@Override
public Map<String, Object> visitMethodHeader(Java8Parser.MethodHeaderContext ctx) {
Java8Parser.MethodDeclaratorContext methodDeclaratorContext = ctx.methodDeclarator();
Map<String, Object> map = new HashMap<>();
map.put("returnVal", ctx.result().getText());
map.put("name", methodDeclaratorContext.Identifier().getText());
if (Objects.nonNull(methodDeclaratorContext.formalParameterList())) {
Map<String, Object> visit = visit(methodDeclaratorContext.formalParameterList());
map.put("params", visit);
}
return map;
}
@Override
public Map<String, Object> visitFormalParameter(Java8Parser.FormalParameterContext ctx) {
String paramName = ctx.variableDeclaratorId().getText();
String paramType = ctx.unannType().getText();
Map<String, Object> map = new HashMap<>();
map.put(paramType, paramName);
return map;
}
@Override
public Map<String, Object> visitPackageDeclaration(Java8Parser.PackageDeclarationContext ctx) {
String text = ctx.packageName().getText();
res.put("package", text);
return super.visitPackageDeclaration(ctx);
}
@Override
public Map<String, Object> visitMethodDeclaration(Java8Parser.MethodDeclarationContext ctx) {
Java8Parser.MethodHeaderContext methodHeaderContext = ctx.methodHeader();
if (Objects.nonNull(methodHeaderContext)) {
Map<String, Object> visit = visit(methodHeaderContext);
List<Java8Parser.MethodModifierContext> value = ctx.methodModifier();
if (Objects.nonNull(value) && value.size() > 0) {
visit.put("modifier", value.get(value.size() - 1).getText());
} else {
visit.put("modifier", "default");
}
return visit;
}
return null;
}
@Override
public Map<String, Object> visitClassDeclaration(Java8Parser.ClassDeclarationContext ctx) {
Java8Parser.NormalClassDeclarationContext normalClassDeclarationContext = ctx.normalClassDeclaration();
Map map = new HashMap();
List<MethodInfo> methodInfos = new ArrayList<>();
List<Java8Parser.ClassBodyDeclarationContext> classBodyDeclarationContexts = normalClassDeclarationContext.classBody().classBodyDeclaration();
for (Java8Parser.ClassBodyDeclarationContext classBodyDeclarationContext : classBodyDeclarationContexts) {
Map<String, Object> res = visit(classBodyDeclarationContext);
if (!CollectionUtils.isEmpty(res)) {
MethodInfo e = new MethodInfo();
e.setMethodName(res.get("name").toString());
e.setReturnType(res.get("returnVal").toString());
e.setParamsInfo((Map<String, Object>) res.get("params"));
e.setModifier(res.get("modifier").toString());
methodInfos.add(e);
}
}
map.put("methods", methodInfos);
map.put("className", normalClassDeclarationContext.Identifier().getText());
res.putAll(map);
return map;
}
@Override
public Map<String, Object> visitClassMemberDeclaration(Java8Parser.ClassMemberDeclarationContext ctx) {
Java8Parser.MethodDeclarationContext methodDeclarationContext = ctx.methodDeclaration();
if (Objects.nonNull(methodDeclarationContext)) {
return visit(methodDeclarationContext);
}
return null;
}
@Getter
@Setter
public static class Result {
private String className;
private String packageName;
private List<MethodInfo> methodInfos;
public static Result of(Java8DemoVisitor visitor) {
Result result = new Result();
result.className = (String) visitor.res.get("className");
result.packageName = (String) visitor.res.get("package");
result.methodInfos = (List<MethodInfo>) visitor.res.get("methods");
return result;
}
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("package:").append(packageName).append(",class:").append(className).append("\n");
for (MethodInfo methodInfo : methodInfos) {
builder.append("\t").append(methodInfo).append("\n");
}
return builder.toString();
}
}
@Getter
@Setter
public static class MethodInfo {
private String methodName;
private String returnType;
private Map<String, Object> paramsInfo;
private String modifier;
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append(modifier).append(" ").append(returnType).append(" ").append(methodName).append("\n");
if(Objects.nonNull(paramsInfo)){
builder.append("\t").append("params:").append("\n");
for (Map.Entry<String, Object> entry : paramsInfo.entrySet()) {
String key = entry.getKey();
Object value = entry.getValue();
builder.append("\t\t").append(key).append(" ").append(value);
}
}
return builder.toString();
}
}
}对应需要重写的方法可以从具体语法规则查看
编写测试代码
@SneakyThrows
private static Java8DemoVisitor.Result readFile(String fileName) {
CodePointCharStream codePointCharStream = CharStreams.fromReader(new FileReader(fileName));
Java8Lexer lexer = new Java8Lexer(codePointCharStream);
Java8Parser parser = new Java8Parser(new CommonTokenStream(lexer));
Java8Parser.CompilationUnitContext compilationUnitContext = parser.compilationUnit();
Java8DemoVisitor visitor = new Java8DemoVisitor();
visitor.visit(compilationUnitContext);
return Java8DemoVisitor.Result.of(visitor);
}执行结果如下,可以看出对应的方法和参数都被解析出来

下面简单聊聊语法规则
语法规则
常用的语法要点
- 规则表示,以`:`开始,`;`结束, 多规则以`|`分隔
- 符号(Token)名以大写开头
skip操作是一条指令,告诉词法分析器匹配并丢弃空白字符channel(HIDDEN)也是一个词法分析器指令。设置词法符号的通道号,后续会被语法分析器忽略(与skip作用类似)- 解析规则小写开头,可跟字母,数字,下划线
- 使用
#来标记ANTLR语法文件,为获取更加精确的监听器事件,ANTLR允许用#运算符为任意规则的最外层备选分支提供标签。利用这种方法,在Expr语法的基础上,增加标签。 fragment表示片段规则,定义的规则可以给其他语法文件复用- 子规则可用符号标记在语法片段出现的次数
- 可选(?)
- 出现0次或多次(*)
- 至少一次(+)
设计语法
在词法层面上,不同编程语言也倾向于实用相同的结构,例如标识符、整数、字符串等等。对单词顺序和单词间依赖关系的限制来源于自然语言,逐渐发展为以下四种抽象的计算机语言模式:
- 序列-既一列元素,例如一个数组初始化语句中的值
- 选择-在多种可选方案中做出选择,例如编程语言中的不同种类的语句
- 词法符号依赖-一个词法符号需要和某种的另外一个词法符号匹配,例如左右括号匹配
- 嵌套结构-一种自相似的语言结构,例如编程语言中的嵌套算术表达式或者嵌套语句块。
为实现以上模式,语法规则只要可选方案、词法符号引用和规则引用即可Backus-Naur-Format,BNF。为方便起见,还是将这些元素划分为子规则,与正则表达式类似,子规则是用括号()包围的内联规则。可以用以下符号标记子规则,用于指明其中的语法片段出现的次数:可选(?);出现0次或多次(*);至少一次(+);(扩展巴克斯-诺尔范式,Extended Backus-Naur Format)。----摘自Antlr4权威指南-译本
序列模式
按顺序列出各项元素,变体包括带终止符&分割符的序列模式
grammar serial;
file : (row '\n')*; // 以一个'\n'作为终止符的序列
row : field (',' field)*; // 以一个','作为分隔符的序列
field : INT; // 假设字段都是整数
INT:[0-9]+;
选择模式
用`|` 符号表示规则分支,类似于switch case的表达,与前面简易计算器语法里对应的分支逻辑类似
expr: expr op=('*'|'/') expr //分支1
| expr op=('+'|'-') expr //分支2
| NUMBER # number //分支3词法符号依赖
如果在某个语句中看到了某个符号,就必须在同一个语句中找到和它配对的那个符号
如下面的parens所示
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| '(' expr ')' #parens嵌套模式
表达式是一种典型的自相似结构,它包含多个嵌套的、以运算符分隔的子表达式
如下所示,这个是嵌套结构,fomula里是expr,而expr又可以有多个选择分支
grammar recursion;
import Expr;
expr : expr '=' expr
| fomula
| NUMBER
| fomula (OP fomula)*
;
fomula:ID* '(' expr ')' ;
ID:[a-zA-Z]+;
NUMBER:INT|DECIMAL;
OP:'*'|'+'|'-'|'/';
另外这里用了import,可以看到之前定义的fragment片段规则也可以在此处使用
以上是大概的语法规则介绍,详细可以阅读后面参考资料的内容
总结
回到一开始的问题,shardingjdbc是如何解析sql?
通过翻阅代码,入口---org.apache.shardingsphere.sql.parser.SQLParserEngine#parse
可以看出解析流程(基于4.1.1版本)如下

可以看出antlr4在解析sql的功能中扮演举足轻重的角色,了解他的实现和语法规则能更好地理解shardingjdbc解析sql的实现
注:shardingsphere源码环境如果编译失败,可以执行以下命令生成parser类,参考link
./mvnw -Dcheckstyle.skip=true -Drat.skip=true -Dmaven.javadoc.skip=true -Djacoco.skip=true -DskipITs -DskipTests install -T1C |















 7713
7713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









