






文章目录
Redis部署架构详解:原理、场景与最佳实践
Redis作为一种高性能的内存数据库,在现代应用架构中扮演着至关重要的角色。随着业务规模的扩大和系统复杂度的提升,选择合适的Redis部署架构变得尤为重要。本文将详细介绍Redis的各种部署架构模式,包括单点部署、主从复制、哨兵模式、集群模式、Active-Active地理分布式以及Kubernetes云原生部署等,深入剖析其工作原理和底层机制,并提供架构选型指南和典型应用场景比对,帮助读者根据实际需求选择最适合的Redis部署方案。
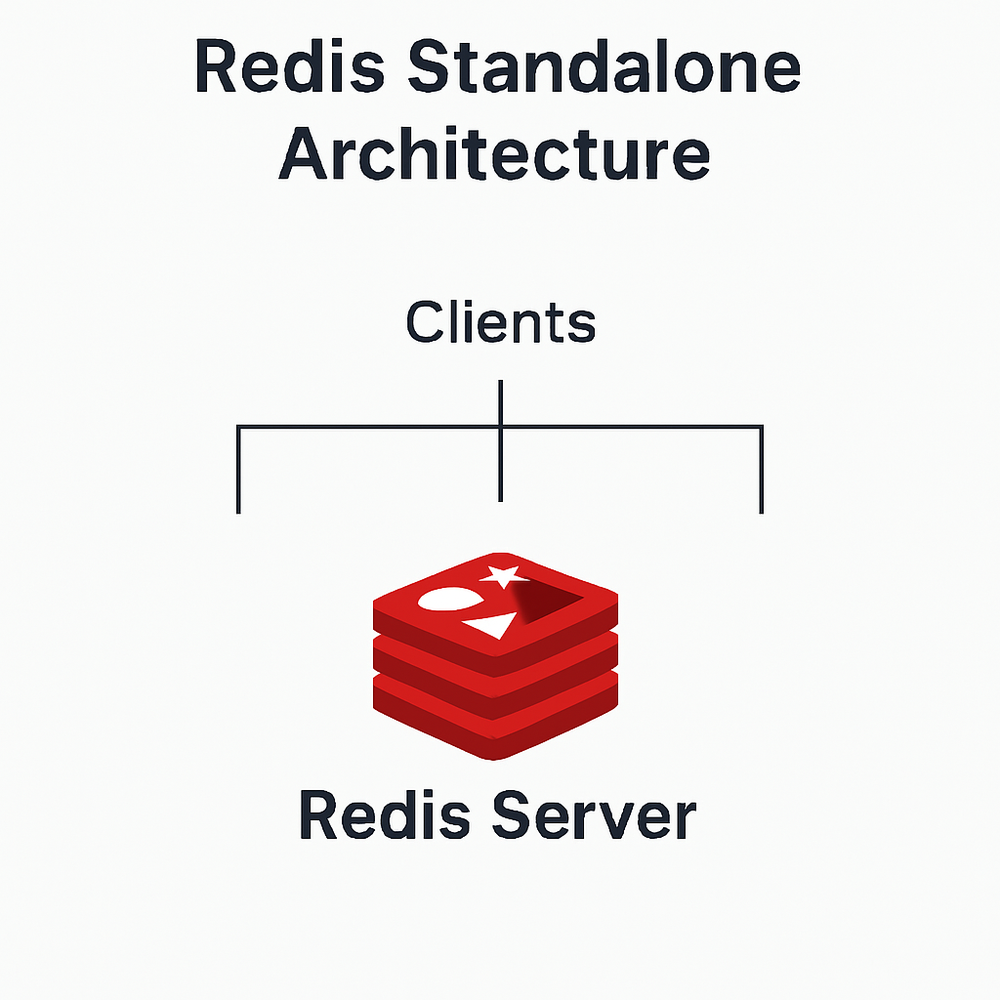
单点部署架构
原理
单点部署是最简单的Redis架构模式,仅包含一个Redis实例,所有的读写操作都在这个实例上进行。
适用场景
-
开发和测试环境
-
数据量较小且对可用性要求不高的应用
-
作为本地缓存使用
-
简单的队列或消息中间件场景
优势
-
部署简单,配置方便
-
资源消耗少
-
没有复制和同步开销
-
延迟最低
劣势
-
单点故障风险高
-
无法横向扩展
-
容量受单机内存限制
-
无法提供高可用性
最佳实践
-
启用持久化:配置AOF或RDB持久化,防止数据丢失
-
合理设置内存上限:避免内存溢出
-
定期备份:设置定时任务备份数据
-
监控系统:部署监控系统及时发现问题
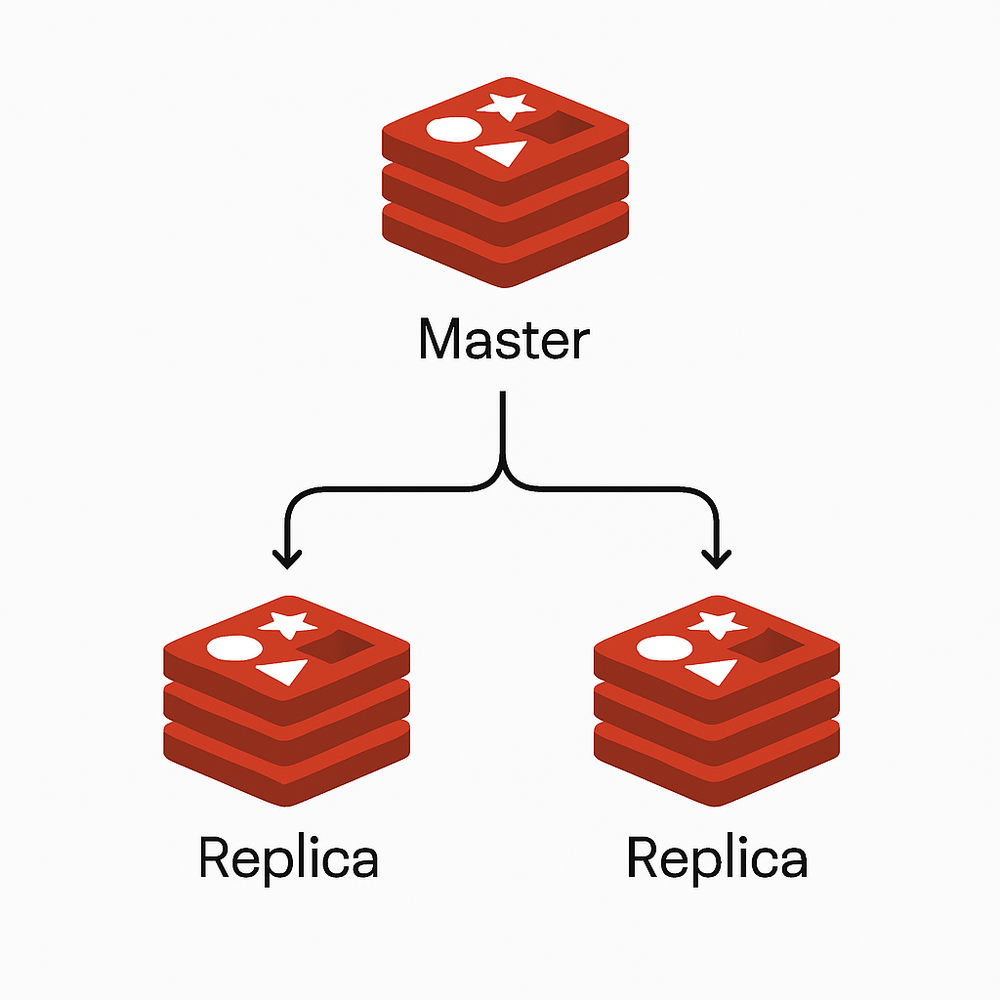
主从复制架构
原理
主从复制架构由一个主节点(master)和一个或多个从节点(replica)组成。主节点处理写操作,从节点通过异步复制方式从主节点同步数据,并提供读服务。
消息同步机制
Redis主从复制是通过三种主要机制实现的:
1. 全量同步(Full Resynchronization)
当从节点首次连接到主节点,或者无法进行部分重同步时,会触发全量同步:
-
RDB文件传输:主节点启动后台进程生成RDB快照文件
-
命令缓冲:同时,主节点会缓冲所有新收到的写命令
-
文件传输:RDB生成完成后,主节点将文件传输给从节点
-
从节点加载:从节点将文件保存到磁盘并加载到内存
-
增量命令同步:主节点发送缓冲的写命令给从节点
全量同步对网络带宽和主节点性能有较大影响,特别是数据量大的情况下。
2. 部分重同步(Partial Resynchronization)
为了避免连接断开后的全量重同步开销,Redis 2.8引入了部分重同步机制:
-
复制偏移量:主从节点各自维护一个复制偏移量,记录复制的字节数
-
复制积压缓冲区:主节点维护一个固定长度的环形缓冲区,默认1MB,记录最近执行的写命令
-
复制ID:每个主节点有一个唯一的复制ID,标识数据集的"版本"
当从节点连接断开后重新连接,会发送PSYNC命令,包含之前的复制ID和偏移量。主节点检查:
-
如果复制ID匹配且请求的偏移量在复制积压缓冲区内,则只发送缺失的部分命令
-
否则,执行全量同步
配置较大的复制积压缓冲区可以提高部分重同步的成功率:
repl-backlog-size 100mb
3. 心跳检测机制
主从节点间通过心跳机制维持连接和检测状态:
-
PING-PONG交互:主节点每隔10秒向从节点发送PING
-
复制偏移量交换:从节点每秒向主节点报告自己的复制偏移量
-
空闲连接检测:即使没有复制流量,心跳也能保持连接活跃
心跳参数可通过以下配置调整:
repl-ping-replica-period 10
repl-timeout 60
主从复制的工作流程
-
连接建立:从节点通过
slaveof或replicaof命令连接到主节点 -
握手协商:从节点发送
PING,主节点回复PONG -
同步协商:从节点发送
PSYNC命令,带上复制ID和偏移量 -
数据同步:根据情况进行全量或部分同步
-
命令传播:主节点持续将写命令发送给从节点
-
定期确认:从节点定期向主节点确认已处理的数据量
复制的一致性保证
Redis复制是异步的,这意味着:
-
主节点不等待从节点确认就返回客户端成功
-
可能存在主从数据不一致的窗口期
-
故障转移时可能丢失已确认的写入
对于需要更强一致性保证的场景,可以使用WAIT命令实现半同步复制:
WAIT <num-replicas> <timeout>
这会使主节点等待至少N个从节点应用写入后再返回,但仍不是严格的强一致性。
适用场景
-
读多写少的业务场景
-
需要读写分离的应用
-
对数据安全性有一定要求的场景
-
需要提高读性能的应用
优势
-
提高读性能和吞吐量
-
实现读写分离
-
提供数据备份
-
降低主节点负载
劣势
-
不提供自动故障转移
-
主节点故障时需要手动干预
-
写性能受单个主节点限制
-
存在数据一致性延迟
最佳实践
-
配置从节点只读:防止误操作
-
合理设置复制缓冲区:避免全量同步
-
监控复制状态:定期检查复制延迟
-
网络优化:主从节点最好在同一数据中心,减少网络延迟
-
数据安全性考虑:
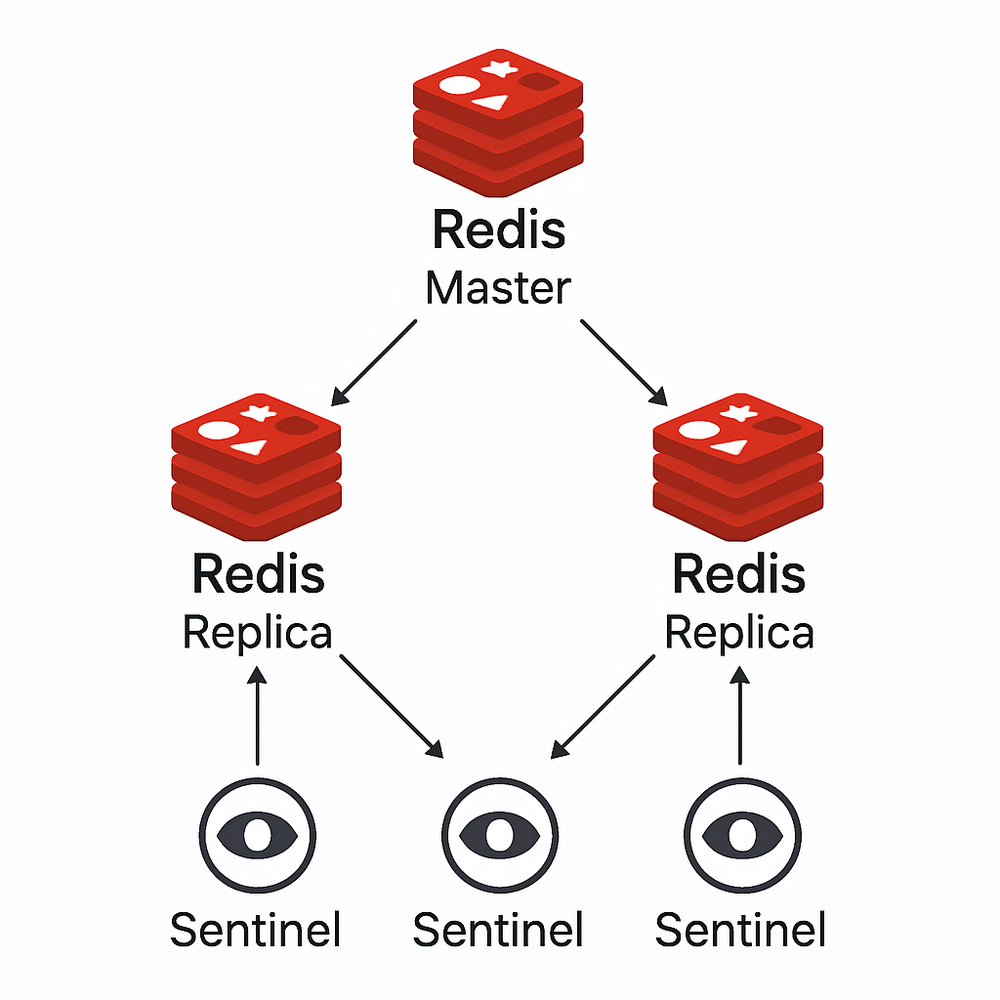
哨兵(Sentinel)架构
原理
哨兵架构是在主从复制基础上,添加了哨兵系统来监控和管理Redis实例,实现自动故障检测和故障转移。哨兵系统由多个哨兵节点组成,它们通过共识算法协作工作。
哨兵的工作机制
Redis哨兵是一个分布式系统,提供高可用性保障,其核心机制包括:
1. 监控机制
哨兵通过三种方式监控Redis实例:
- 主观下线检测:
- 每个哨兵每秒向所有主从节点发送PING命令
- 如果在
down-after-milliseconds时间内未收到有效回复,标记为主观下线(SDOWN) - 主观下线只是单个哨兵的判断,不会触发故障转移
- 客观下线检测:
- 当一个哨兵发现主节点主观下线,会询问其他哨兵是否同意
- 如果达到配置的
quorum数量,则标记为客观下线(ODOWN) - 只有主节点的客观下线才会触发故障转移
- 频道消息监控:
- 哨兵通过Redis的发布/订阅功能相互发现
- 订阅主节点的
__sentinel__:hello频道获取其他哨兵信息 - 定期(每2秒)在此频道发布自己的信息和主节点状态
2. 哨兵集群的选主与一致性
当主节点被标记为客观下线后,哨兵集群需要选出一个领导者来执行故障转移:
- 领导者选举:
- 基于Raft算法的简化实现
- 每个发现主节点客观下线的哨兵都可能成为候选人
- 候选人向其他哨兵发送
SENTINEL is-master-down-by-addr命令请求投票 - 每个哨兵在每轮选举中只能投一票
- 第一个获得多数票(N/2+1)的候选人成为领导者
- 选举时间窗口:
- 选举有时间窗口限制,默认为主节点故障确认时间+10秒
- 如果在时间窗口内无法选出领导者,将重新开始选举
- 配置纪元(configuration epoch):
- 每次选举都会增加配置纪元
- 用于防止脑裂和确保配置一致性
- 高纪元的配置会覆盖低纪元的配置
3. 自动故障转移流程
领导者哨兵执行故障转移的具体步骤:
- 从节点筛选:
- 排除断线、主观下线、最近5秒未回复INFO命令的从节点
- 排除与主节点断开连接超过
down-after-milliseconds*10的从节点
- 从节点排序:
- 按照复制偏移量排序(数据越新越优先)
- 如果偏移量相同,按照运行ID字典序排序
- 从节点晋升:
- 向选中的从节点发送
SLAVEOF NO ONE命令使其成为主节点 - 等待从节点转变为主节点(最多等待
failover-timeout时间)
- 重新配置其他从节点:
- 向其他从节点发送
SLAVEOF命令,指向新主节点 - 更新哨兵的监控配置,将新主节点记录下来
- 配置传播:
- 领导者哨兵将新配置通过发布/订阅传播给其他哨兵
- 所有哨兵更新自己的配置状态
4. 配置提供者功能
哨兵作为服务发现的权威来源:
- 客户端服务发现:
- 客户端连接到哨兵集群获取当前主节点信息
- 使用
SENTINEL get-master-addr-by-name <master-name>命令 - 支持订阅主节点地址变更通知
- 配置持久化:
- 哨兵会将配置持久化到本地配置文件
- 包括主从关系、运行ID、复制偏移量等信息
- 重启后可以恢复之前的监控状态
- 动态配置更新:
- 哨兵会自动发现主节点的从节点并更新配置
- 当拓扑结构变化时(如添加新的从节点),配置会自动更新
哨兵的高可用保证
哨兵自身的高可用性设计:
- 最少三个哨兵:
- 推荐至少部署3个哨兵实例
- 分布在不同的物理机或可用区
- 多数派原则:
- 故障转移需要多数哨兵(N/2+1)参与决策
- 确保在网络分区时只有一侧能执行故障转移
- 脑裂防护:
- 主节点可配置
min-replicas-to-write和min-replicas-max-lag - 当可见的从节点数量不足时,主节点拒绝写入
- 防止网络分区导致的双主情况
适用场景
-
需要高可用性的生产环境
-
对系统自动恢复要求较高的场景
-
中小规模的Redis应用
-
读多写少且需要自动故障转移的场景
优势
-
提供自动故障检测和转移
-
无需人工干预即可恢复服务
-
支持水平扩展的读能力
-
客户端服务发现
劣势
-
架构相对复杂
-
写性能仍受单主节点限制
-
故障转移期间可能有短暂不可用
-
脑裂情况下可能丢失数据
最佳实践
-
部署至少3个哨兵节点:确保高可用性和决策准确性
-
合理设置判断主节点下线的时间阈值:
-
配置客户端连接:使用哨兵地址池而非直接连接Redis实例
-
防止脑裂:配置主节点最小写入副本数
-
哨兵节点分布:部署在不同的物理机或可用区
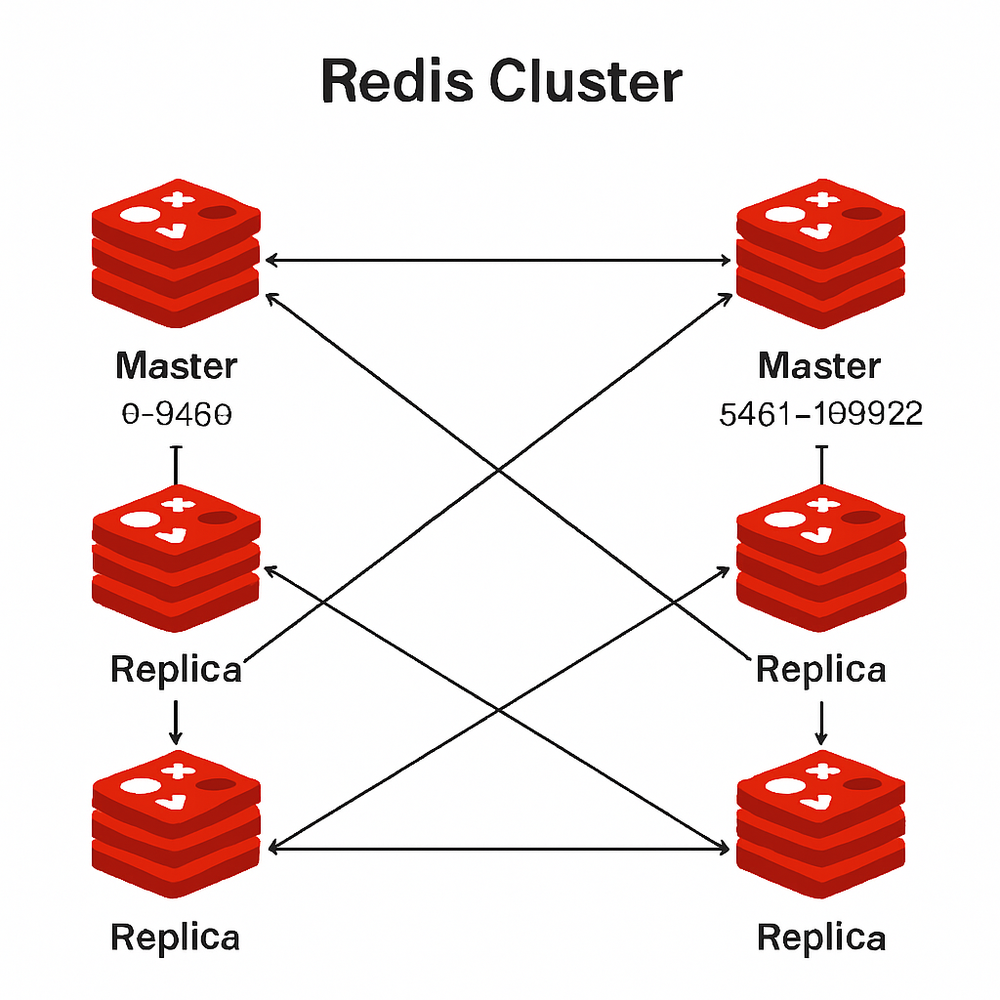
集群(Cluster)架构
原理
Redis集群通过分片(Sharding)的方式,将数据分散存储在多个节点上,每个节点存储一部分数据。Redis使用哈希槽(Hash Slot)机制,将16384个哈希槽分配给不同的节点,根据键的CRC16值对16384取模来确定数据存储位置。
集群的工作机制
Redis集群通过分片实现数据的水平扩展,其核心机制包括:
1. 数据分片与哈希槽
Redis集群使用哈希槽(Hash Slot)而非一致性哈希来分配数据:
- 16384个哈希槽:
- 集群总共有16384个哈希槽
- 每个主节点负责一部分哈希槽
- 键到槽的映射:
- 使用CRC16算法计算键的哈希值,然后对16384取模
HASH_SLOT = CRC16(key) mod 16384
- 哈希标签:
- 通过
{tag}语法强制多个键分配到同一个槽 - 例如:
user:{123}:profile和user:{123}:account会被分配到同一个槽 - 允许对这些键执行多键操作(如MGET、事务等)
- 槽迁移:
- 添加或删除节点时,只需迁移相应的哈希槽
- 迁移过程是在线的,不影响集群服务
- 迁移期间对相关键的访问会被重定向
2. Gossip协议与集群通信
Redis集群节点间通过Gossip协议进行通信和状态同步:
- 集群总线:
- 每个节点有两个TCP端口:客户端端口和集群总线端口
- 集群总线端口默认是客户端端口+10000
- 节点间通过二进制协议在集群总线上通信
- Gossip消息类型:
PING:定期发送,包含发送者已知的部分集群状态PONG:响应PING或主动广播状态更新MEET:请求节点加入集群FAIL:广播节点已失效的信息PUBLISH:用于发布/订阅功能的集群范围消息
- 心跳机制:
- 每个节点每秒随机选择一些节点发送PING
- 优先选择长时间未收到PONG的节点
- 每100毫秒检查是否有节点超过
cluster-node-timeout未响应
- 信息传播:
- 每个节点的PING/PONG消息包含自己的信息和部分其他节点的信息
- 通过这种方式,信息最终会传播到所有节点
- 关键事件(如节点失效)会加速传播,所有节点主动广播
3. 故障检测与自动故障转移
Redis集群的故障检测和自动故障转移机制:
- 节点失效检测:
- 主观下线(PFAIL):当节点A超过
cluster-node-timeout时间未响应节点B的PING,B将A标记为PFAIL - 客观下线(FAIL):当超过半数主节点都认为某节点PFAIL时,该节点被标记为FAIL
- FAIL状态会通过Gossip快速传播到整个集群
- 自动故障转移:
- 当主节点被标记为FAIL,其从节点会发起选举
- 第一个发起选举的从节点向所有主节点请求投票
- 每个主节点只能在一个配置纪元内投一票
- 获得多数票的从节点晋升为新主节点
- 新主节点更新集群配置,接管原主节点的哈希槽
- 选举限制:
- 从节点必须与主节点完成过复制(复制偏移量大于0)
- 每个配置纪元内,每个主节点只能投一票
- 如果两秒内没有从节点获得足够票数,将增加配置纪元重新选举
4. 集群一致性与可用性保证
Redis集群在一致性和可用性方面的特性:
- 分区容忍度:
- 集群能够在部分节点失效或网络分区的情况下继续运行
- 只要大多数主节点可以互相通信,集群就保持可用
- 多数派原则:
- 当少于一半的主节点不可达时,集群继续提供服务
- 当多于一半的主节点不可达时,集群停止接受写入
- 一致性保证:
- Redis集群默认提供最终一致性
- 使用异步复制,可能在故障转移时丢失已确认的写入
- 通过
WAIT命令可以实现更强的一致性保证,但不是严格的强一致性
- 集群配置参数:
cluster-node-timeout:节点失效超时时间,默认15000毫秒cluster-replica-validity-factor:从节点有效性因子,默认10cluster-migration-barrier:迁移屏障,主节点至少要有N个从节点才允许其中一个从节点迁移,默认1cluster-require-full-coverage:是否要求所有槽都被覆盖才提供服务,默认yes
5.节点变更
添加新节点
-
加入集群
使用 CLUSTER MEET 命令让新节点加入集群。新节点开始通过Gossip协议与其他节点通信,但此时它不持有任何槽位。 -
分配槽位
新节点默认是空的。需要手动或通过工具(如redis-cli --cluster reshard)将现有主节点的一部分槽位重新分配给新节点。这是核心步骤。 -
迁移槽数据
- 迁移命令(如CLUSTER SETSLOT IMPORTING 在目标节点 / CLUSTER SETSLOT MIGRATING 在源节点)标记槽位状态。
- MIGRATE 命令用于原子地将单个键或一批键从源节点移动到目标节点。迁移在后台进行。
- 迁移过程中,源节点和目标节点会协作处理请求:
- 源节点处理仍在它那里的键。
- 源节点对已迁移走的键或不在它那的键返回 MOVED。
- 源节点对正在迁移但尚未迁移走的键返回 ASK 重定向到目标节点。
- 当槽位中的所有键都迁移完成后,使用 CLUSTER SETSLOT NODE 在所有节点(或由主节点传播)更新槽位归属到新节点。
- 添加为从节点(可选): 如果新节点要作为某个主节点的从节点,使用 CLUSTER REPLICATE 命令配置。
-
影响
- 性能开销: 数据迁移会消耗源节点、目标节点和网络的资源,可能影响集群性能。
- 客户端重定向: 迁移期间和迁移完成后,客户端可能会收到 MOVED 或 ASK 重定向,需要客户端库正确处理(更新缓存、重试)。
- 短暂不一致: 迁移过程中,同一个槽的数据部分在源节点,部分在目标节点。通过 ASKING 机制保证正确性。
- 槽位重新平衡: 集群整体负载更均衡(如果槽分配合理)。
减少节点(下线节点)
-
迁移槽数据(主节点): 不能直接下线持有槽位的主节点。必须先将其负责的所有槽位迁移到其他主节点。过程与添加节点时的迁移完全一致。redis-cli --cluster reshard 是常用工具。
-
处理从节点: 如果下线的是从节点,通常相对简单:
-
直接执行 CLUSTER FORGET 命令(需要先在该从节点上执行 CLUSTER RESET 或直接停止进程)。
-
其主节点会感知到从节点丢失(通过Gossip超时)。
-
下线主节点
- 第一步:迁移所有槽位。 这是必须完成的步骤。
- 第二步: 确认该主节点不再持有任何槽位后,它本质上变成了一个“空”主节点。
- 第三步: 在集群的其他节点上执行 CLUSTER FORGET 命令,通知集群移除该节点。或者直接停止该节点进程,集群最终会通过Gossip协议将其标记为失败并从节点列表中移除(需要时间)。
-
影响
- 性能开销: 数据迁移同样消耗资源。
- 客户端重定向: 迁移期间有 MOVED/ASK。
- 容量减少: 集群整体存储容量和处理能力下降。
-
高可用性影响
如果下线的是主节点且它之前有从节点,这些从节点会跟随新的槽位持有者(迁移后槽位的新主节点)或者需要重新配置。如果下线的是最后一个从节点,其主节点失去冗余,故障时无法自动恢复。 -
槽位重新平衡
剩余节点承载了更多槽位。
适用场景
-
大规模数据存储需求
-
需要横向扩展的高吞吐量场景
-
需要高可用性和自动分片的生产环境
-
数据量超过单机内存容量的应用
优势
-
支持水平扩展,理论上无容量限制
-
提供自动故障转移和重新分片
-
高可用性,部分节点故障不影响整体服务
-
高吞吐量,可支持大规模并发访问
劣势
-
架构复杂度高,运维难度大
-
事务和多键操作受限(仅支持同一哈希槽的多键操作)
-
数据一致性保证较弱(异步复制)
-
网络开销较大
最佳实践
-
合理规划节点数量:根据数据量和性能需求确定
-
使用哈希标签:确保相关键存储在同一哈希槽
-
合理配置超时时间:避免频繁故障转移
-
监控集群状态:定期检查集群健康状况
-
规划容量和扩展:预留足够的扩展空间,避免频繁重新分片
Codis 集群架构
原理
Codis 采用中心化代理架构实现 Redis 分片集群,通过代理层(Proxy)屏蔽后端拓扑变化,对客户端透明。核心组件包括:
- Codis-Proxy:无状态代理,处理客户端请求
- Codis-Dashboard:集群控制中心,管理元数据
- Codis-Group:Redis 实例组(1主N从)
- 外部存储:ZooKeeper/etcd,存储集群元数据
- Codis-FE:Web 管理界面(可选)

集群工作机制
1. 数据分片与路由机制
-
1024 预分片槽:
- 固定划分 1024 个逻辑槽(Slot)
- 槽位分配由 Dashboard 集中管理
-
键路由算法:
slot = crc32(key) % 1024 # 默认分片算法 group = slot_map[slot] # 查询槽位映射表 -
路由表管理:
- 槽位映射表存储在外部存储(ZK/etcd)
- Proxy 实时同步路由表
- 迁移时槽位标记为过渡状态
2. 中心化控制体系
-
Dashboard 核心作用:
- 槽位分配与再平衡
- 节点状态监控
- 自动故障转移控制
- 在线数据迁移管理
-
元数据存储:
元数据类型 存储位置 示例 Slot-Group 映射 ZK/etcd {slot:1023, group_id:5} Proxy 列表 ZK/etcd [proxy1:19000, …] Group 拓扑 ZK/etcd {group5: {master:redisA, slaves:[redisB]}} -
心跳检测:
- Dashboard 主动探测 Group 状态
- 故障检测超时时间可配置(默认10s)
- 从节点晋升需人工确认(可选自动)
3. 请求处理流程
4. 节点变更机制
添加新节点
-
Group 注册:
# 在 Dashboard 操作 codis-admin --dashboard-add-group --group-id=5 codis-admin --dashboard-add-server --group-id=5 --redis=192.168.1.10:6379 -
槽位迁移:
- Dashboard 选择源 Group 的槽位
- 触发同步迁移命令:
codis-admin --slot-action --create --sid=568 \ --to-group=5 --from-group=3 - 迁移过程:
- 源 Group 锁定槽位
- 批量迁移键值(原子操作)
- 更新槽位映射表
-
客户端影响:
- Proxy 自动更新路由表
- 零客户端重定向(核心优势)
- 迁移期间请求自动路由到正确节点
移除节点
-
槽位清空:
- 必须迁移待移除 Group 的所有槽位
- Dashboard 拒绝移除非空 Group
-
Group 删除:
codis-admin --dashboard-remove-group --group-id=3 -
从节点处理:
- 直接删除从节点无需迁移
- 主节点需先降级为从节点
适用场景
- 企业级大规模 Redis 集群(100+节点)
- 需要客户端零改造的迁移场景
- 对运维可视化要求高的环境
- 需精细控制数据迁移进度的场景
- 多语言客户端支持需求
优势
-
客户端透明:
- 兼容所有 Redis 客户端
- 无需处理 MOVED/ASK 重定向
-
运维友好:
- Web 控制台实时监控
- 细粒度迁移控制
- 在线扩缩容无感知
-
高可用设计:
- Proxy 无状态可水平扩展
- Dashboard HA 方案(主备+存储)
- Group 级自动故障切换
-
企业级特性:
- 数据平衡权重配置
- 读写分离支持
- 命名空间隔离
劣势
-
架构复杂度:
- 5个核心组件需维护
- 强依赖外部存储(ZK/etcd)
-
性能损耗:
- Proxy 转发增加 1-2ms 延迟
- 大 value 传输存在内存拷贝
-
功能限制:
- 跨 slot 事务不支持
- Pub/Sub 功能受限
- 部分 Redis 命令不兼容(如 BLPOP)
最佳实践
-
部署规划:
- Proxy数量 = 预期QPS / 单Proxy承载能力(通常8-10w QPS) - Group数量 = 总内存 / 单Group内存限制(建议≤64GB) -
迁移优化:
- 避开业务高峰执行迁移
- 批量迁移设置合适并行度:
codis-admin --slot-action --max-bulk=500 # 每批迁移键数
-
高可用配置:
# Dashboard HA配置示例 dashboard: leader: "192.168.1.10:18080" follower: "192.168.1.11:18080" store: "zookeeper://zk1:2181,zk2:2181/codis" -
监控关键指标:
指标类别 关键指标 告警阈值 Proxy QPS、延迟、错误率 >80%资源利用率 Group 主从延迟、内存使用 内存>90% 迁移任务 迁移速度、剩余时间 持续1小时无进展 存储 ZK节点数、请求延迟 节点异常
注:生产环境建议使用 Codis 3.2+ 版本,较早期版本有显著稳定性提升
Active-Active地理分布式架构
原理
Active-Active架构(也称为多活架构)允许在多个地理位置部署Redis实例,每个位置的实例都可以进行读写操作,并通过冲突解决机制保持数据一致性。Redis Enterprise提供的CRDTs(Conflict-free Replicated Data Types)技术是实现这种架构的关键。
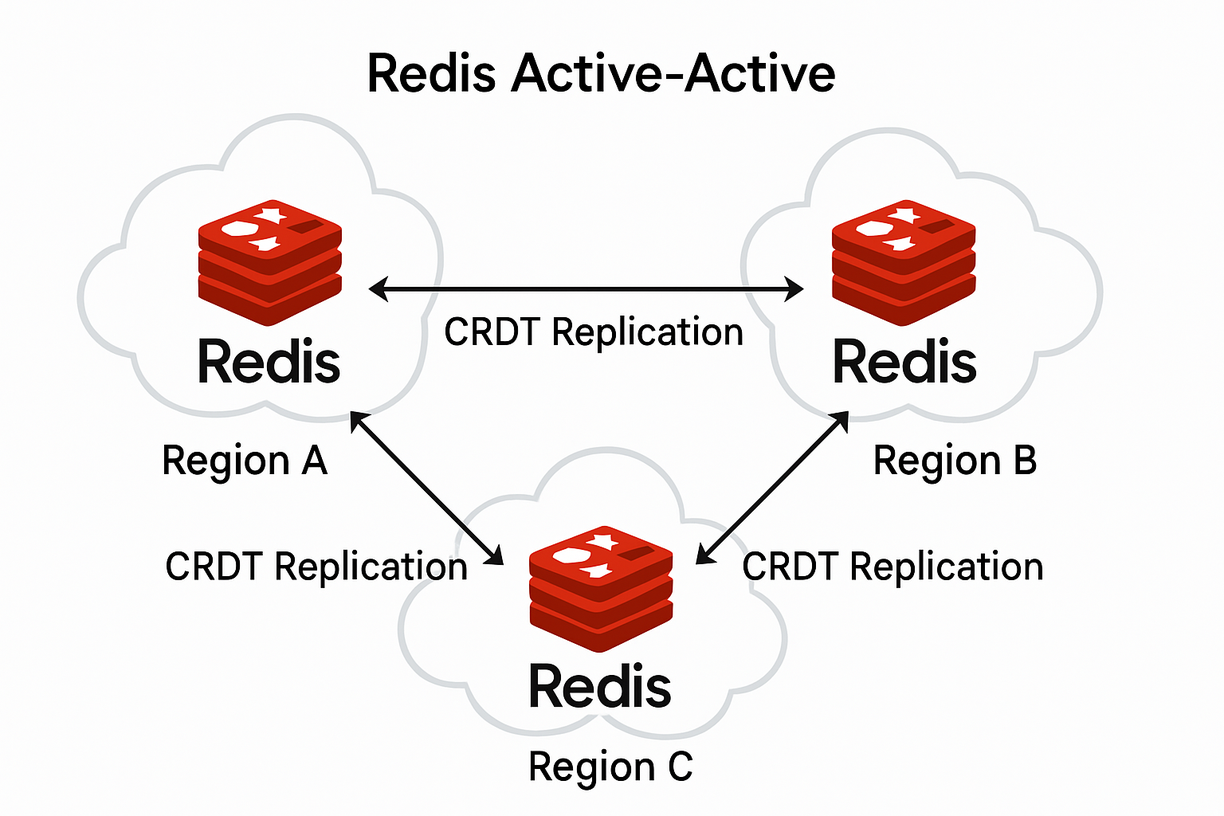
冲突解决机制
Active-Active架构使用无冲突复制数据类型(CRDTs)解决并发写入冲突:
- 最终一致性:
- 所有实例最终会收敛到相同的数据状态
- 不同实例可能暂时看到不同的数据视图
- 冲突解决策略:
- 后写入胜出:对于简单值,最后的写入会覆盖之前的写入
- 集合合并:对于集合类型,合并所有实例的元素
- 计数器累加:对于计数器,合并所有实例的增量
- 因果一致性:
- 使用向量时钟跟踪操作之间的因果关系
- 确保相关操作按正确顺序应用
跨地域复制
Active-Active架构的跨地域复制机制:
- 异步复制:
- 实例间通过异步方式复制更新
- 本地写入立即确认,然后后台传播到其他实例
- 冲突检测与解决:
- 每个实例独立应用本地写入
- 接收到远程更新时,应用冲突解决规则
- 解决后的结果再次传播,确保最终一致性
- 网络优化:
- 压缩复制流量
- 批量传输更新
- 智能路由选择最佳复制路径
适用场景
-
全球化业务需要低延迟访问
-
需要跨区域容灾的关键业务
-
多区域写入需求的应用
-
需要99.999%以上可用性的场景
优势
-
提供跨地域的低延迟访问
-
支持多区域同时写入
-
极高的可用性(99.999%+)
-
自动冲突解决
劣势
-
实现复杂度高
-
需要专业的商业版本支持(如Redis Enterprise)
-
成本较高
-
对网络质量要求高
最佳实践
-
合理规划地理位置:选择靠近用户的区域部署
-
配置冲突解决策略:根据业务需求选择合适的冲突解决方式
-
监控跨区域同步延迟:确保数据一致性在可接受范围
-
网络优化:使用专线或优质网络连接各区域
-
容灾演练:定期进行区域故障模拟和恢复测试
Kubernetes云原生部署
原理
在Kubernetes环境中部署Redis,利用Kubernetes的容器编排能力实现Redis的自动化部署、扩展和管理。可以通过Operator模式(如Redis Operator)或Helm Chart等方式部署各种Redis架构。
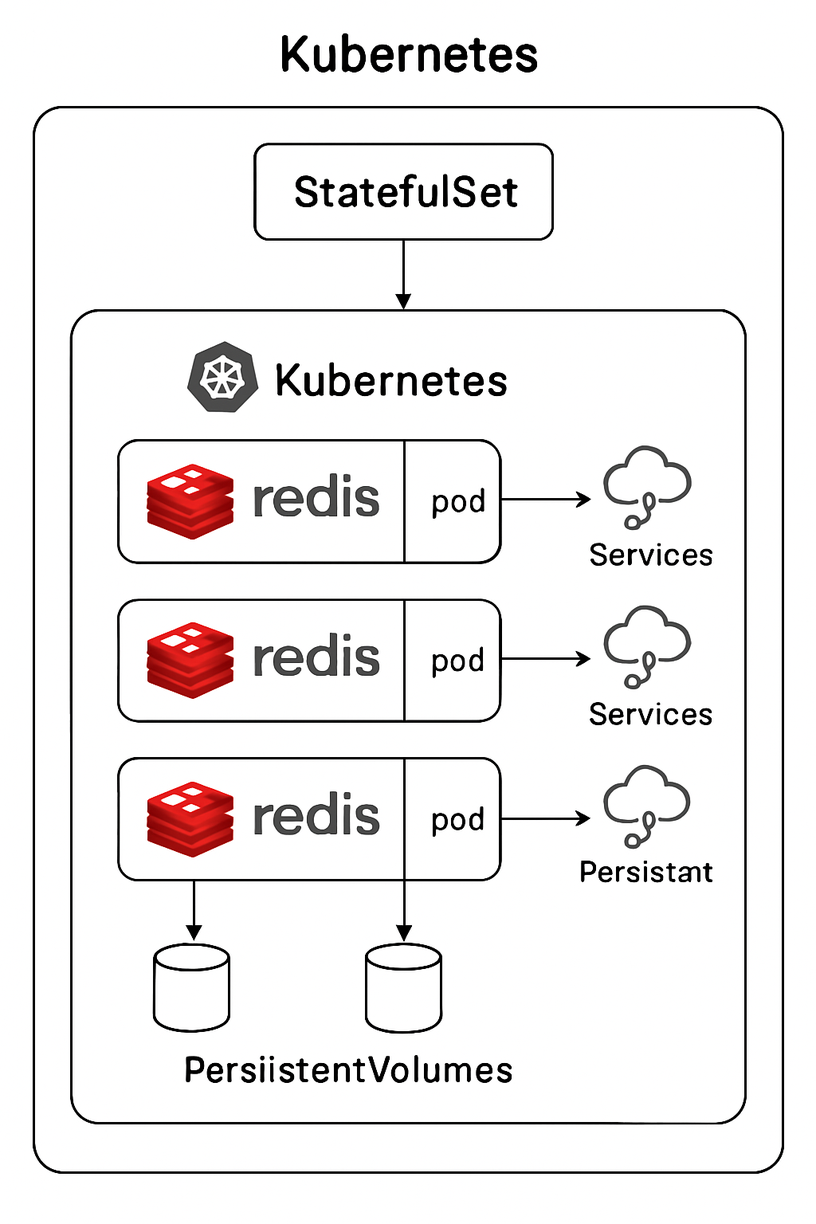
部署模式
Kubernetes中Redis的几种部署模式:
- StatefulSet:
- 为Redis提供稳定的网络标识和存储
- 支持有序部署和扩缩容
- 适用于主从复制和哨兵架构
- Operator模式:
- 使用Redis Operator自动化部署和管理
- 支持自动故障转移和配置管理
- 简化复杂架构的运维
- Helm Chart:
- 使用Helm包管理器部署预配置的Redis
- 支持自定义配置和扩展
- 适用于快速部署标准架构
存储考虑
Kubernetes中Redis的存储选项:
- 持久卷(PV)和持久卷声明(PVC):
- 为Redis数据提供持久化存储
- 支持不同的存储类(StorageClass)
- 确保Pod重启后数据不丢失
- 本地存储与网络存储:
- 本地存储提供更好的性能
- 网络存储提供更好的可用性
- 权衡性能与可靠性
适用场景
-
云原生应用架构
-
DevOps和自动化运维环境
-
需要弹性伸缩的场景
-
混合云或多云部署
优势
-
自动化部署和运维
-
弹性伸缩能力
-
与云原生生态系统集成
-
统一的管理平面
劣势
-
增加了系统复杂度
-
性能可能受容器和网络影响
-
需要Kubernetes专业知识
-
状态管理和持久化存储挑战
最佳实践
-
使用StatefulSet部署:确保稳定的网络标识和存储
-
配置持久化存储:使用PersistentVolumeClaim
-
资源限制:设置合理的CPU和内存限制
-
使用Redis Operator:简化复杂架构的部署和管理
-
网络策略:配置适当的网络策略保护Redis服务
架构选型指南与场景比对
选择合适的Redis架构需要考虑多种因素,包括性能需求、可用性要求、数据规模、预算等。以下是一个架构选型指南和典型场景比对:
架构选型决策树
- 单点部署:
- 开发/测试环境
- 数据量小(<5GB)
- 可用性要求低
- 预算有限
- 主从复制:
- 读多写少
- 需要读写分离
- 数据量中等(<10GB)
- 可接受手动故障恢复
- 哨兵架构:
- 需要高可用性
- 数据量中等(<10GB)
- 写操作集中在单点可接受
- 需要自动故障恢复
- 集群架构:
- 大数据量(>10GB)
- 需要横向扩展
- 高吞吐量要求
- 可接受一定的架构复杂性
- Active-Active架构:
- 全球化业务
- 极高可用性要求(99.999%+)
- 多区域写入需求
- 预算充足
- Kubernetes部署:
- 已采用云原生架构
- 需要自动化运维
- 需要与其他云原生应用集成
- 具备Kubernetes专业知识
典型应用场景比对
| 场景 | 推荐架构 | 理由 |
|---|---|---|
| 电商网站商品缓存 | 集群架构 | 数据量大,读写频繁,需要横向扩展 |
| 社交媒体消息队列 | 哨兵架构 | 需要高可用性,写入集中,读取分散 |
| 游戏排行榜 | 主从复制 | 读多写少,数据量适中 |
| 全球化应用会话存储 | Active-Active架构 | 需要全球低延迟访问,多区域写入 |
| 微服务架构中的缓存 | Kubernetes部署 | 与其他微服务一致的部署和管理方式 |
| 日志收集和分析 | 单点或主从 | 临时性数据,可用性要求不高 |
| 金融交易系统 | 集群+哨兵 | 高可用性和一致性要求,数据安全性高 |
| IoT数据处理 | 集群架构 | 大量并发写入,需要横向扩展 |
性能与可用性对比
| 架构模式 | 读性能 | 写性能 | 可用性 | 一致性 | 复杂度 | 成本 |
|---|---|---|---|---|---|---|
| 单点部署 | 中 | 高 | 低 | 高 | 低 | 低 |
| 主从复制 | 高 | 中 | 中 | 中 | 中 | 中 |
| 哨兵架构 | 高 | 中 | 高 | 中 | 中 | 中 |
| 集群架构 | 极高 | 高 | 高 | 中 | 高 | 高 |
| Active-Active | 极高 | 高 | 极高 | 最终一致性 | 极高 | 极高 |
| Kubernetes | 取决于底层架构 | 取决于底层架构 | 高 | 取决于底层架构 | 高 | 高 |
总结与展望
Redis提供了多种部署架构选择,从简单的单点部署到复杂的Active-Active地理分布式架构,可以满足不同规模和需求的应用场景。选择合适的架构需要综合考虑性能、可用性、一致性、复杂度和成本等因素。
随着云原生技术的发展,Redis在Kubernetes等环境中的部署变得越来越普遍。同时,Redis模块生态系统的扩展(如RedisJSON、RediSearch、RedisGraph等)也为Redis提供了更多的应用可能性,这些都需要在架构设计时考虑。
未来,随着边缘计算和5G技术的普及,Redis可能会出现更多适合边缘-云协同的部署架构模式。同时,随着AI和机器学习的发展,Redis在向量数据库方面的应用也将带来新的架构需求和挑战。
选择Redis架构时,应始终遵循"适合业务需求"的原则,避免过度设计或选择不足的架构。定期评估和调整架构,以适应业务的发展和变化,是保持Redis高效运行的关键。

















 705
705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









