







KNN邻近算法,或者说K最近邻(k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
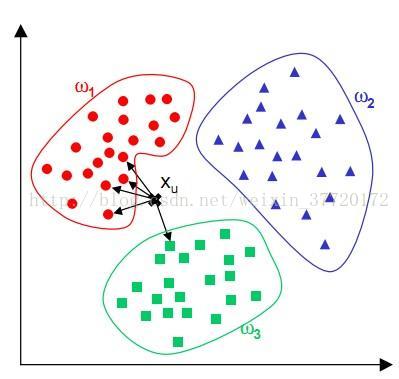
这个算法广泛用于机器学习中。比如上图中,我们给定了三个训练集w1,w2,w3。然后给出Xu来,并判断Xu属于那一个集合。
这时我们就需要去算他到以上每个集合中每一个元素的欧几里德距离(或者曼哈顿距离),然后对这些距离进行排序,并求出距离最近的前K位元素。然后根据这K位数据中,各集合所占的比例,得出比例最高的集合,这个未知元素便属于最近邻中占比最高的集合。
欧几里德距离
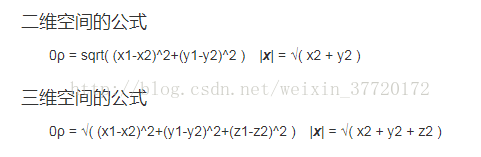
曼哈顿距离

下面给出代码(python和C++):
#coding=utf-8
from numpy import *
##定义训练集
def Get_traData():
""""创建6个数据,分别为A.B,C"""
traData = ([1.3,3.1],[2.0,1.3],[5.1,9.0],[5.3,10.1],[8.2,1.4],[9.3,1.5])
labels = ['A','A','B','B','C','C']
return traData,labels
##KNN算法
def KNN(input,tradata,label,K):
"""求欧几里德距离"""
dist = []
for i in range(len(tradata)):
_x = tradata[i][0] - input[0]
_y = tradata[i][1] - input[1]
_x = _x ** 2
_y = _y ** 2
dist.append((_x+_y)**0.5)
"""对距离进行排序,返回坐标"""
index = argsort(dist)
"""求出前K个最近距离中,每个标签各有多少个"""
count = {}
for i in range(K):
tap = label[index[i]]
count[tap] = count.get(tap,0)+1
"""求出被标记最多次的标签"""
flag = 0
result = ''
for tap in count.keys():
if flag < count[tap]:
flag = count[tap]
result = tap
return result
data,l = Get_traData()
input = [9.0,3.0]
an = KNN(input,data,l,4)
print (an)
#pragma once
#include<iostream>
#include<cmath>
#include<stdio.h>
using namespace std;
int Data_type = 2;
int Size_trainData = 6;//保存
void quick_sort(int *arr, int low, int high);//快排
//将数组arr按小到大排序后,输出前K位排好的元素在
void argsort(int K, float *arr,int *lab);
//数据的结构体:坐标,标签
typedef struct Data {
float _x;
float _y;
char _tag;
}Data;
//用于读取保存与文档中的训练数据
class train_Data {
private:
Data *data;
int size_data;
char *data_tag;
public:
train_Data() {
FILE *f;
f = fopen("trainData.txt", "r");
vector<Data> vect;//用于存放数据
vector<char> tag;//用于存放数据的标签
if (!(f = fopen("trainData.txt", "r"))) {
cout << "无法打开文档" << endl;
return;
}
//读取数据
while (!feof(f)) {
int flag = 0;
Data _data;
fscanf(f, "%f", &_data._x);
fscanf(f, "%f", &_data._y);
fscanf(f, "%s", &_data._tag);
//取出数据中的标签
if (tag.empty()) {
tag.push_back(_data._tag);
flag = 1;
}
else {
for (int i = 0;i < tag.size(); ++i)
if (_data._tag == tag[i])
flag = 1;
}
if (flag == 0)
tag.push_back(_data._tag);
vect.push_back(_data);
}
fclose(f);
size_data = vect.size();
Size_trainData = size_data;
//将容器中的数据取出
data = (Data *)malloc(sizeof(Data)*size_data);
for (int i=0; i < size_data; ++i) {
data[i]._x = vect[i]._x;
data[i]._y = vect[i]._y;
data[i]._tag = vect[i]._tag;
}
int size_tag = tag.size();
data_tag = (char *)malloc(sizeof(char)*size_tag);
for (int i = 0; i < size_tag;++i)
data_tag[i]=tag[i];
}
Data *get_trainedData() {
return data;
}
char *get_dataTag() {
return data_tag;
}
};
//如果不用上面读取文档的方法,可以这个办法加入数据
void Create_trainData(Data *data) {
data[0] = { (float)1.3,(float)3.1,'A' };
data[1] = { (float)2.3,(float)1.5,'A' };
data[2] = { (float)2.0,(float)1.3,'A' };
data[3] = { (float)5.3,(float)9.9,'B' };
data[4] = { (float)8.2,(float)8.9,'B' };
data[5] = { (float)5.1,(float)9.0,'B' };
}
//
char KNN(Data &input, Data *trainData, int K,char *tag) {
//保存新数据到各个训练数据的欧式距离
float *dist = (float *)malloc(sizeof(float)*Size_trainData);
int *count = (int *)malloc(sizeof(int)*Data_type);
int i;
for (i = 0; i < Data_type; count[i++] = 0);
for (i = 0; i < Size_trainData; dist[i++] = 0);
char *result = tag;
for (i = 0; i < Size_trainData; ++i) {
float x = trainData[i]._x - input._x;
float y = trainData[i]._y - input._y;
x *= x;
y *= y;
dist[i] = sqrt(x + y);
}
int *arg = (int *)malloc(sizeof(int)*K);
argsort(K,dist,arg);
for (i = 0; i < K; ++i) {
for (int j = 0; j < Data_type; ++j) {
if (trainData[arg[i]]._tag == tag[j])
++count[j];
}
}
int flag;
int max = 0;
for(i=0;i<Data_type;++i)
if (max < count[i]) {
flag = i;
max = count[i];
}
return result[flag];
}
//重构函数,如果数据不是读取文件而是用上面Create_trainData函数就用这个
char KNN(Data &input, Data *trainData, int K) {
//保存新数据到各个训练数据的欧式距离
float *dist = (float *)malloc(sizeof(float)*Size_trainData);
int *count = (int *)malloc(sizeof(int)*Data_type);
int i;
for (i = 0; i < Data_type; count[i++] = 0);
for (i = 0; i < Size_trainData; dist[i++] = 0);
char result[2] = { 'A','B' };
for (i = 0; i < Size_trainData; ++i) {
float x = trainData[i]._x - input._x;
float y = trainData[i]._y - input._y;
x *= x;
y *= y;
dist[i] = sqrt(x + y);
}
int *arg = (int *)malloc(sizeof(int)*K);
argsort(K, dist, arg);
for (i = 0; i < K; ++i) {
if (trainData[arg[i]]._tag == 'A')
++count[0];
else
++count[1];
}
int flag;
int max = 0;
for (i = 0; i<Data_type; ++i)
if (max < count[i]) {
flag = i;
max = count[i];
}
return result[flag];
}
//排序,然后返回前K位在原数组中的下标
void argsort(int K,float *arr,int *label){
int *tmp = (int *)malloc(sizeof(int)*Size_trainData);
int *cmp = (int *)malloc(sizeof(int)*Size_trainData);
int i;
for (i = 0; i < Size_trainData; cmp[i] = (int)(arr[i++]*1000));
for (i = 0; i < Size_trainData; tmp[i] = (int)(arr[i++]*1000));
quick_sort(tmp, 0, Size_trainData - 1);
for (i = 0; i < K; ++i) {
for (int j = 0; j < Size_trainData; ++j) {
if (abs(tmp[i] == cmp[j]))
label[i] = j;
}
}
}
void quick_sort(int *arr, int low, int high) {
if (low < high) {
int i = low, j = high, pivot = arr[low];
while (i < j) {
while (i < j&&arr[j] >= pivot) //从右开始遍历,直到找到小于pivot的值为止
--j;
if (i < j)
arr[i++] = arr[j];
while (i < j&&arr[i] <= pivot) //从左开始遍历直到找到大于pivot的值为止
++i;
if (i < j)
arr[j--] = arr[i];
}
arr[i] = pivot;
quick_sort(arr, low, i - 1);
quick_sort(arr, i + 1, high);
}
}
//注释掉部分是使用程序输入训练数据的
void main() {
//Data trainData[Len_trainData];
//Create_trainData(trainData);
train_Data training;
Data *trainData = training.get_trainedData();
Data input = { (float)1.0,(float)1.0 };
//char result = KNN(input, trainData, 5);
char result = KNN(input, trainData, 5,training.get_dataTag());
cout << result << endl;
Data input1 = { (float)8.0,(float)10.9 };
//char result1 = KNN(input1, trainData, 5);
char result1 = KNN(input1, trainData, 5, training.get_dataTag());
cout << result1 << endl;
}















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









