







 本文探讨了神经网络加速的重要性,指出CPU和GPU在能效和性能上的局限,而FPGA因其高能效比和灵活性成为理想选择。尽管FPGA面临存储、I/O带宽和计算资源限制,但通过优化存储、架构和数据通路,可以实现高速度和高能效。文章介绍了神经网络的基本结构和主要计算层,强调了卷积层和全连接层的加速关键性,并讨论了FPGA加速器设计的目标——高速度和高能效,以及实现这些目标的策略。
本文探讨了神经网络加速的重要性,指出CPU和GPU在能效和性能上的局限,而FPGA因其高能效比和灵活性成为理想选择。尽管FPGA面临存储、I/O带宽和计算资源限制,但通过优化存储、架构和数据通路,可以实现高速度和高能效。文章介绍了神经网络的基本结构和主要计算层,强调了卷积层和全连接层的加速关键性,并讨论了FPGA加速器设计的目标——高速度和高能效,以及实现这些目标的策略。
基于FPGA的深度学习加速器优化(一)
神经网络加速
神经网络算法相较于传统的深度学习算法在很多方面都有较大的优势,不同的网络模型在图像、视频以及语音等领域发挥出越来越重要的作用,例如卷积神经网络CNN、递归神经网络RNN等等。但对于神经网络模型来说,其计算量和存储需求是非常大的,如下表所示:

因此,针对基于神经网络的应用选择合适的计算平台是非常重要的。典型的CPU平台计算能力约为10-100G FLOP/s,能效通常低于1GOP/J。因此CPU平台既不能满足云端应用高性能的需求也不能满足移动端低能耗的要求。而GPU平台的峰值算力可以达到10TOP/s,同时像Caffe、TensorFlow等框架也提供了针对GPU加速的接口,非常适合于高性能要求的应用,然而其能效比较低。而FPGA平台相较于CPU、GPU具有很高的能效比,同时FPGA灵活性比较高,相较于AISC的实现方式,成本较低,周期短。
但同时基于FPGA的神将网络加速也面临着一些挑战:
(1)FPGA平台相较于GPU其存储空间、I/O带宽、计算资源等通常都是有限的;
(2)目前大多数FPGA平台的工作频率通常在100-300MHz之间,远远低于CPU或者GPU平台工作频率;
(3)神经网络算法在FPGA上的部署难度要大大高于CPU或者GPU平台。
因此,直接简单的部署设计将不能实现高能效和高性能,需要在存储、架构、数据通路等等各方面进行优化。
神经网络
深度神经网络是深度学习概念的一种实现,是人工智能(AI)中的一小块。NN算法将原始的传感器数据按照时间或者空间的形式传进高度抽象的模型中以提取有用的信息。这个过程就叫做推理,推理包括多级非线性处理过程,每一个过程称为一个层(layer),每个层以上一层的输出作为输入,并产生下一层的输入。其基本结构如下图:
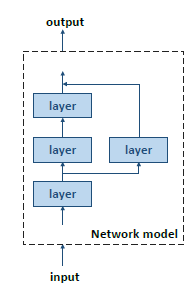
在神经网络算法中,尽管有很多种类型的操作,但是在深度学习神经网络中有两种基本的层类型:卷积层(CONV)和全连接层(FC),其结构如下所示:
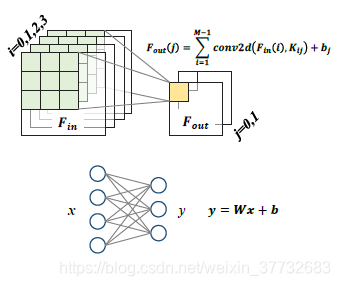
卷积层CONV针对一系列输入特征图像Fin进行二维卷积计算,并对结果进行累加得到输出特征图像Fout,全连接层以特征图像向量作为输入执行矩阵向量乘的操作。除了卷积层和全连接层之外,神经网络还有池化层(POOLING)、ReLU、Contact等等,但卷积层和全连接层贡献了神经网络的主要的计算量和参数量,以VGG-11为例,其不同层的计算量和参数量贡献如下:

因此大多数针对神经网络的加速主要研究针对卷积层和全连接层的加速。
基于FPGA的神经网络加速器设计
针对推理应用的FPGA加速器的设计主要有两个设计目标:高速度(high throughput and low lantency )以及高能效。
高速度
神经网络加速器的算力可以表示如下:
I P S = O P S a c t W = f P × η W IPS =\frac{
{OPS_{act}}}{W}=\frac{
{fP\times\eta}}{W} IPS=W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2106
2106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









