







参考的文章
Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks
这是发布在2015FPGA上的论文,7年前的了,作为入门蛮不错的。
卷积层模型
我们先看卷积层的图示和基础伪代码,并以此为基础展开讨论。

Figure 1是卷积层的图示,Code 1是卷积层的伪代码。
- output_fm为输出特征图,维度为M×R×C,M个通道R行C列
- input_fm为输入特征图,维度为N×(SR+K)×(SR+K),N个通道(SR+K)行(SR+K)列
- wieghts为权重,维度为M×N×K×K
有以下重要的符号
- 输入特征图通道数:N
- 输出特征图通道数:M
- 步幅Stride:S
- 卷积核尺寸:K
- 输入特征图尺寸:(SR+K)×(SR+K)
- 输出特征图尺寸:R×C
加速器概述
有了Code 1,并理解了卷积层涉及到的各层循环含义、各个符号表示的意思。我们开始设计加速器。

借助Figure 4,我们对加速器有个直观的概念。我们从DDR上,加载(load)输入特征图(input_fm)和权重(weights),在PE里计算得到输出特征图(output_fm),将输出特征图存储(store)到DDR
循环分块
接着·,我们要讲一讲循环分块技术(loop tiling),下面这张图我是从知乎陈清扬的文章上截取的。循环分块技术,在处理器上主要是为了提高Cache命中率的一种加速手段,在加速器设计的论文里写Tiling的公式应该是指这部分运算可以并行展开。

简单的讲,就是,把大循环分块成若干个小循环,在每一块小循环里,并行开展计算。主要是为了控制资源使用。于是有了下面的图,Figure 5。

我们来理解一下Figure 5。对外面的4层循环进行分块。出现了4个新的符号。
- Tr:行分块系数
- Tc:列分块系数
- Tm:输出通道分块系数
- Tn:输入通道分块系数
unroll与pipeline
我们对每一小块内部做并行计算,就是Figure 5里方框圈出的部分。
对于这种循环,做并行加速,有两个可用的策略。
- unroll:循环展开,把循环体的内容完全展开,这个比较顶,消耗的资源数和端口数多,带来的吞吐量大
- pipeline:循环流水线,该循环不间断运行

在Code 3加速器架构里,对to和ti两个维度unroll,从而输出通道并行度Tm,输入通道并行度Tn,下面的图可很好的示意

分块系数的确定
有了图5,我们可以计算评价系统吞吐量的指标:

首先解释分子部分,其中,系数2是因为一次乘法和一次加法。后面是各个维度的尺寸的乘积。
分母部分,前四项,是循环分块后外层的四个循环。
从等式我们可以看出来,决定系统吞吐量的,是Tm和Tn,要在芯片资源限制下选择尽量高的Tm与Tn。
下图给出了约束式。
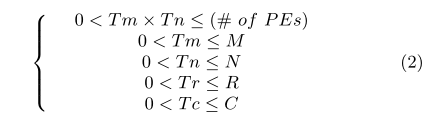















 857
857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









