







 本文介绍如何使用Pandas进行论文作者统计,包括数据读取、字符串处理,通过统计作者出现频率的Top10,以及作者姓的频率,展示了Python在数据处理中的应用。
本文介绍如何使用Pandas进行论文作者统计,包括数据读取、字符串处理,通过统计作者出现频率的Top10,以及作者姓的频率,展示了Python在数据处理中的应用。
2.1 任务说明
- 任务主题:论文作者统计,统计所有论文作者出现评率Top10的姓名;
- 任务内容:论文作者的统计、使用 Pandas 读取数据并使用字符串操作;
- 任务成果:学习 Pandas 的字符串操作;
2.2 数据处理步骤
在原始arxiv数据集中论文作者authors字段是一个字符串格式,其中每个作者使用逗号进行分隔分,所以我们我们首先需要完成以下步骤:
- 使用逗号对作者进行切分;
- 剔除单个作者中非常规的字符;
- 具体操作可以参考以下例子:
C. Bal\\'azs, E. L. Berger, P. M. Nadolsky, C.-P. Yuan
# 切分为,其中\\为转义符
C. Ba'lazs
E. L. Berger
P. M. Nadolsky
C.-P. Yuan
当然在原始数据集中authors_parsed字段已经帮我们处理好了作者信息,可以直接使用该字段完成后续统计。
2.3 字符串处理
在Python中字符串是最常用的数据类型,可以使用引号('或")来创建字符串。Python中所有的字符都使用字符串存储,可以使用方括号来截取字符串,如下实例:
var1 = 'Hello Datawhale!'
var2 = "Python Everwhere!"
print("var1[-10:]: ", var1[-10:])
print("var2[1:5]: ", var2[0:7])
执行结果为:
var1[-10:]: Datawhale!
var2[1:5]: Python
使用split可以达到类似的效果:
print("var1[-10:]: ",var1.split(' ')[0])
print("var2[1:5]: ",var2.split(' ')[0])
执行结果为:
var1[-10:]: Datawhale!
var2[1:5]: Python
同时在Python中还支持转义符:
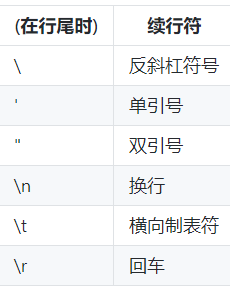
Python中还内置了很多内置函数,非常方便使用:

还可以使用正则表达式匹配复合规则的文本以及替换等操作,更多内容可以看我之前写的文本数据操作,基本可以满足日常使用。
2.4 具体代码实现以及讲解
2.4.1 数据读取
import json # 读取数据,我们的数据为json格式的
data = []
with open("./data/arxiv-metadata-oai-snapshot.json", 'r') as f:
for idx, line in enumerate(f):
d = json.loads(line)
d = {
'authors': d['authors' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









