






一、什么是Event Loop
Event Loop指的是计算机系统的一种运行机制,在JavaScript中就是采用Event Loop这种机制来解决单线程带来的问题。
1.1. 关于JavaScript为什么要设计成单线程?
这主要和js的用途有关,js是作为浏览器的脚本语言,主要是实现用户与浏览器的交互,以及操作dom;这决定了它只能是单线程,否则会带来很复杂的同步问题。
举个例子:如果js被设计了多线程,假如有一个线程要修改一个dom元素,另一个线程要删除这个dom元素,此时浏览器就会一脸茫然,不知所措。所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
要理解Event Loop,首先要理解程序运行的模式,运行以后的程序叫做进程,一般情况下一个进程一次只能执行一个任务,如果有多个任务需要执行,有三种解决办法:
(1)排队。 因为一个进程一次只能执行一个任务,只好等前面的任务执行完了,再执行后面的任务。
(2)新建进程。 使用fork命令,为每个任务新建一个进程。
(3)新建线程。 因为进程太耗费资源,所以如今的程序往往允许一个进程包含多个线程,由线程去完成任务。
1.2. 进程和线程的概念
简单点说,进程是车间,线程是打工仔,车间可以容纳多个打工仔,打工仔们共用车间内的资源,一个打工仔一次只能做一件事情。

详情不再展开,关于进程和线程的概念这里推荐阮一峰老师的文章,图文并茂,解释的非常生动有趣: https://www.ruanyifeng.com/blog/2013/04/processes_and_threads.html
1.3. 同步和异步 && 阻塞和非阻塞
JavaScript是单线程语言,要执行多个任务只能排队,如果前面的同步任务耗时过长,势必会阻塞后面任务的执行。因此JavaScript需要一种异步机制来让处理这些耗时的任务,并且在处理完成后进行通知,Event Loop就设计出来了。
在浏览器端JavaScript主要是利用了浏览器内核多线程实现异步的,浏览器是一个多进程的架构,以开源的Chromium为例,它有五个进程,我们需要关心的是渲染进程,渲染进程属于浏览器核心进程。


以下面这段代码为例,先输出something,1s后再输出timeout,因为定时器是在浏览器的定时触发器线程执行的,console.log在js主线程执行,主线程代码执行完成后空闲了才会去读队列中已完成的任务
setTimeout(() => {
console.log('timeout')
}, 1000)
console.log('something')关于浏览器多进程架构参考文章: https://juejin.cn/post/6844903701526642702
在Node端同样也是借助多进程架构来实现异步的,很多人说node.js是单线程的,这个说法比较片面,node.js单线程的原因是因为它接收的任务是单线程的(参考后面的node.js整体运行机制),但是Node本身是一个多进程架构。
关于Node多进程架构参考文章: https://juejin.cn/post/6999607396884545550
以下这些概念不用记,忘记了过来查一下即可,但了解这些概念有助于帮助我们理解Event Loop的运行机制。
1、什么是阻塞和非阻塞?
阻塞和非阻塞是针对于进程在访问数据时,根据IO操作的就绪状态而采取的不同方式,简单来说是一种读取或写入操作函数的实现方式,阻塞方式下读取或写入函数将一直等待。非阻塞方式下,读取和写入函数会立即返回一个状态值。
2、什么是异步和同步?
同步和异步是针对应用程序和内核的交互而言的,同步是指用户进程触发IO操作并等待或轮询的查看IO操作是否就绪,异步是指用户进程触发IO操作以后便开始做自己的事情,当IO操作完成时会得到通知,换句话说异步的特点就是通知。
3、什么是I/O模型?
一般而言,IO模型可以分为四种:同步阻塞、同步非阻塞、异步阻塞、异步非阻塞
- 同步阻塞IO是指用户进程在发起一个IO操作后必须等待IO操作完成,只有当真正完成了IO操作后用户进程才能运行。
- 同步非阻塞IO是指用户进程发起一个IO操作后立即返回,程序也就可以做其他事情。但是用户进程需要不时的询问IO操作是否就绪,这就要求用户进程不停的去询问,从而引入不必要的CPU资源浪费。
- 异步阻塞IO是指应用发起一个IO操作后不必等待内核IO操作的完成,内核完成IO操作后会通知应用程序。这其实是同步和异步最关键的区别,同步必须等待或主动询问IO操作是否完成,那么为什么说是阻塞呢?因为此时是通过select系统调用来完成的,而select函数本身的实现方式是阻塞的,采用select函数的好处在于可以同时监听多个文件句柄,从而提高系统的并发性。
- 异步非阻塞IO是指用户进程只需要发起一个IO操作后立即返回,等IO操作真正完成后,应用系统会得到IO操作完成的通知,此时用户进程只需要对数据进行处理即可,不需要进行实际的IO读写操作,因为真正的IO读写操作已经由内核完成。
再看一张图加深一下理解:

更详细的概念请参考如下文章进行学习:
https://www.jianshu.com/p/458e4b276607
1.4. 为什么要设计Event Loop?
这个问题反映到我们生活中也是一样的道理,你一天要干很多事情,有一些事情又很耗时但是它又没那么重要,你会不会想办法来提高自己的效率好让自己解放出来呢?这样你才能合理利用一天的时间去做更重要的事情。于是人们发明了各种工具,洗衣机、电饭煲等等。你不用关心它是怎么做的,什么时候做完,洗好衣服你去晒,做好饭你去吃,你只需要把任务交给它,处理好了它就会通知你,你什么时候有空了再去处理结果就可以了。
这个例子中,你是一个人,不能同时做很多事情,反映到代码中你是单线程,你把耗时的任务交给这些工具,工具完成后会通知你结果,你就解放出来了可以先去做更重要的事情,这就是Event Loop的作用。
结合以上的知识点,我想你对为什么要设计Event Loop已经有了自己的理解。
阮一峰老师的这篇文章也很好的解释了这个问题:
http://www.ruanyifeng.com/blog/2013/10/event_loop.html
二、node的Event Loop
请注意,本节所学习的node版本为v10,在v10版本之后Event Loop的行为已经与浏览器保持一致。
2.1. Event Loop设计理念
以下引用摘自node中文网
事件循环是 Node.js 处理非阻塞 I/O 操作的机制——尽管 JavaScript 是单线程处理的——当有可能的时候,它们会把操作转移到系统内核中去。
既然目前大多数内核都是多线程的,它们可在后台处理多种操作。当其中的一个操作完成的时候,内核通知 Node.js 将适合的回调函数添加到 轮询(poll) 队列中等待时机执行。
链接:https://nodejs.org/zh-cn/docs/guides/event-loop-timers-and-nexttick/#node-js-process-nexttick
简单来说Event Loop就是一种处理非阻塞I/O操作的机制,借助内核多线程的特点,在后台处理各种各样的操作,处理完成后内核会通知Node.js来进行处理。

就像你去餐厅点餐一样,你不用关心你点的这份餐怎么做出来的,餐做好了就会在大厅叫号牌上显示对应的号码,然后提醒你取餐,你不需要站在那等待出餐这个漫长的过程。
在高性能的I/O设计中,有两个比较著名的模式Reactor和Proactor模式,其中Reactor模式用于同步I/O,Proactor用于异步I/O操作。
node采用了Reactor设计模式。那么什么是Reactor模式?
Reactor模式是处理并发I/O常见的一种模式,用于同步I/O,其中心思想是将所有要处理的I/O事件注册到一个中心I/O多路复用器上,同时主线程阻塞在多路复用器上,一旦有I/O事件到来或是准备就绪,多路复用器将返回并将相应I/O事件分发到对应的处理器中。
Reactor是一种事件驱动机制,和普通函数调用不同的是应用程序不是主动的调用某个API来完成处理,恰恰相反的是Reactor逆置了事件处理流程,应用程序需提供相应的接口并注册到Reactor上,如果有相应的事件发生,Reactor将主动调用应用程序注册的接口(回调函数)。
关于Reactor设计模式可学习如下文章:
https://www.jianshu.com/p/458e4b276607
2.2. libuv
我们都知道node能够运行在不同的平台上,由于在不同操作系统平台上支持所有类型的非阻塞I/O非常困难和复杂,就需要有一个抽象层来管理这些复杂的,跨平台的东西,这个抽象层就是——libuv。
Event Loop就是由libuv提供的。
以下引用自libuv官方文档
libuv 是一个跨平台的支持库,最初是为Node.js 编写的。它是围绕事件驱动的异步 I/O 模型设计的。
该库提供的不仅仅是针对不同I/O轮询机制的简单抽象,“handles”和“streams”为套接字和其他实体提供了更高级抽象;除此之外,还提供了跨平台文件I/O和线程功能。
对libuv感兴趣请参考链接进行学习:http://docs.libuv.org/en/v1.x/design.html
2.3. node.js的整体运行机制
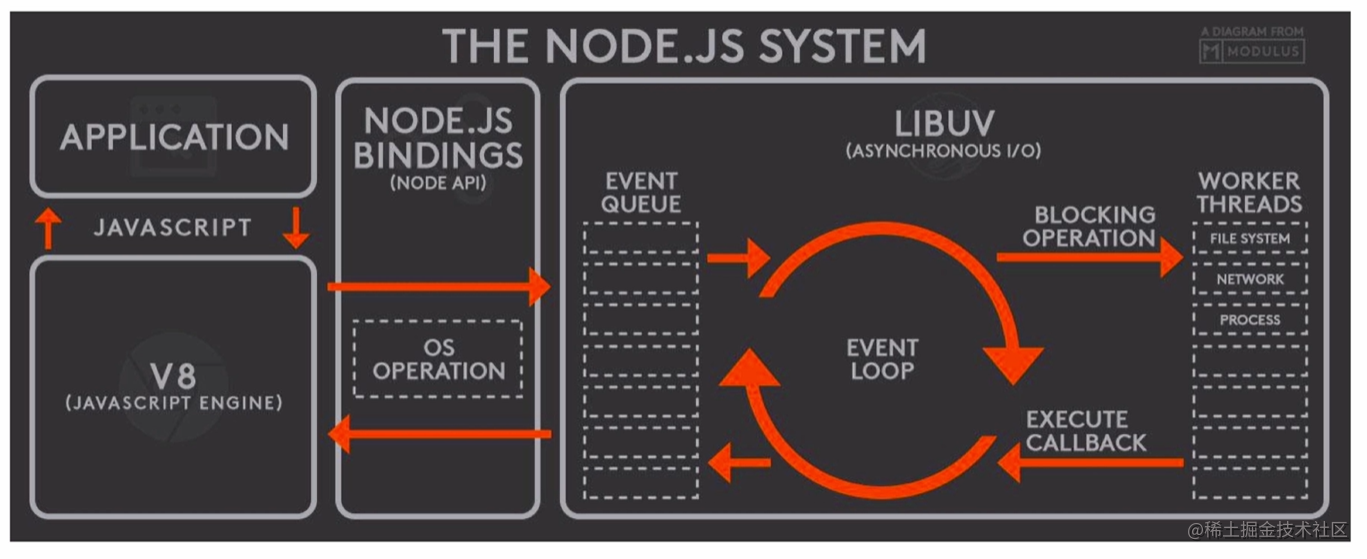
上图中,用户输入JavaScript代码,由V8引擎进行解析,V8调用Node API然后由libuv进行处理,libuv提供Event Loop来处理各类任务,处理完成后将结果返回给V8,V8再将结果返回给用户。
node.js使用了事件驱动模型,该模型包含一个Event Demultiplexer和一个 Event Queue,所有的I/O请求最终会生成一个completion/failure事件或其他触发器,事件会根据以下算法进行处理:
- Event Demultiplexer 接收I/O请求并将这些请求委托给适当的硬件
- 一旦处理了I/O请求(例如,文件中的数据可供读取、套接字中的数据可供读取等),Event Demultiplexer 会把相应的回调函数添加到一个队列里面。这些回调称为事件,添加事件的队列称为Event Queue
- 处理Event Queue中的事件时,将按照事件添加的顺序依次执行,直到队列为空。
- 如果Event Queue中没有事件,或者Event Demultiplexer没有挂起的请求,程序将完成。否则,重复上面的步骤。
调度整个机制的程序称为事件循环(Event Loop)。
Event Demultiplexer
Event Demultiplexer 不是真实存在的一个部件,它仅仅是 Reactor Pattern 的一个抽象。在真实环境中,不同的操作系统都会实现自己的 Event demultiplexer 。如 linux上 的 epoll、bsd 系统(macos)上的kqueue、solaris中的event ports、windows中的iocp等。node.js可以通过这些已实现的Event demultiplexer使用无阻塞、异步的I/O。
Event Queue
- nodejs中有多个队列,其中不同类型的事件在它们自己的队列中排队。
- 在处理完一个阶段之后,在转到下一个阶段之前,事件循环将处理两个中间队列,直到中间队列中没有剩余的项为止。
2.4. 有多少种队列?中间队列是什么?
有4种类型的队列由本机libuv事件循环处理:
- timers队列——已过期的timer回调(setTimeout、setInterval)
- I/O事件队列——已完成的I/O事件(readFile等)
- Immediates队列——setImmediate的回调
- close事件队列——close事件的回调(socket关闭等)
还有2个中间队列:(虽然这两个队列不属于libuv,但它们是node.js的一部分)
- nextTick队列——process.nextTick的回调
- microtask队列——如promise
libuv引擎Event Loop处理这几种队列的循环图如下:

Event Loop启动后,首先处理timers队列,再到I/O事件队列,接着处理immediate队列,最后处理close事件队列,在处理完一个阶段即将要切换到下一个阶段之前,会先处理nextTick队列,清空nextTick队列之后再处理microtask队列,等到microtask队列清空后才会进入下一个阶段。
nextTick队列比microtask队列优先级更高,意味着如果有nextTick队列,会在处理microtask队列之前就把nextTick队列都清空。
参考文章:https://zhuanlan.zhihu.com/p/87396353
2.5. Event Loop运行机制
node.js启动时会初始化事件循环(Event Loop)机制,每次循环都会包含如下6个阶段,每个阶段都有一个先进先出(FIFO)的用于执行回调的队列,通常事件循环运行到某个阶段时,node.js会先执行该阶段的操作,然后再去执行该阶段队列里的回调,直到队列里的内容耗尽,或者执行的回调数量达到最大(maximum number,最大值由当前机器性能决定)。每一个阶段完成后,事件循环就会检查这两个中间队列中是否有内容,如果有立马执行,直到这两个队列清空为止,等到它们清空,事件循环才会进入下一个阶段,如此往复循环,直到进程结束。
liubv引擎Event Loop的6个阶段:
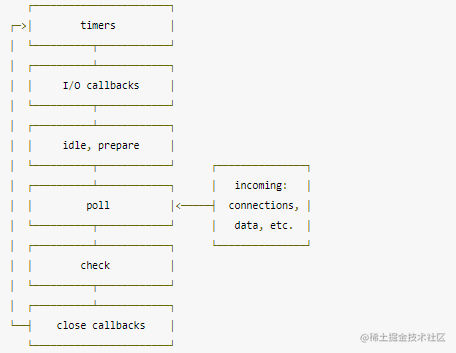
- timers 阶段:这个阶段执行timer(setTimeout、setInterval)的回调
- I/O callbacks(pending callbacks) 阶段:已完成的、报错且未被处理的I/O的回调都会在这里被执行
- idle, prepare 阶段:仅node内部使用,只是表达空闲、预备状态(第二阶段结束,poll未触发之前)
- poll 阶段:等待任意一个新的I/O完成,执行I/O相关回调, 适当的条件下node将阻塞在这里
- check 阶段:在轮询I/O之后执行一些事后工作,通常是执行 setImmediate() 的回调
- close callbacks 阶段:执行一些关闭的回调函数,如执行 socket 的 close 事件回调
在node.js里,任何异步方法(除timer,close,setImmediate之外)完成时,都会将其callback加到poll queue里,并立即执行。
通过上面的知识可以总结出:一个阶段执行完毕进入下一个阶段之前,Event Loop会先清空microtask队列的任务(如果有nextTick队列,则先清空nextTick队列然后再清空microtask队列),等到microtask队列清空后再进入下一个阶段,如下图所示:

我们重点看timers、poll、check这3个阶段就好,因为日常开发中的绝大部分异步任务都是在这3个阶段处理的。
2.5.1. timers 阶段
timers是事件循环的第一个阶段,当我们使用setTimeout或者setInterval时,node会添加一个timer到timers堆,当事件循环进入到timers阶段时,node会检查timers堆中有无过期的timer,如果有,则依次执行过期timer的回调函数。
关于timers堆学习参考:https://blog.csdn.net/tinnfu/article/details/51812166
需要注意的是,node不能保证到了过期时间就立即执行回调函数,因为它在执行回调前必须先检查timer是否过期,检查的过程是需要消耗时间的,这个时间的长短取决于系统性能,性能越好执行速度越快,另外一点是,如果当前Event Loop中还有别的进程在执行,也会影响timer回调的执行。这与浏览器的Event Loop机制是类似的,浏览器环境中如果定时器在一个非常耗时的for循环之后运行,虽然时间已过期,仍然要等到for循环计算完成才会执行定时器的回调。
在到达过期时间之间的时间称为有效期,定时器能够保证的就是至少在给定的有效期内不会触发定时器回调。
以下引用自node中文网:
计时器指定 可以执行所提供回调 的 阈值,而不是用户希望其执行的确切时间。在指定的一段时间间隔后, 计时器回调将被尽可能早地运行。但是,操作系统调度或其它正在运行的回调可能会延迟它们。
注意:轮询(poll) 阶段 控制何时定时器执行。
也就是说:poll阶段控制timer什么时候执行,而执行的具体位置在timers阶段
示例:创建一个延时1s的setTimeout,记录执行回调花费的时间
// 获取纳秒级计时精度-node才有
// 参考文档:https://www.cnblogs.com/boychenney/p/12195632.html
const start = process.hrtime();
setTimeout(() => {
const end = process.hrtime(start);
console.log(`timeout callback executed after ${end[0]}s and ${end[1]/Math.pow(10,9)}ms`);
}, 1000);多次运行程序,你会发现它每次打印的结果都不同,执行回调的间隔都大于1s
timeout callback executed after 1s and 0.0000775ms
timeout callback executed after 1s and 0.0023212ms
timeout callback executed after 1s and 0.000102ms
......在node中,setTimeout和setImmediate在一起使用时也会发生不同的情况,例如:
setTimeout(function timeout () {
console.log('timeout');
}, 0);
setImmediate(function immediate () {
console.log('immediate');
});上面的代码第一眼看上去肯定总是先打印timeout,再打印immediate,因为setImmediate的回调在check队列中,按照步骤应该是先检查过期timer,然后再到check队列中执行setImmediate的回调才对。
实际结果并不是这样,如下所示,多次运行后会得到不同的输出结果
$ node timeout_vs_immediate.js
timeout
immediate
$ node timeout_vs_immediate.js
immediate
timeout原因是setTimeout(fn, 0)无法保证timer回调在0秒后立即被调用,通过前面的学习我们知道当Event Loop启动时会先检查timer是否过期。如果它检查的过程耗时比较长,它可能不会立即看到过期的timer,然后就略过了timer阶段走走走走到了check阶段,看到check队列有一个事件,于是执行输出immediate,之后在下一个时间循环中执行setTimeout的回调。
但是,当二者在异步I/O callback内部调用时,总是先执行setImmediate,再执行setTimeout
var fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout')
}, 0)
setImmediate(() => {
console.log('immediate')
})
})
// 多次执行结果相同
// immediate
// timeout理解了Event Loop的各阶段顺序这个例子很好理解:
因为fs.readFile callback执行完后,程序设定了timer 和 setImmediate,因此poll阶段不会被阻塞进而进入check阶段先执行setImmediate,后进入timer阶段执行setTimeout。(后面会详细给出运行步骤)
二者非常相似,但是二者区别取决于他们什么时候被调用
- setImmediate 设计在poll阶段完成时执行,即check阶段;
- setTimeout 设计在poll阶段为空闲时,且设定时间到达后执行(在poll阶段阻塞时会检查有无过期timer,有则回到timers阶段执行timer的回调);
其二者的调用顺序取决于当前Event Loop的上下文,如果他们在异步i/o callback之外调用,其执行先后顺序是不确定的,执行的顺序不确定,就是因为每一次loop,最开始和结束时都检查timer的缘故。
2.5.2. poll 阶段
poll 阶段主要有2个功能:
- 处理 poll 队列的事件
- 计算应该阻塞和轮询I/O的时间(当有新的I/O完成,I/O callback加入poll queue,然后执行I/O callback;当有已超时的 timer,进入timers阶段执行它的回调函数)
如果event loop进入了 poll阶段,且代码未设定timer,将会发生下面情况:
如果poll queue不为空,event loop将同步的执行queue里的callback,直至queue为空,或执行的callback到达系统上限;
如果poll queue为空,将会发生下面情况:
- 如果代码已经被setImmediate()设定了callback, event loop将结束poll阶段进入check阶段,并执行check阶段的queue (check阶段的queue是 setImmediate设定的)
- 如果代码没有设定setImmediate(callback),event loop将阻塞在该阶段等待callbacks加入poll queue,然后立即执行;
如果event loop进入了 poll阶段,且代码设定了timer:
- 如果poll queue进入空状态时(即poll 阶段为空闲状态),event loop将检查timers,如果有1个或多个timers时间时间已经到达,event loop将按循环顺序进入 timers 阶段,并执行timer queue。
通过下图再来加深一下理解

- Event Loop进入poll阶段,进入poll阶段后查看poll阶段队列中是不是空的或者callbacks数量到了上限
- 如果不是空的callbacks也没有到上限,就执行poll队列里面的callback,循环这个过程直到poll队列空了或者到了限制
- 这个时候看一下setImmedidate有没有设置callback,如果有就进入check阶段
- 如果没有设置就会有一个等待状态,会等待callback加入poll队列里面,此时如果有新的callback,就会再次进入poll队列去检查,然后循环上面的步骤
- 在等待callback加入poll队列空闲的时候,会去检查定时器有没有到时间,如果定时器到时间了又有对应的callback,它就会进入timers定时器阶段去执行timer queue中的callback
- 如果定时器没有到时间,就会继续等待
node官方提供的一个示例:假设您调度了一个在 100 毫秒后超时的定时器,然后您的脚本开始异步读取会耗费 95 毫秒的文件
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});代码中创建了一个someAsyncOperation异步读文件的方法,然后创建了一个常量timeoutScheduled取当前时间,然后有一个setTimeout,里面计算延时多少毫秒之后打印一句话,最后一段是调用someAsyncOperation这个异步方法,读完文件后执行callback,callback里面执行一个空的while循环,我们可以理解为睡眠10毫秒。
当事件循环进入 轮询 阶段时,它有一个空队列(此时 fs.readFile() 尚未完成),因此它将等待剩下的毫秒数,直到达到最快的一个计时器阈值为止。当它等待 95 毫秒过后时,fs.readFile() 完成读取文件,它的那个需要 10 毫秒才能完成的回调,将被添加到 轮询 队列中并执行。当回调完成时,队列中不再有回调,因此事件循环机制将查看最快到达阈值的计时器,然后将回到 计时器 阶段,以执行定时器的回调。在本示例中,您将看到调度计时器到它的回调被执行之间的总延迟将为 105 毫秒。
2.5.3. check 阶段
这个阶段允许在poll阶段结束后立即执行回调,如果poll阶段空闲并且有被setImmediate设置回调,那么事件循环直接跳到check阶段执行而不是阻塞在poll阶段等待回调被加入。
setImmediate实际上是一个特殊的timer,跑在事件循环中的一个独立的阶段。它使用libuv的API来设定在poll阶段结束后立即执行回调。setImmediate的回调会被加入check队列中, 从event loop的阶段图可以知道,check阶段的执行顺序在poll阶段之后。
2.5.4. 小结
- event loop 的每个阶段都有一个该阶段对应的队列和一个microtask队列
- 当 event loop 到达某个阶段时,将执行该阶段的任务队列(先执行阶段队列,再执行microtask队列),直到队列清空或执行的回调达到系统上限后,才会转入下一个阶段
- 当所有阶段被顺序执行一次后,称 event loop 完成了一个 tick
再来看一段代码示例:(假设要读取的文件需要100ms)
const fs = require('fs')
fs.readFile('test.txt', () => {
console.log('readFile')
setTimeout(() => {
console.log('timeout')
}, 0)
setImmediate(() => {
console.log('immediate')
})
})
// 执行结果:
// readFile
// immediate
// timeout以上代码执行顺序为:
程序启动时,Event Loop初始化:
进入timers阶段,检查有无过期timer,没有(如果有则执行timer queue中的callback),进入下一个阶段
进入I/O阶段,无异步I/O完成(可忽略)
进入idls阶段,啥也没有,进入下一个阶段(可忽略)
进入poll阶段(没有设置timer),现在poll queue是空的(此时fs.readFile尚未完成),因此它进入等待状态,直到有任务加入队列中,当它等到100ms时fs.readFile完成,将callback加入poll queue,并执行callback,callback执行打印readFile并设置了一个setTimeout和一个setImmediate,然后callback执行完成,poll queue清空。(如果没有设置setImmediate的情况下,当callback完成时,Event Loop将检查有没有到时间的timer,有的话会回到timers阶段来执行timer的回调)
- readFile回调执行打印readFile,然后设置了timer,将timer的回调放入timer queue,将setImmediate的回调放入check queue,根据规则,Event Loop进入poll阶段前如果未设置timer并且poll队列为空会有两种情况,其中一种是如果代码已经被setImmediate设置了callback,Event Loop将结束poll阶段进入check阶段,并执行check queue中的事件,很明显本例中使用setImmediate设置了callback
因此poll阶段不会被阻塞而是进入check阶段,执行setImmediate的回调函数,打印immediate,check queue清空,进入下一个阶段
进入close阶段,没有任务,一次Tick完成,进入下一次Tick
进入timers阶段,检查timer queue有没有过期的timer,有,执行readFile回调中设置的setTimeout回调,打印timeout,进入下一个阶段
······
三、浏览器端和node端Event Loop执行过程对比
通过以下代码来具体观察一下浏览器端和node端的执行过程:
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)3.1. 浏览器的Event Loop流程解析
浏览器端运行结果:timer1 => promise1 => timer2 => promise2
浏览器Event Loop执行动画示意:

浏览器端的执行过程是:
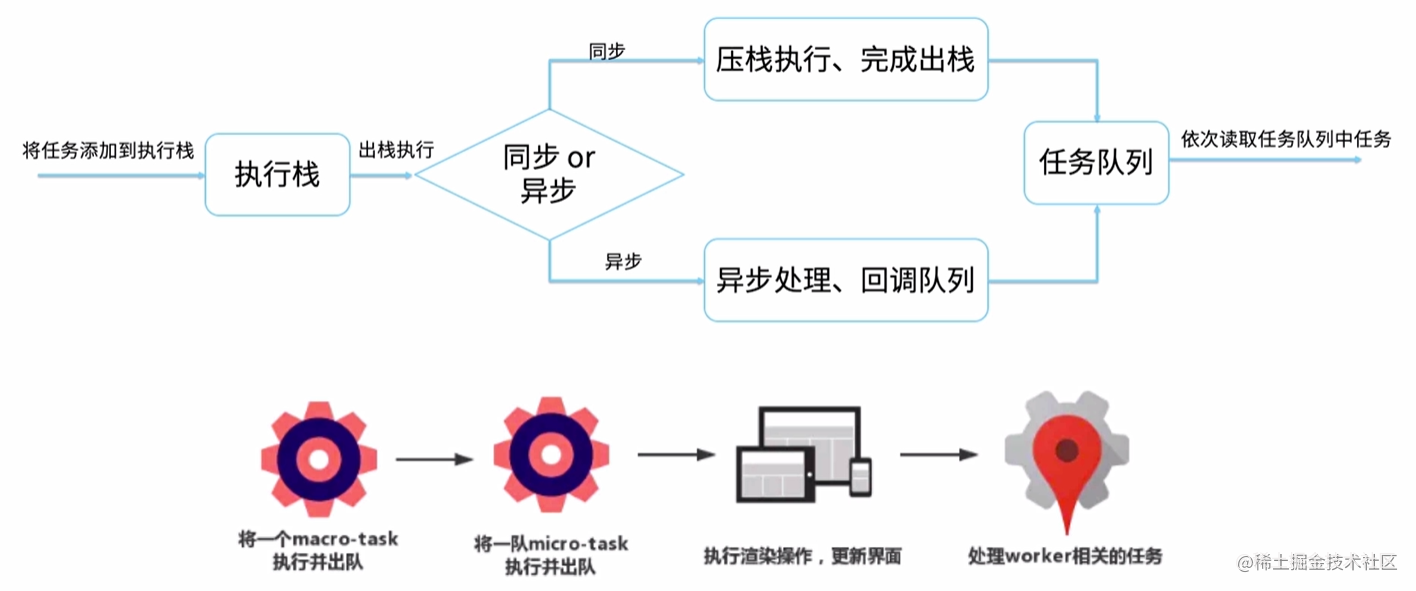
- 主程序main()入栈执行,遇到第一个timer,将timer的回调存入宏任务队列(macrotask),继续往下执行,遇到第二个timer,将回调存入宏任务队列,main()执行完成退栈
- Event Loop开始检查宏任务队列,执行第一个timer的回调函数,打印timer1,并将promise.then()的回调存入微任务队列,timer1的回调执行完成退栈,然后执行微任务队列中的所有任务,打印promise1,再检查有没有宏任务,有,执行,打印timer2,并将promise.then()的回调函数存入微任务,timer2的回调函数执行完成退栈,检查微任务队列并执行,打印promise2
需要注意的是:浏览器Event Loop的宏任务是一个一个执行的,微任务是一队一队执行的,执行完每个宏任务之后都会检查微任务队列,直到将所有微任务都清空后才会继续下一个宏任务,每次将一队微任务执行完成后就会执行渲染操作更新界面。
以下是浏览器端Event Loop的执行流程图:
3.2. node端Event Loop的流程解析
node端运行结果:timer1 => timer2 => promise1 => promise2
node的Event Loop执行动画示意:
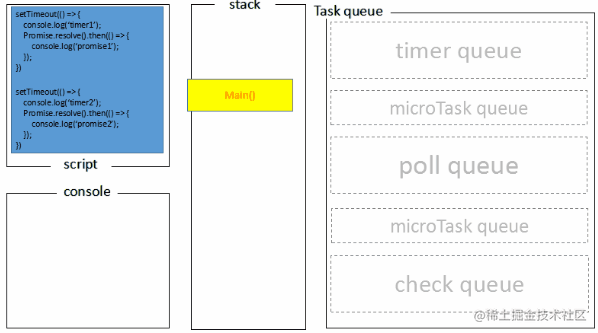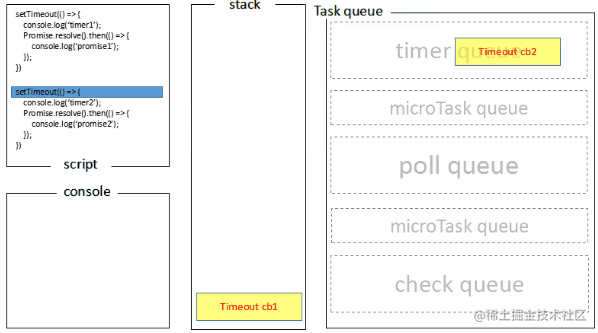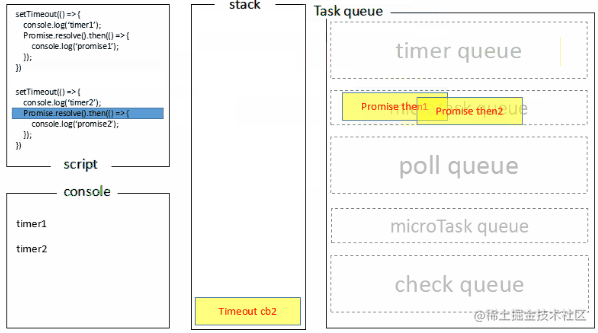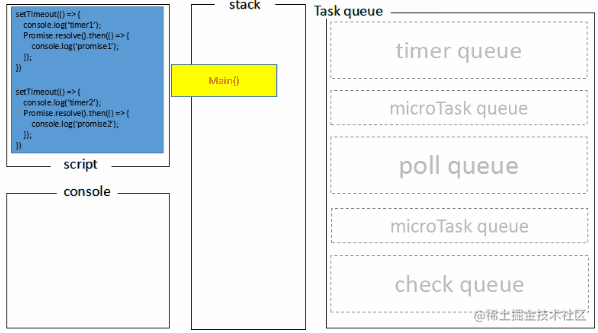
node端Event Loop执行过程分两种情况:
1、检查过期timer消耗的时间小于阈值:
- 主程序main()入栈执行,将2个timer放入timer队列
- Event Loop初始化,进入timers阶段,检查有无过期timer,有,执行timer queue中的callback,打印timer1、timer2,并且分别将两个promise放入microtask queue,执行完成后timer queue清空,进入下一步,检查nextTick queue,没有,检查microtask queue,有,执行microtask queue,打印promise1、promise2,然后microtask queue清空,进入下一步
- ······
2、检查过期timer消耗的时间大于阈值
- 主程序main()开始执行,将2个timer放入timer queue
- Event Loop初始化,进入timers阶段,检查有无过期timer,无,进入下一个阶段
- 进入I/O阶段和idle阶段(忽略)
- 进入poll阶段,检查poll queue,空,等待任务加入的过程中检查有无过期timer,有(假设此时timer过期,如果没过期poll阶段则会继续阻塞等待新任务,等待时会检查有无到期timer),进入timers阶段,执行timer queue中的callback,打印timer1、timer2,并且分别将两个promise放入microtask queue,执行完成后timer queue清空,进入下一步,检查nextTick queue,没有,检查microtask queue,有,执行microtask queue,打印promise1、promise2,然后microtask queue清空,进入下一个阶段
- ······
四、process.nextTick()
4.1. process.nextTick()介绍
官方是这么描述process.nextTick()的

链接:https://nodejs.org/zh-cn/docs/guides/event-loop-timers-and-nexttick/#node-js-process-nexttick
process.nextTick的回调函数会被添加到nextTickQueue,nextTickQueue比其他microtaskQueue具有更高的优先级。尽管它们都在事件循环的两个阶段之间被处理。这意味着nextTickQueue在开始处理microtaskQueue之前就已经被清空。
nextTickQueue的优先级高于promises ,仅仅适用于 promises 是通过v8解析产生的。如果你用了q或者bluebird ,你会观察到完全不同的结果,因为他们先于 promises 执行,且具有不同的语义。
q和bluebird 在处理promise的方式上是不一样的。
关于libuv引擎Event Loop如何处理promise(包含原生Promise、Q promise和BlueBird Promise)和nextTick请参考如下文章:
https://zhuanlan.zhihu.com/p/87623174
process.nextTick()不在event loop的任何阶段执行,而是在各个阶段切换的中间执行,即从一个阶段切换到下个阶段前执行。
示例:
var fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
process.nextTick(()=>{
console.log('nextTick3');
})
});
process.nextTick(()=>{
console.log('nextTick1');
})
process.nextTick(()=>{
console.log('nextTick2');
})
});
// 运行结果
// nextTick1
// nextTick2
// setImmediate
// nextTick3
// setTimeout以上代码执行顺序为:
- 从poll —> check阶段,先执行process.nextTick,打印nextTick1、nextTick2
- 然后进入check阶段,打印setImmediate
- 执行完setImmediate后,出check,进入close阶段前,执行process.nextTick,打印nextTick3,一次Tick完成,进入下一次Tick
- 进入timer执行setTimeout,打印setTimeout
- ······
4.2. process.nextTick() VS setImmediate()
来自官方文档有意思的一句话,从语义角度看,setImmediate() 应该比 process.nextTick() 先执行才对,而事实相反,命名是历史原因也很难再变。
In essence, the names should be swapped. process.nextTick() fires more immediately than setImmediate()
process.nextTick() 会在各个事件阶段之间执行,一旦执行,要直到nextTick队列被清空,才会进入到下一个事件阶段,所以如果递归调用 process.nextTick(),会导致出现I/O starving(饥饿)的问题,比如下面例子的readFile已经完成,但它的回调一直无法执行:
const fs = require('fs')
const starttime = Date.now()
let endtime
fs.readFile('text.txt', () => {
endtime = Date.now()
console.log('finish reading time: ', endtime - starttime)
})
let index = 0
function handler () {
if (index++ >= 1000) return
console.log(`nextTick ${index}`)
process.nextTick(handler)
// console.log(`setImmediate ${index}`)
// setImmediate(handler)
}
handler()process.nextTick()的运行结果:
nextTick 1
nextTick 2
......
nextTick 999
nextTick 1000
finish reading time: 170setImmediate(),运行结果:
setImmediate 1
setImmediate 2
finish reading time: 80
......
setImmediate 999
setImmediate 1000这是因为嵌套调用的 setImmediate() 回调,被排到了下一次Event Loop才执行,所以不会出现阻塞。
process.nextTick()是node早期版本无setImmediate时的产物,node作者推荐我们尽量使用setImmediate。
4.3. 为什么要使用 process.nextTick()?
以下是来自官方的回答:
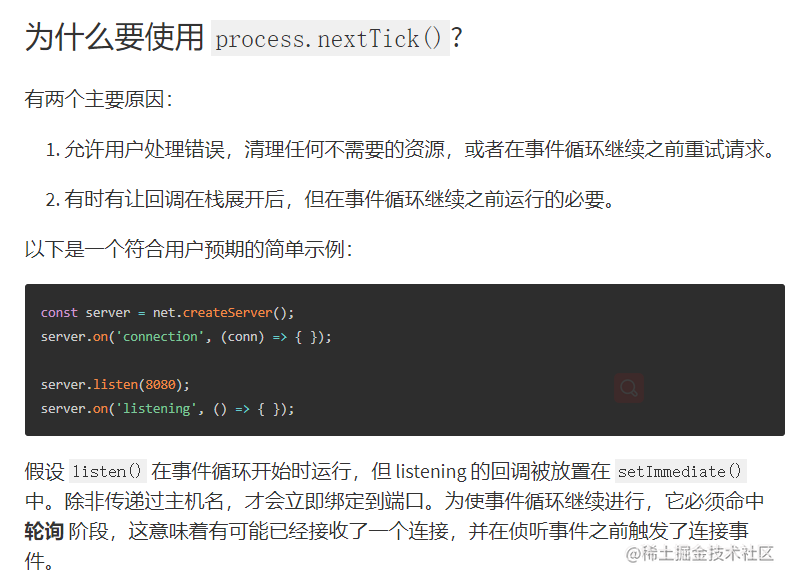
链接:https://nodejs.org/zh-cn/docs/guides/event-loop-timers-and-nexttick/#process-nexttick-2
我的理解是:
- process.nextTick()是一个强大的异步API,当我们需要控制代码顺序,保障同步和异步如期执行时,可以考虑使用它。
举个例子,比如我们在执行一个非常耗时的计算函数时,如果同步执行函数,因为单线程的缘故势必会阻塞后面代码的执行,所以我们可以将函数交给process.nextTick(),相当于放开计算函数的使用权,通过process.nextTick()方法将该函数的使用权交给计算机系统,就像在说:“我把使用权交给你,你有空了就帮我计算一下,计算完了通过callback告诉我”。
4.4. 小结
node.js 的事件循环分为6个阶段
浏览器和Node 环境下,microtask 任务队列的执行时机不同
- Node.js中,microtask 在事件循环的各个阶段之间执行
- 浏览器端,microtask 在事件循环的 macrotask 执行完之后执行
递归的调用process.nextTick()会导致I/O starving,官方推荐使用setImmediate()
五、参考
什么是 Event Loop?(前置知识,帮助我们了解Event Loop)
JavaScript 运行机制详解:再谈Event Loop(前置知识,通过JavaScript的运行机制帮助我们理解Event Loop)
[译]官方图解:Chrome 快是有原因的,现代浏览器的多进程架构!
Node.js Event Loop 的理解 Timers,process.nextTick() (评论区异常精彩,有源码解析,一定要看,一定要看,一定要看,重要的事说三遍!)
[翻译]Node事件循环系列——1、 事件循环总览(全系列文章都非常值得学习)
nodejs 是代表 Reactor 还是 Proactor 设计模式?
Node.js 事件循环,定时器和 process.nextTick()
本文由博客一文多发平台 OpenWrite 发布!















 2522
2522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









