(1) 向量对齐:
由于在实际应用中,表征文本特征的两个向量的长度是不同的,因此必然需要对上述向量进行处理。
a) 对文本进行预处理:去停用词(分词,介词,代词等)以及非文本符号
b) 归并向量,并根据原向量是否在新向量(归并后的向量)存在,若存在则以该词汇的词频来表征,若不存在则该节点置为0
c) 示例如下:
Text1_1: It is a beautiful butterfly
Text1_2: beautiful butterfly
Text2_1: She is a beautiful girl
Text2_2: beautiful girl
Vector: beautiful butterfly girl
Vector1 = (1, 1, 0)
Vector2 = (1, 0, 1)
(2) 样例:
Test1_1、Test2_1为来自不同类型文章中的随机段落节选;Test1_2、Test2_2为去停用词和非文字符号后的文本
Test1_1:In spite of the title, this article will really be on how not to grow old, which, at my time of life, is a much more important subject. My first advice would be to choose your ancestors carefully. Although both my parents died young, I have done well in this respect as regards my other ancestors. My maternal grandfather, it is true, was cut off in the flower of his youth at the age of sixty-seven, but my other three grandparents all lived to be over eighty. Of remoter ancestors I can only discover one who did not live to a great age, and he died of a disease which is now rare, namely, having his head cut off.
Test1_2:spite title article grow old which time life subject advice choose ancestors carefully parents died young respect ancestors maternal grandfather true cut flower youth age sixty-seven grandparents lived eighty remoter ancestors discover live age died disease rare namely head cut off
Test2_1:A good book may be among the best of friends. It is the same today that it always was, and it will never change. It is the most patient and cheerful of companions. It does not turn its back upon us in times of adversity or distress. It always receives us with the same kindness; amusing and instructing us in youth, and comforting and consoling us in age.
Test2_2:book friends was change patient cheerful companions times adversity distress receives kindness amusing instructing youth comforting consoling age








 本文介绍了如何使用余弦相似度来衡量文本之间的相似性,重点在于实际的代码实现,通过计算两个文本向量的夹角余弦值来评估它们的相似程度。
本文介绍了如何使用余弦相似度来衡量文本之间的相似性,重点在于实际的代码实现,通过计算两个文本向量的夹角余弦值来评估它们的相似程度。

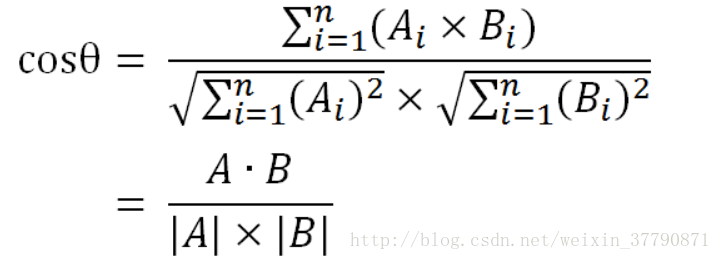
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4223
4223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









