







一、内容进行梳理:

二、算法补充(KNN比较简单也没有什么理论推导,就只写个算法)


三、关于Kd树(主要是帮助KNN快速搜索)


个人理解:先根据叶子节点找出当前最近点,然后以搜索点与当前最近的距离为半径圈出节点,凡是这些节点的兄弟节点都是比较范围。
四、Kd树近邻搜索代码
import numpy as np
###########################################################################################
#其实树的存储形式是node形式,节点是树的基本形式包含节点域,与左节点与右节点。
#树就只需要保存根节点即可(因为我们在检索是并不是真的需要数的结构)
###########################################################################################
class Node:
def __init__(self, data, lchild = None, rchild = None):
self.data = data
self.lchild = lchild
self.rchild = rchild
class KdTree:
def __init__(self):
self.kdTree = None
def create(self, dataSet, depth): #创建kd树,返回根结点
if (len(dataSet) > 0):
m, n = np.shape(dataSet) #求出样本行,列
midIndex = int(m / 2) #中间数的索引位置
axis = depth % n #判断以哪个轴划分数据
sortedDataSet = self.sort(dataSet, axis) #进行排序
node = Node(sortedDataSet[midIndex]) #将节点数据域设置为中位数,具体参考下书本
# print sortedDataSet[midIndex]
leftDataSet = sortedDataSet[: midIndex] #将中位数的左边创建2改副本
rightDataSet = sortedDataSet[midIndex+1 :]
print(leftDataSet)
print(rightDataSet)
node.lchild = self.create(leftDataSet, depth+1) #将中位数左边样本传入来递归创建树
node.rchild = self.create(rightDataSet, depth+1)
return node
else:
return None
def sort(self, dataSet, axis): #采用冒泡排序,利用aixs作为轴进行划分
sortDataSet = dataSet[:] #由于不能破坏原样本,此处建立一个副本
m, n = np.shape(sortDataSet)
for i in range(m):
for j in range(0, m - i - 1):
if (sortDataSet[j][axis] > sortDataSet[j+1][axis]):
temp = sortDataSet[j]
sortDataSet[j] = sortDataSet[j+1]
sortDataSet[j+1] = temp
print(sortDataSet)
return sortDataSet
def preOrder(self, node):
if node != None:
print("tttt->%s" % node.data)
self.preOrder(node.lchild)
self.preOrder(node.rchild)
# def search(self, tree, x):
# node = tree
# depth = 0
# while (node != None):
# print node.data
# n = len(x) #特征数
# axis = depth % n
# if x[axis] < node.data[axis]:
# node = node.lchild
# else:
# node = node.rchild
# depth += 1
def search(self, tree, x):
self.nearestPoint = None #保存最近的点
self.nearestValue = 0 #保存最近的值
def travel(node, depth = 0): #递归搜索
if node != None: #递归终止条件
n = len(x) #特征数
axis = depth % n #计算轴
if x[axis] < node.data[axis]: #如果数据小于结点,则往左结点找
travel(node.lchild, depth+1)
else:
travel(node.rchild, depth+1)
#以下是递归完毕后,往父结点方向回朔
distNodeAndX = self.dist(x, node.data) #目标和节点的距离判断
if (self.nearestPoint == None): #确定当前点,更新最近的点和最近的值
self.nearestPoint = node.data
self.nearestValue = distNodeAndX
elif (self.nearestValue > distNodeAndX):
self.nearestPoint = node.data
self.nearestValue = distNodeAndX
print(node.data, depth, self.nearestValue, node.data[axis], x[axis])
if (abs(x[axis] - node.data[axis]) <= self.nearestValue): #确定是否需要去子节点的区域去找(圆的判断)
if x[axis] < node.data[axis]:
travel(node.rchild, depth+1)
else:
travel(node.lchild, depth + 1)
travel(tree)
return self.nearestPoint
def dist(self, x1, x2): #欧式距离的计算
return ((np.array(x1) - np.array(x2)) ** 2).sum() ** 0.5
dataSet = [[2, 3],
[5, 4],
[9, 6],
[4, 7],
[8, 1],
[7, 2]]
x = [5, 3]
kdtree = KdTree()
tree = kdtree.create(dataSet, 0)
kdtree.preOrder(tree)
print(kdtree.search(tree, x))五、作业
1. 图像分类数据和label分别是什么 图像分类存在的问题与挑战
数据:图像的像素矩阵,label是图像的类别(为向量形式)
图像分类问题:同一目标如果会随着角度、光照、变形、遮挡、类内差异等因素的变化,而使像素矩阵出现剧烈变化
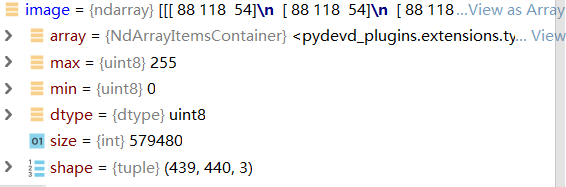
2. 使用python加载一张彩色图片,观察像素值——图片大小(439,440,3)

3. L1范数,L2范数数学表达式 这两种度量分别适用于什么情况
L1:应用于样本特征中有一些比较重要的值(或有意义的值)依赖于数据的坐标系统
![]()
L2:应用于所有的特征我们都不知其含义与重要程度时
![]()
4. 描述近邻算法KNN NN算法复的杂度 为什么很少使用在图像中以及它存在的问题
NN: O(train)=1, O(test)=n
KNN: O(train)=1, O(test)=n*k (使用Kd-tree时O(test)=lnn)
很少用到图像是因为算法的距离度量无法良好的刻画图像的语义差异,图像的维度也很高。
缺点:测试时速度慢,距离函数用在比较像素上不合适;维数灾难;高度数据相关;预测的结果不具有可解释性。参考链接
5. 了解CIFAR-10数据集
CIFAR-10和CIFAR-100是带有标签的数据集,都出自于规模更大的一个数据集,他有八千万张小图片。这个是一个大项目,你可以点击那个big map提交自己的标签,可以帮助他们训练让计算机识别物体的模型)
加载方式:参考链接
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict6. 超参数怎么选择合适(即数据集如何划分)
将数据集分成训练集、验证集、测试集。具体划分方法:参考链接;数据划分原理:参考链接
问:在完成深度学习任务时,每次训练集、验证集和测试集的next_batch都是从同一个大数据集抽(就是测试集和验证集可能会混入上一个训练集next_batch中数据),合理吗?
答:不合理,验证集与训练集可以混,但测试集不行。只会使模型的acc被放大。
问:请问,在网络训练抽取next_batch时,将训练集与验证集混合后再抽取,会提高网络的性能吗?
答:不会提高性能,但是会改变训练效果.(答案有点诡异哈哈,我以后再也不混抽数据集了,只划不混了)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









