







前言:本文为进化神经网络的总结并不是文献的阅读笔记,因此本文的书写方式与之前的博客并不相同。本文对深度进化神经网络的基本概念进行记录,分为遗传算法、遗传策略和网路进化。
一、遗传算法
1、基本思路
遗传算法(Genetic Algorithm, GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。补充:为什么需要遗传算法?因为它可寻找出全局最优,这点是梯度算法这些爬山算法所达不到的。
2、专业术语
-
基因型(genotype):性状染色体的内部表现;(编码后的属性值)
-
表现型(phenotype):染色体决定的性状的外部表现,或者说,根据基因型形成的个体的外部表现;(原始属性值)
-
进化(evolution):种群逐渐适应生存环境,品质不断得到改良。生物的进化是以种群的形式进行的。
-
适应度(fitness):度量某个物种对于生存环境的适应程度。
-
选择(selection):以一定的概率从种群中选择若干个个体。一般,选择过程是一种基于适应度的优胜劣汰的过程。
-
复制(reproduction):细胞分裂时,遗传物质DNA通过复制而转移到新产生的细胞中,新细胞就继承了旧细胞的基因。
-
交叉(crossover):两个染色体的某一相同位置处DNA被切断,前后两串分别交叉组合形成两个新的染色体。也称基因重组或杂交;
-
变异(mutation):复制时可能(很小的概率)产生某些复制差错,变异产生新的染色体,表现出新的性状。
-
编码(coding):DNA中遗传信息在一个长链上按一定的模式排列。遗传编码可看作从表现型到基因型的映射。
-
解码(decoding):基因型到表现型的映射。
-
个体(individual):指染色体带有特征的实体;
-
种群(population):个体的集合,该集合内个体数称为种群
3、基本步骤
遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个体(individual)组成。每个个体实际上是染色体(chromosome)带有特征的实体。
染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的。因此,在一开始需要实现从表现型到基因型的映射即编码工作。由于仿照基因编码的工作很复杂,我们往往进行简化,如二进制编码。
初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度(fitness)大小选择(selection)个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉(crossover)和变异(mutation),产生出代表新的解集的种群。
这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码(decoding),可以作为问题近似最优解。

4、算法重点
1)编码:
编码是应用遗传算法时要解决的首要问题,也是设计遗传算法时的一个关键步骤。编码方法影响到交叉算子、变异算子等遗传算子的运算方法,大很大程度上决定了遗传进化的效率。迄今为止人们已经提出了许多种不同的编码方法。总的来说,这些编码方法可以分为三大类:二进制编码法、浮点编码法、符号编码法。
(1)二进制编码法:
一个位能表示出2种状态的信息量,因此足够长的二进制染色体便能表示所有的特征。这便是二进制编码。如:1110001010111
优点:编码、解码操作简单易行;交叉、变异等遗传便于实现;符合最小字符集编码原则;可利用模式定理对算法进行理论分析。
缺点是:对于一些连续函数的优化问题,由于其随机性使得其局部搜索能力较差,如对于一些高精度的问题,当解迫近于最优解后,由于其变异后表现型变化很大,不连续,所以会远离最优解,达不到稳定。
(2)浮点编码法:
浮点法是指个体的每个基因值用某一范围内的一个浮点数来表示。在浮点数编码方法中,必须保证基因值在给定的区间限制范围,遗传算法中所使用的交叉、变异等遗传算子也必须保证其运算结果所产生的新个体的基因值也在这个区间限制范围内。如:1.2-5.3-7.2-1.4
(3)符号编码法
符号编码法是指个体染色体编码串中的基因值取自一个无数值含义、而只有代码含义的符号集如{A,B,C…}。符号编码的主要优点是:符合有意义积术块编码原则;便于在遗传算法中利用所求解问题的专门知识;便于遗传算法与相关近似算法之间的混合使用。
(4)举例:求一元函数y=ax+b最大值(max)的问题中对x进行编码。其中,x在区间[-1,2]中。
二进制:一定长度的二进制编码序列,只能表示一定精度的浮点数。在这里假如我们要求解精确到六位小数,由于区间长度为2 - (-1) = 3 ,为了保证精度要求,至少把区间[-1,2]分为3 × 10^6等份。又因为下式,所以编码的二进制串至少需要22位。
2^21 = 2097152 < 3*10^6 < 2^22 = 4194304
浮点编码法:直接将x作为浮点数即可,就一位数。
(5)补充:把一个二进制串(b0,b1,....bn)转化为区间里面对应的实数值可以通过下面两个步骤:

2) 评价个体的适应度--适应度函数(fitness function)
(1)概念:
适应度函数也称评价函数,是根据目标函数确定的用于区分群体中个体好坏的标准。适应度函数总是非负的,而目标函数可能有正有负,故需要在目标函数与适应度函数之间进行变换。
(2)评价个体适应度的一般过程为:
对个体编码串进行解码处理后,可得到个体的表现型;
由个体的表现型可计算出对应个体的目标函数值;
根据最优化问题的类型,由目标函数值按一定的转换规则求出个体的适应度。
(3)适应度函数与目标函数转化:
最优化问题可分为两类:一类为目标函数f(x)的全局最大,其适应度F(x)=f(x),maxf(x)=maxF(x);;一类为目标函数f(x)的全局最小,其适应度函数F(x)=-f(x),minf(x)=maxF(x)=max(-f(x))。由于适应度取值为非负值,所以常见做法为以下两种:


上述方法虽然可以完成适应度与目标函数的转化,但上述方法经常会导致算法收敛不稳定,有时收敛极慢(适应度函数与算法收敛速度息息相关)。因此,为加快收敛经常对适应度函数进行尺度变化,如: 线性尺度变换、乘幂尺度变换、指数尺度变换。参考链接
(4)适应度函数设计要求:
单值、连续、非负、最大化、可以不可导、在适应度曲线中的重要位置,尤其是最优解处不宜太过陡峭或平缓;
计算量小;
通用性好。
(5)如何根据适应度终止算法
连续几代种群中的平均适应度差异小于某一极小的阈值
群体中所有个体的适应度方差小于某一极小的阈值
3) 选择函数(selection)
遗传算法中的选择操作就是用来确定如何从父代群体中按某种方法选取那些个体,以便遗传到下一代群体。选择操作用来确定重组或交叉个体,以及被选个体将产生多少个子代个体。这些选择出现在个体身上是存在概率的,建立这种概率关系的方法如下:
(1)轮盘赌选择(Roulette Wheel Selection):
是一种回放式随机采样方法。每个个体进入下一代的概率等于它的适应度值与整个种群中个体适应度值和的比例。选择误差较大。假如有5条染色体,他们的适应度分别为5、8、3、7、2。那么总的适应度为:F = 5 + 8 + 3 + 7 + 2 = 25。那么各个个体的被选中的概率为:α1 = ( 5 / 25 ) * 100% = 20%;α2 = ( 8 / 25 ) * 100% = 32%;α3 = ( 3 / 25 ) * 100% = 12%;α4 = ( 7 / 25 ) * 100% = 28%;α5 = ( 2 / 25 ) * 100% = 8%
(2)随机竞争选择(Stochastic Tournament):
每次按轮盘赌选择一对个体,然后让这两个个体进行竞争,适应度高的被选中,如此反复,直到选满为止。
(3)最佳保留选择:
首先按轮盘赌选择方法执行遗传算法的选择操作,然后将当前群体中适应度最高的个体结构完整地复制到下一代群体中。
(4)无回放随机选择(期望值选择Excepted Value Selection):根据每个个体在下一代群体中的生存期望来进行随机选择运算。
- 计算群体中每个个体在下一代群体中的生存期望数目N。
- 若某一个体被选中参与交叉运算,则它在下一代中的生存期望数目减去0.5,若某一个体未被选中参与交叉运算,则它在下一代中的生存期望数目减去1.0。
- 随着选择过程的进行,若某一个体的生存期望数目小于0时,则该个体就不再有机会被选中。
num_expectation(i)=n*fitness_value(i)/sum(fitness_value);%计算群体中每个个体在下一代群体中的生存期望数目。(5)确定式选择:按照一种确定的方式来进行选择操作。具体操作过程如下:
- 计算群体中各个个体在下一代群体中的期望生存数目N。
- 用N的整数部分确定各个对应个体在下一代群体中的生存数目。关于下一代种群个体总数的求解
- 用N的小数部分对个体进行降序排列,顺序取前M个个体加入到下一代群体中。至此可完全确定出下一代群体中M个个体。
(6)无回放余数随机选择:
可确保适应度比平均适应度大的一些个体能够被遗传到下一代群体中,因而选择误差比较小。
(7)均匀排序:
对群体中的所有个体按期适应度大小进行排序,基于这个排序来分配各个个体被选中的概率。
(8)最佳保存策略:
当前群体中适应度最高的个体不参与交叉运算和变异运算,而是用它来代替掉本代群体中经过交叉、变异等操作后所产生的适应度最低的个体。
(9)随机联赛选择:
每次选取几个个体中适应度最高的一个个体遗传到下一代群体中。
(10)排挤选择:
新生成的子代将代替或排挤相似的旧父代个体,提高群体的多样性。
4)染色体交叉(crossover)
遗传算法的交叉操作,是指对两个相互配对的染色体按某种方式相互交换其部分基因,从而形成两个新的个体。适用于二进制编码个体或浮点数编码个体的交叉算子如下:


(1)单点交叉(One-point Crossover):
指在个体编码串中只随机设置一个交叉点,然后再该点相互交换两个配对个体的部分染色体。
(2)两点交叉与多点交叉:
在个体编码串中随机设置了两个交叉点,然后再进行部分基因交换。
(3)多点交叉(Multi-point Crossover):
在个体编码串中随机设置了多个交叉点,然后再进行部分基因交换。
(4)均匀交叉(也称一致交叉,Uniform Crossover):
两个配对个体的每个基因座上的基因都以相同的交叉概率进行交换,从而形成两个新个体。
(5)算术交叉(Arithmetic Crossover):
由两个个体的线性组合而产生出两个新的个体。该操作对象一般是由浮点数编码表示的个体。
5)基因变异
遗传算法中的变异运算,是指将个体染色体编码串中的某些基因座上的基因值用该基因座上的其它等位基因来替换,从而形成新的个体。例如下面这串二进制编码:
101101001011001
经过基因突变后,可能变成以下这串新的编码:
001101011011001
以下变异算子适用于二进制编码和浮点数编码的个体:
(1)基本位变异(Simple Mutation):
对个体编码串中以变异概率、随机指定的某一位或某几位基因座上的值做变异运算。
(2)均匀变异(Uniform Mutation):
分别用符合某一范围内均匀分布的随机数,以某一较小的概率来替换个体编码串中各个基因座上的原有基因值。(特别适用于在算法的初级运行阶段)
(3)边界变异(Boundary Mutation):
随机的取基因座上的两个对应边界基因值之一去替代原有基因值。特别适用于最优点位于或接近于可行解的边界时的一类问题。
(4)非均匀变异:
对原有的基因值做一随机扰动,以扰动后的结果作为变异后的新基因值。对每个基因座都以相同的概率进行变异运算之后,相当于整个解向量在解空间中作了一次轻微的变动。
(5)高斯近似变异:
进行变异操作时用均值为P,方差为P**2的正态分布的一个随机数来替换原有的基因值。
二、遗传策略
1、基本思路
进化策略是一种模仿生物进化的一种求解参数优化问题的方法;不过与遗传算法不一样的是,它采用实数值作为基因;它总遵循零均值、某一方差的高斯分布的变化产生新的个体,然后保留好的个体。
2、基本步骤(注意顺序)
- 问题:寻找实值n维矢量x,使得函数F(x)取极值。极小化过程。(确定问题)
- 初始化:从各维的可行范围内随机选取亲本xi,i=1,…,p的初始值。初始试验的分布一般是均匀分布。(初始化种群)
- 进化:对两个个体进行交叉重组;通过对于x的每个分量增加零均值和预先选定的标准差的高斯随机变量,从每个亲本xi产生子代。(交叉、变异)
- 选择:通过将误差F(xi)和F(x'i),i=1,…,p 进行排序,选择并决定哪些矢量保留。具有最小误差的p个矢量变成下一代的新亲本。(把父亲和儿子放在一起用适应度排序,保留好的)。
- 重复进化和选择直到达到收敛
3、算法重点
1)交叉:
和遗传算法一样,交叉就是交换两个个体的基因。两条链都要交叉,即A1与B1交叉形成表示子代解决方案的C1链,A2与B2交叉形成表示C1链对应位置实数值变异强度的C2链(父:A,母:B,子:C),主要有三种方式:
# 杂交,随机选择父母
p1, p2 = np.random.choice(self.pop_size, size=2, replace=False)
# 选择杂交点
cp = np.random.randint(0, 2, self.gene_size, dtype=np.bool)
# 当前孩子基因的杂交结果
kv[cp] = self.pop['DNA'][p1, cp]
kv[~cp] = self.pop['DNA'][p2, ~cp]
# 当前孩子变异强度的杂交结果
ks[cp] = self.pop['mut_strength'][p1, cp]
ks[~cp] = self.pop['mut_strength'][p2, ~cp]

(1)离散重组:
先随机选择两个父代个体,然后将其分量进行随机交换,构成子代新个体的各个分量,从而得出如下新个体。
(2)中值重组:
这种重组方式也是先随机选择两个父代个体,然后将父代个体各分量的平均值作为子代新个体的分量,构成的新个体为。
(3)混杂重组:
这种重组方式的特点在于父代个体的选择上。混杂重组时先随机选择一个固定的父代个体,然后针对子代个体每个分量再从父代群体中随机选择第二个父代个体。也就是说,第二个父代个体是经常变化的。至于父代两个个体的组合方式,既可以采用离散方式,也可以来用中值方式,甚至可以把中值重组中的1/2改为[0,1]之间的任一权值。
2)变异:
每个分量上面加上零均值、某一方差的高斯分布的变化产生新的个体。这个某一方差就是变异程度。这与遗传算法有极大的不同,此时链上的每个基因都服从不同的高斯分布。
(1)C1链上值的变异方法:
将C1链上的值看作正态分布的均值μ; 将C2链上变异强度值看作标准差σ; 用正态分布产生一个与C1链上选定位置相近的数,进行替换
# kv代表DNA,ks代表变异强度
kv += ks * np.random.randn()(2)C2链上值的变异方法:
因为随着不断遗传迭代,种群中个体1号链的值不断逼近最优解,变异的强度也应当不断减小。所以也需要根据需求自定义2号链的变异方法。由于算法最终要收敛,所以变异强度需要不断变小,但不可以低于0,变小方式实现如下:
# 变异强度要大于0,并且不断缩小
ks[:] = np.maximum(ks + (np.random.rand()-0.5), 0.) 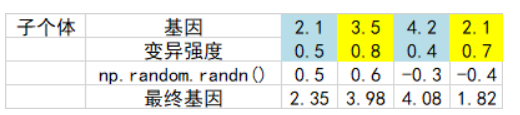
3)选择:
本质是从亲代种群中选择出父代产生子代,并将生成的孩子加入父代中,形成一个包含两代DNA的种群U; 对U种群中每个DNA序列的1号链(表示解决方案)进行fitness计算(打分),并根据分值从大到小排列(用U'表示排列后的混合种群); 截取U'中的分值高的前n位(n表示一代种群中的个体数目)形成新种群,具体实现如下:
合并父种群和子种群:
# 进行vertical垂直叠加
for key in ['DNA', 'mut_strength']:
self.pop[key] = np.vstack((self.pop[key], self.kids[key]))
计算整个种群的适应度:
# 计算fitness
self.pred = F(self.pop['DNA'])
fitness = self.get_fitness()
获得适应度从大到小的索引,并选择适应度最大的POP_SIZE个个体:
# 读出按照降序排列fitness的索引
max_index = np.argsort(-fitness)
# 选择适应度最大的POP_SIZE个个体
good_idx = max_index[:POP_SIZE]
for key in ['DNA', 'mut_strength']:
self.pop[key] = self.pop[key][good_idx]

(1)分类:
(μ+λ)选择是从μ个父代个体及λ个子代新个体中确定性地择优选出μ个个体组成下一代新群体;(μ, λ)选择是从λ个子代新个体中确定性地择优桃选μ个个体(要求λ>μ)组成下一代群体,每个个体只存活一代,随即被新个体顶替。粗略地看,似乎(μ+λ)选择最好,它可以保证最优个体存活,使群体的进化过程呈单调上升趋势。但是(μ+λ)选择保留旧个体,有时是局部最优解,这也带来了很多问题。 (实践也证明,(μ, λ)-ES优于(μ+λ)-ES,前者已成为当前进化策略的主流。)
(2)(μ+λ)-ES——(1+1)-ES这种进化策略只有一个父亲,每次也只产生一个新的个体,然后从两个中保留好的。
个体:个体由各个实数分量表示。
进化:这类在进化过程中只有变异:就是在每个分量上面加上零均值、某一方差的高斯分布的变化产生新的个体。
变异程度:采用1/5判断法是否改变变异程度,即还没到收敛的时候(左图), 我们增大变异程度, 如果已经快到收敛了(右图), 我们就减小 变异程度. 那如何判断是否快到收敛没呢?就是如果有1/5的变异比原始的 parent 好的话, 就是快收敛了(像右图). 在左图中, 有一半比原始 parent 好, 一半比较差, 所以还没到收敛.。

具体变异程度变化公式:

#(1+1)-ES算法
parent = 5*np.random.rand(DNA_SIZE)
#进化
def make_kid(parent): # 生成孩子
kid = parent + MUT_STRENGTH*np.random.randn(DNA_SIZE)
kid = np.clip(kid,*DNA_BOUND) # 边界化,不能超过边界
return kid
#选择
def kill_bad(parent, kid): # 抛弃掉不好的,同时根据结果修改变异强度
global MUT_STRENGTH
fp = get_fitness(F(parent))[0]
fk = get_fitness(F(kid))[0]
p_target = 1/5
if fp < fk:
parent = kid # 抛弃不好的
ps = 1
else:
ps = 0
MUT_STRENGTH *= np.exp(1/np.sqrt(DNA_SIZE+1)*(ps-p_target)/(1-p_target)) # 修改变异强度
return parent
(3)(μ, λ)-ES:这种进化策略的种群中有μ个体,每次新产生λ个体,然后从λ个新的个体中选着μ个作为新的种群。
个体:个体有两部分组成,一部分是基因:就是各个分量值,另一部分:每个分量对应的兵役程度。
进化:包括交叉和变异(具体和上面一样)
变异程度: 变异程度也能变异。将变异强度变异以后, 他就能在快收敛的时候很自觉的逐渐减小变异强度, 方便收敛。
选择:从λ个新的个体中选着μ个作为新的种群。
#(μ+ λ)-ES算法
#创建个体
pop = dict(DNA = 5*np.random.rand(1,DNA_SIZE).repeat(POP_SIZE,axis=0),
mut_strength=np.random.rand(POP_SIZE,DNA_SIZE)) # 初始化DNA和变异强度
#进化
def make_kid(pop, n_kid): # 产生孩子的过程
kids = {'DNA':np.empty((n_kid,DNA_SIZE))}
kids['mut_strength'] = np.empty_like(kids['DNA'])
for kv,ks in zip(kids['DNA'],kids['mut_strength']):
p1,p2 = np.random.choice(np.arange(POP_SIZE),size=2,replace=True)
cp = np.random.randint(0,2,DNA_SIZE,dtype=np.bool)
# 交叉过程
kv[cp] = pop['DNA'][p1,cp]
kv[~cp] = pop['DNA'][p2,~cp]
ks[cp] = pop['mut_strength'][p1, cp]
ks[~cp] = pop['mut_strength'][p2, ~cp]
# 变异过程
ks[:] = np.maximum(ks + (np.random.rand(*ks.shape)-0.5),0.) # 变异程度也可以改变,保持大于0
kv += ks * np.random.rand(*kv.shape)
kv[:] = np.clip(kv,*DNA_BOUND)
return kids
#选择
def kill_bad(pop, kids): # 抛弃不好的
for key in ['DNA','mut_strength']: # 合并父亲和儿子
pop[key] = np.vstack((pop[key],kids[key]))
# 利用适应度选择出好的,排序,选出前面的POP_SIZE
fitness = get_fitness(F(pop['DNA']))
idx = np.arange(pop['DNA'].shape[0])
good_idx = idx[fitness.argsort()][-POP_SIZE:]
for key in ['DNA','mut_strength']:
pop[key] = pop[key][good_idx]
return pop三、进化策略与遗传算法对比
1、相同点
进化策略的思路与遗传算法相似,二者都是利用进化理论进行优化,即利用遗传信息一代代传承变异,通过适者生存的理论,保存适应度高的个体,得到最优解。
2、不同点(本质是遗传算法是交叉变异选择都是对基因进行,进化策略则是针对个体)
- 遗传算法采用二进制编码杂交;而进化策略使用实数。(不一定,不是主要区别)
- 遗传算法采用变异概率实现变异;而进化策略则使用变异强度实现变异。(实现变异的方式不同)
- 遗传算法仅需要一条编码链,用于存储个体的基因;进化策略在编码时,不仅要有实数编码链,还要有变异强度编码链。(本质与第二条相同)
- 遗传算法在交叉繁殖的时候,仅实现基因的交叉;进化策略则要实现两条链的交叉,父母辈的实数链交叉形成子辈的实数链,变异强度编码链交叉形成子辈的变异强度编码链。(是个体在交叉,所以基因都在交叉,所以基因都是交叉点)
- 遗传算法在变异时,随机选择基因段变异;进化策略则是将实数链上的实数值看作正态分布的均值μ,将变异强度编码链上变异强度值看作正态分布的标准差σ。(进化策略是对个体进行变异,所以基因都变异,没有基因被完好保存)
- 遗传算法在自然选择时,通过轮盘赌实现自然选择;进化策略则将子种群加入到父种群中,按照适应度排序,直接选出适应度最大的pop_size个个体。(这个区别不是很大,因为大多数情况下,适应度直接反应在个体上)
四、网络进化
1、基本思路
NEAT 指「Networks through Augmented Topologies」(通过增强拓扑的进化神经网络),描述了自学习机器的算法概念,这些算法概念受启发于进化过程中的遗传修饰(genetic modification)。
进化神经网络是一种结合进化算法和神经网络这两大领域,诞生的一种新型算法。在进化神经网络的算法中,神经网络的各种参数将会通过编码操作,转化为进化算法中的染色体,并通过进化算法进行网络搭建和参数优化。
目前,进化神经网络有两种主要形式,一种是固定拓扑进化方法和权重拓扑进化法。固定拓扑进化法是对进化算法应用到神经网络的初步尝试,是面对指定问题时,首先人工设计神经网络的拓扑结构,然后在训练时使用进化算法替代反向传播算法对权值进行优化,最后得到网络的最优参数。
2、专业术语:
connection genes:每个基因表示两个节点之间的连接
node genes:包含输入节点,隐藏节点,输出节点
connection gene:包含入节点,出节点,节点的参数,是否启用,创新号。
mutation:mutate add connection+mutate add node
mutate add connection :在两个未连接的节点之间添加连接
mutate add node:在一个连接之间添加一个节点,新节点到旧out节点之间的参数继承旧连接,旧in节点到新节点之间的参数设为1
3、基本流程

4、算法重点
1)基因编码
NEAT算法在编码时,会将一个完整的神经网络编码成两条基因:节点基因和权重基因。节点基因对应网络拓扑结构,权重基因对应连接权重。注意:diable表示的是不使用(不可能相连)的连接,不是未连接的连接,3→5就不是disable,只是不显示(尚未连接)而已,它可以在变异的时候出现连接。

2) 变异
变异发生在新生成基因组的过程中,可能会出现改变网络的权重,增加突出连接或者神经元,也有可能禁用连接或者启用连接。如果一个相同的结构经过多次变异后会产生相同的结构,但是会有多个不同的innovation number,为了防止这种情况产生,通过维持一个list of the innovations occurred in the current generation,记录当前种群发生变异(不断更新)。变异具有两种形式:

3)交叉
通过对应innovation number,然后随机从父代中选择相对应的基因,组成新的基因组。下面的例子中是节点的突变,你可以看到从 2 到 4 的连接被取消了,并且引入了一个新的节点 6,然后生成了从 3 到 6、从 6 到 4 的新连接。

4)基于物种划分的选择
(1)原因:
这样做的目的是将种群划分为不同的物种,相似的拓扑结构存在于同一物种中。通过把类似的结构划分为一个物种,使相同的结构在同一个物种之间相互进化。
优点:种群的分化使得生物体主要在它们自己的生态位内竞争,而不是与整个种群竞争。这样,拓扑结构的创新就可以在一个新的物种中得到保护,从而有时间优化结构并有利于在种群中的竞争。
(2)距离公式:
一对基因组之间过剩和不相交基因的数量是衡量它们的兼容性距离的自然指标。两个基因组越不相交,它们共享的进化历史就越少,因此它们的兼容性就越差。
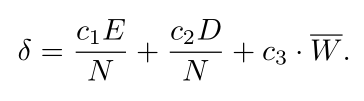
E:两个网络之间节点的数量差;D:两个网络之间innovation number不对应的数量;W:两个网络之间权重参数的平均值的差;c1,c2,c3是调节权重的参数。
(3)划分方法:
个体g与每个物种中的代表个体(与物种中所有个体距离总数最小的个体)进行比较,距离小于compatibility threshold,则加入物种,若都不相符,则产生新的物种。
(4)选择(淘汰):对各个物种中的个体按适应度进行排序,按比率分别对各个物种中的个体进行淘汰
5)适应度公式
物种之间的交流:explicit fitness sharing,为了防止某一物种拓展太大,即使物种内的个体都比较优良。需要调整fitness,因此每个种群中的个体适应度都受其物种中的个体数目限制。

其中,i为当前个体,j为同一物种中的其他个体,共享函数sh:当距离δ(i, j)是高于阈值δt时,sh(δ(i, j))=0;否则,sh(δ(i, j))=1。由此可见NEAT算法是严格遵从自然选择的。其中fi多由损失函数或目标函数构成。
5、过程模拟
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









