







一、知识梳理

二、优策策略—一阶函数(减少训练误差)
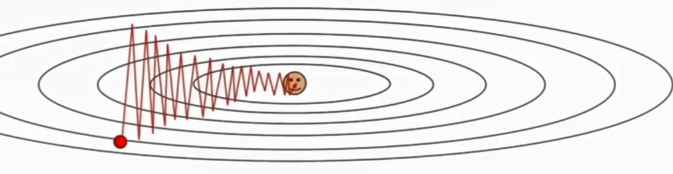
1、为什么在权重对损失函数敏感程度不同时,SGD会走Z字型?
如下图,损失函数对竖直方向敏感,因此在优化权重时在竖直方向走的多,在水平方向走的少。(为何在等高线上来回震荡呢?还是因为竖直方向敏感,因此竖直方向上走的距离要多于水平方向,因此不得不来回震荡)
2、鞍点与极值点的区别?
鞍点和局部极小值相同的是,在该点处的梯度都等于零,不同在于在鞍点附近Hessian矩阵是不定的(行列式小于0),而在局部极值附近的Hessian矩阵是正定的。在鞍点处,横着看的话,鞍点就是个极小值点,但是竖着看的话,鞍点就是极大值点(线性代数和最优化算法过关的同学应该能反应过来,鞍点处的Hessian矩阵的特征值有正有负。(二阶导数用于表示曲线的曲率)
3、优化算法
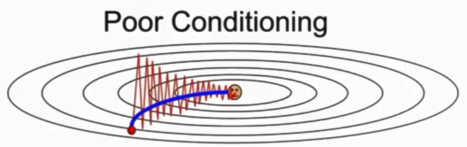
1)SGD+Momentum(累加之前的梯度,相当于给了一个惯性。因此,可以越过极值点与鞍点。)同时,因为累加梯度,使得优化是水平与竖直方向上的梯度相互抵消。最终,使其优化过程逐渐平滑,不走Z字。

优点:对方向一致的参数能够加速学习,对梯度改变方向的参数能够减少其更新,因此就是momentum能够在相关方向上加速学习,抑制振荡,从而加速收敛。
缺点:比较难学习一个较好的学习率。
2)Nesterov acceletared gradient(NAG):Momentum的改进。先在原速度方向上前进一步,计算此时的梯度后,回到原来的位置,结合这个梯度和原速度决定本次前进的方向。


缺点:上述两种方法对于极端极值点的效果可能一般,但事实是极端极值点意味着训练可能过拟合了,平滑极值点更具鲁棒性。
优点:解决SGD陷入局部最优,与鞍点。
3) AdaGrad:在训练时一直累积一个梯度平方项,用步长*梯度/梯度平方项来前进.它的效果是加速小梯度方向的学习速度,减小大梯度方向的学习速度.并且因为梯度单调递增,因此步长会越来越小,有利于接近极值点,但同时会带来鞍点的问题.式中的1e-7是为了除数不为0。

特点:1.这样在训练初期,分母较小,学习率较大,学习比较快,2.后期时,学习会逐渐减慢,3.而且它适合于处理稀疏梯度,具有损失最大偏导的参数相应地有一个快速下降的学习率,而具有小偏导的参数在学习率上有相对较小的下降。
缺点:1.从训练开始就积累梯度方差会导致有效学习率过早和过量的减小。2.只能解决凸问题,当应用于非凸函数训练神经网络时,学习可能会到达一个局部是凸碗的区域。3.需要一个全局的学习率。
4)RMSProp:是AdaGrad的改进.仍计算梯度平方项,但让它按一定衰减率指数下降,可以解决AdaGrad算法学习率下降过快的问题。

优点:1.改进了Adagrad在深度学习中过早结束的问题;2.适用于处理非平稳。
缺点:依然依赖一个全局学习率。
5) Adam:可以看做是Momentum和RMSProp的结合.其中第一动量是速度,第二动量是梯度平方项.如果将第二动量初始化为0,那么一开始的步长会很大,因此需要加入偏置项,并使用动量的无偏估计来代替动量。

优点:结合了动量和RMSProp,利用了梯度的一阶矩估计和二阶矩估计动态调节每个参数的学习率,并且加上了偏置修正。
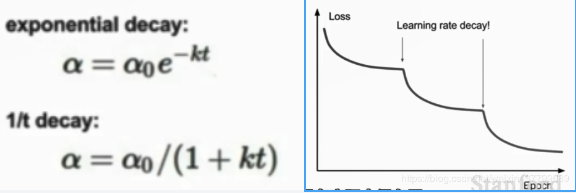
6) 学习率是优化函数的一个重要超参数,推荐先使用较大的学习率,然后随着训练迭代逐渐减小。但是在刚建立模型时最好使用一个固定的学习率,用于寻找出适合衰减参数的位置。
三、优策策略—二阶函数
1)思想:使用二阶泰勒公式逼近函数,使其具有对应点的梯度。(对二阶泰勒公式进行求导)
2)二阶优化:

二阶逼近的缺陷是计算量太大.可以用拟牛顿法代替牛顿法,但它们在深度学习中的使用并不多,因为并没有太多处理随机的方法。好处是二阶方法没有学习率。
3)L-BFGS:参考链接

Adam(beta1=0.9,beta2=0.999,学习率=1e-3或5e-4)是首选优化算法,但是如果问题并没有太多随机性,且能承受计算量的情况下(如风格迁移),可以尝试L-BFGS.
4)模型融合(减少训练与测试集之间的差距,主要是提高测试集准确率)
如果训练准确率已经很高,可以使用模型集成(Ensembles)来提高测试准确率.一种简单的集成方法是对不同独立模型的结果采用投票法或平均法.也可以使用一个模型在训练中多个不同时期的结果来进行集成.
四、补充
问题1:为什么进行归一化、中心化?
如下图,如果不进行归一化,我们仍可以使用一个分类器区分红蓝两点。但是,如果不进行归一化,我们的分类器只要有一点转动(扰动),就会完全破坏分类结果(会将原有分对的变成分错的,等于分类器失效)。因此,如果不对数据进行归一化,则得到的分类器会对参数的扰动非常敏感,导致损失函数变化大、优化难度增加。

问题2:粗细粒搜索超参数的具体步骤?
五、作业
1. 梯度下降存在哪些问题
1)优化时出现震荡,Z字型优化
2)陷入局部最优值
3)陷入鞍点
2. 课程中涉及到的优化策略的公式,描述优缺点。
见博客
3. 学习率衰减策略有哪些
不要直接使用学习率衰减,要先运行决定是否要使用,用在什么时候。Adam不需要学习率衰减,但不绝对。常用的学习率调整方法包括学习率衰减率、学习率预热、周期学习率以及一些自适应地调整学习率的方法。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









