







一、神经网络与损失函数的关系
1、损失函数的作用
我们希望:在训练时,如果预测值与实际值的误差越大,那么在反向传播的过程中,各种参数调整的幅度就要更大,从而使训练更快收敛。
1)Loss layer 是网络的终点,输入为预测值和真实标签。损失层则将这两个输入进行一系列运算,得到当前网络的损失函数(Loss Function),一般记做L(θ)其中θ是当前网络权值构成的向量空间。
2) Loss layer的本质是机器学习。机器学习的目的是在权值空间中找到让损失函数L(θ) 最小时的权值θ,可以采用一系列最优化方法。
3)损失函数是在前向传播计算中得到的,同时也是反向传播的起点。
2、损失函数在网络中的应用
损失函数主要是在反向传播时,使权重根据误差进行调整。损失函数的反向公式为:
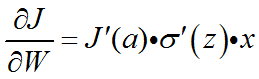
3、损失函数应有的性质(要求)
损失函数是表示神经网络性能的‘恶劣程度’的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。这个损失函数可以使用任意函数,但一般采用均方误差和交叉熵误差等。为了寻找损失函数尽可能小的地方,需要计算参数的导数(梯度),然后以这个导数为指引,逐步更新参数的值。应有的性质:
1)可导
2)可表达“误差越大,更新越大”
3)尽可能快速收敛
4)非负性
二、均方误差(MSE)
1、均方误差公式:
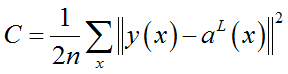
2、优点
1)可以刻画差异
2)是最简单的函数
3)求导容易
3、缺点
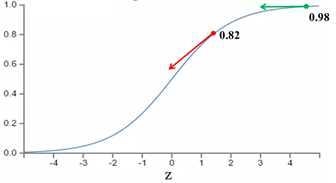
其实损失函数本身没有问题,但与Sigmoid组合时会出现问题。从以上公式可以看出,w和b的梯度跟激活函数的梯度成正比,激活函数的梯度越大,w和b的大小调整得越快,训练收敛得就越快。当y=0时、a-y越大,越小,与定义相反。
可能有人会说,那就选择一个梯度不变化或变化不明显的激活函数不就解决问题了吗?图样图森破,那样虽然简单粗暴地解决了这个问题,但可能会引起其他更多更麻烦的问题。
三、交叉熵损失函数
1、交叉熵损失函数公式
换个思路,我们不换激活函数,而是换掉二次代价函数,改用交叉熵代价函数。交叉熵代价函数刻画的是真实值与预测值之间信息的差异。
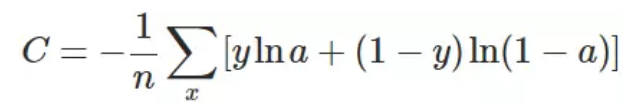
2、推导


3、优点
1)在求导过程中不在出现激活函数的导数,从而收敛加快。
2)以信息熵作为差异,更有益于分类。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









