







一、文献梳理
1、文献背景
为解决下述问题,需要高效的,少样本或零样本的网络压缩方法。
- CNN被广泛应用于CV任务,但需要大量计算资源支持,为满足移动计算需要进行神经网络的压缩
- 在现实应用,数据集往往很难获取
- 现有的零样本下的网络压缩,性能下降很多
2、研究成果
1)模型意义
- 提出了一个有效的无数据训练的办法;
- 有效的组合了GAN和教师-学生网络;
- 设计了适合于这篇文章中的GAN模型的总损失函数;
- 利用知识蒸馏将教师网络压缩为学生网络;
- 对多个数据集和多个经典网络进行了实验以证明有效性。
2)实验
- 实验一:(MNIST/HintonNet)+LeNet-5
- 实验二:模型简化实验
- 实验三:可视化结果
- 实验四:CIFAR+ResNet
- 实验五:CelebA+AlexNet
- 实验六:扩展实验
二、基础知识(传统压缩方法)
1、数据驱动压缩方法
(1)奇异值分解

(2)剪枝、权重分层、哈夫曼编码
(3)相似神经元聚类
神经网络接收外界输入模式时,将会分为不同的对应区域,各区域对输入模式有不同的响应特征,而这个过程是自动完成的。其特点与人脑的自组织特性类似。导师学习网络。它通过自动寻找样本中的内在规律和本质属性,自组织,自适应地改变网络参数与结构。
2、无数据压缩方法——元数据进行数据重构
目的是实现快速学习,而快速学习的关键一点是神经网络的梯度下降要准,要快,那么是不是可以让神经网络利用以往的任务学习如何预测梯度,这样面对新的任务,只要梯度预测得准,那么学习得就会更快了
不足:由于没有原始数据训练,无法进行准确的微调,因此现有算法压缩方法比较差,需要一种有效的无数据方法来学习性能相当高效的CNN。
三、文献重点
1、原理
1)使用GAN构建训练数据
- 使用GAN生成与训练数据相似的样本以便与神经网络的压缩
- 把待压缩网络作为一个固定的判别器,来训练生成网络
- 三个损失感受加和,使生成器的生成接近真实数据样本
2)蒸馏算法
- 引入教师学生网络学习范式,利用蒸馏算法实现利用为标注生成样本对黑盒网络的压缩
2、适合于这篇文章中的GAN模型的总损失函数
1)总式
由于判别网络用的是已被训练好的网络,但是该网络被训练来做的是图像分类任务而不是去分辨图像是真实的还是生成的。因此,需要对损失函数进行调整才能使得GAN可以得以进行。该论文将损失函数分为了三个部分:

2)one-hot loss
输入分别表示学生网络和教师网络的输出。如果生成器G生成的图像与教师网络的训练数据分布相同,那么它们的输出也应该与训练数据具有相似的输出。因此使用one-hot loss促使教师网络生成的图像输出接近one-hot like vectors。也就是说,期望生成与教师网络完全兼容的合成图像,而不是适用于任何场景的一般真实图像。

其中,Hcross是交叉熵损失函数,有i个样本,yiT是判别网络(教师网络)对第i ii个样本的输出,因为判别网络(教师网络)是对图像进行分类的网络,因此其有多个输出并使用的是softmax,因此当输入的是真实的图像时,此时输出应该是稀疏的,即应该有某个类别的概率是非常大的,而如果输入的图像和训练集图像差异太大的话,此时网络是无法提取有用的特征来作最后的分类的,此时判别网络(教师网络)的输出就不是稀疏的。因此,通过判断判别网络(教师网络)输出的稀疏性与否可以来衡量输入是生成网络生成的还是真实的。
3)激活损失函数
激活损失函数相当于是看输入的图像是否会触发网络的某些特征提取器,如果能触发,则证明输入的图片和真实训练集是比较相似的,如果触发的特征提取器较多,则说明输入的图片是真实图片的概率较大,因为网络中的特征提取器就是被训练来提取真实训练集中的图像特征的。这样便能分辨输入的图像时自然的还是生成的了。

4)生成图像的信息熵损失函数
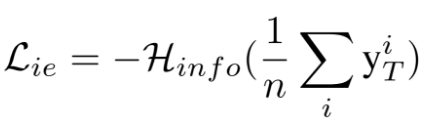
训练数据的类别基本均衡,entropy loss 来衡量生成图片的类别均衡, 当所有的变量为1/k时得到最大值。 当loss最小的时候,每个1/n*∑yi应该等于1/k 。说明G生成的每个类别的图片的概率大致相等。因此, 最小化信息熵损失能够得到一组类别数量均衡的生成样本。
3、利用知识蒸馏将教师网络压缩为学生网络
知识蒸馏(Knowledge Distillation, KD)是一种广泛使用的方法,用于将输出信息从大的网络转移到较小的网络,以获得更高的性能,它不使用给定网络的参数和体系结构。通过以下的损失函数LKD 即可实现将教师网络的知识蒸馏到学生网络的操作:

4、算法















 746
746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









