









本文内容转自本人的微信公众平台,计划此后将通过CSDN进行更新~
-------------------------------------
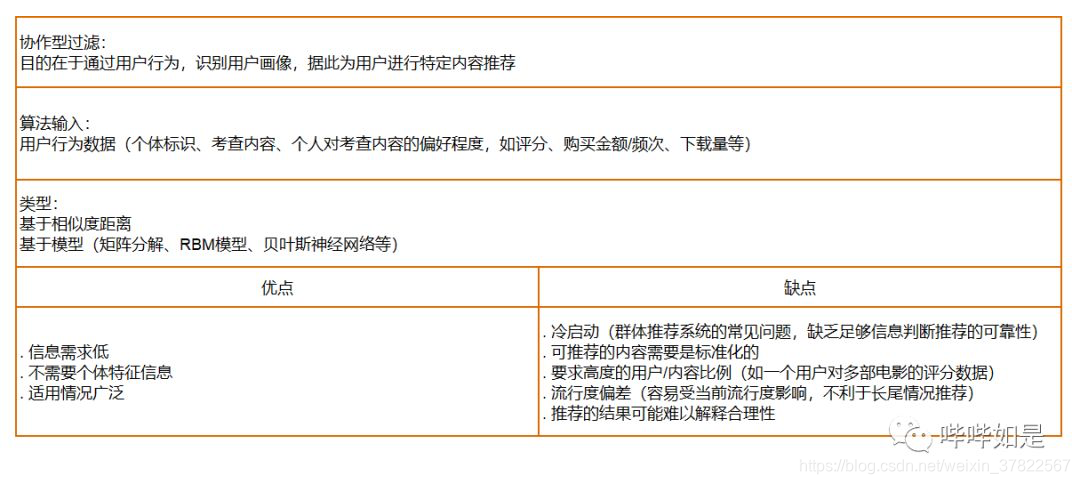
推荐算法,直接从字面理解,即通过算法为用户进行内容推荐。常见的推荐类型包括:
- 协作型过滤,Collaborative Filtering
- 基于内容的过滤,Content-based Filtering
- 混合方法,Hybrid Approaches
- 基于流行度的推荐,Popularity
结合《集体智慧编程》一书内容,本篇内容将分享对协作型过滤的理解。文中的脚本均摘自书中。

协作型过滤,即从一个群体中进行搜索,找出相似性接近的一部分个体作为小群体,并对这些小群体所偏爱的其他内容进行考查,构造推荐列表,从而实现根据个体与这些小群体的相似度,向个体进行内容推荐。
协作型过滤的一般过程如下:
- 一、搜集群体的内容偏好:
了解群体对内容的偏好程度,需确认该群体内的个体标识、考查内容、个人对考查内容的偏好程度;例如用户对电影的评分,其中电影即为实质内容,对电影的偏好程度则可通过用户评分进行量化。
根据搜集信息,构建数据集如下:
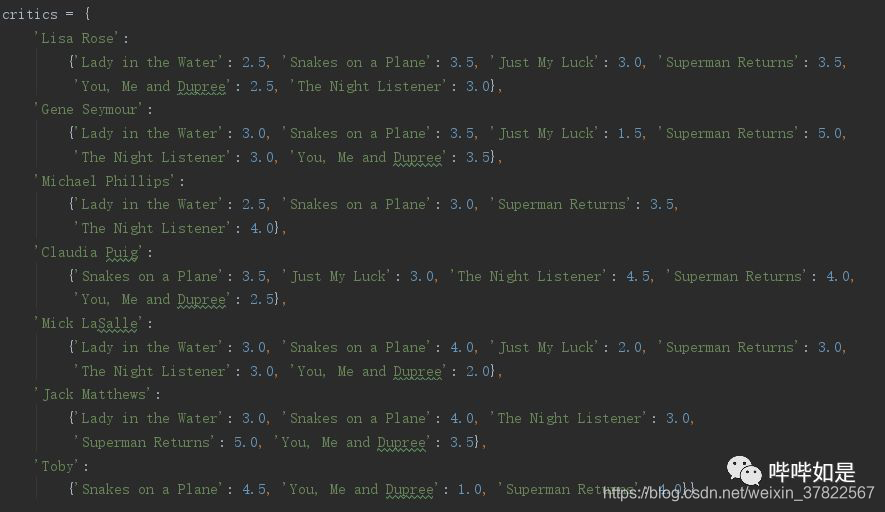
数据集以字典形式储存每位用户对多部电影的评分,信息包括用户标识(名字)、内容(电影名称)、偏好程度(评分),数据集的数据格式如下:
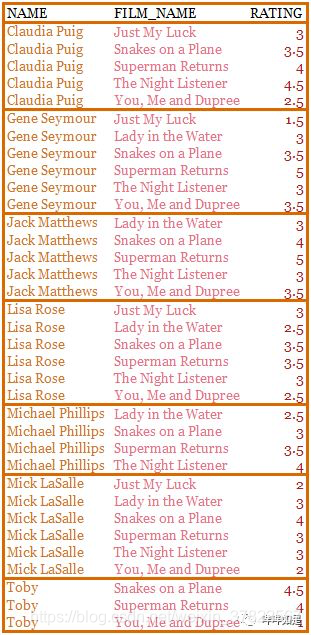
- 二、寻找相近的用户:
首先对“相近”程度进行定义,即两个个体的空间距离。常见的相似度评价体系有欧几里得距离、皮尔逊相关度、Jaccard系数、曼哈顿距离算法等,几种体系的不同点主要在于距离的计算方法不同。《集体智慧编程》一书中主要提及欧几里得距离和皮尔逊相关度两种体系,本篇内容亦只对这两种体系进行理解阐述。
- 欧几里得距离评价
欧几里得距离是计算相似程度的非常简单的方法,两个个体之间的欧几里得距离,即该两个空间坐标的欧几里得空间距离。

欧几里得距离是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离(摘自百度百科:欧几里得距离)。
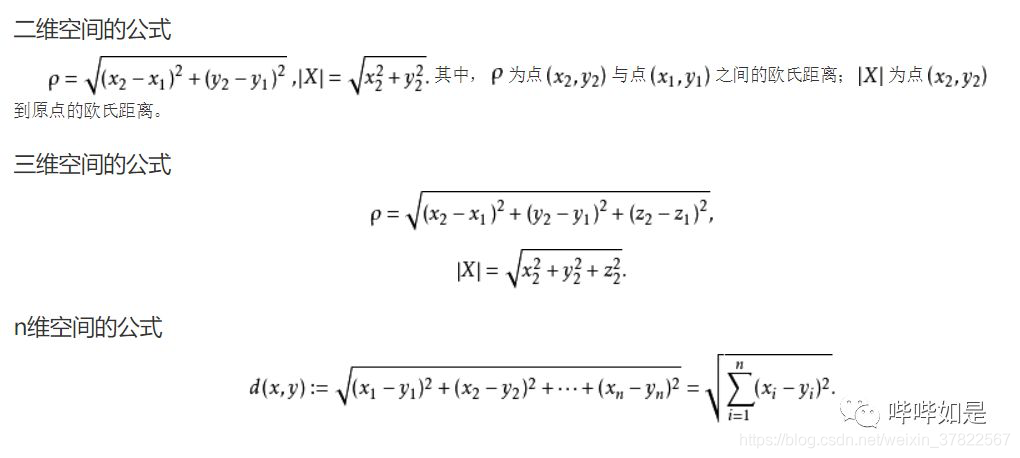
对应前述电影评分数据集,我们可以用每部分电影的评分作为一个维度,这样就可以通过每位用户的评分,用坐标定义用户的位置,从而可以计算任意两位用户之间的欧几里得距离。
对于电影偏好越相似的用户,距离越短,反之越长。为统计上的方便,需对欧几里得距离上进行转换,从而可以通过相似度体现越相似的用户之间的相关程度越大,因此定义相似度为:
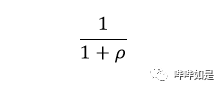
其中为欧几里得距离。
该相似度的值在0-1之间,当两者距离为0时,相似度为1,即两人有相同的偏好;当两者距离趋于无穷大时,相似度接近于0,两人的偏好完全不一致。以上转换方法为空间长度范围转换的常用方法。python的实现脚本如下:
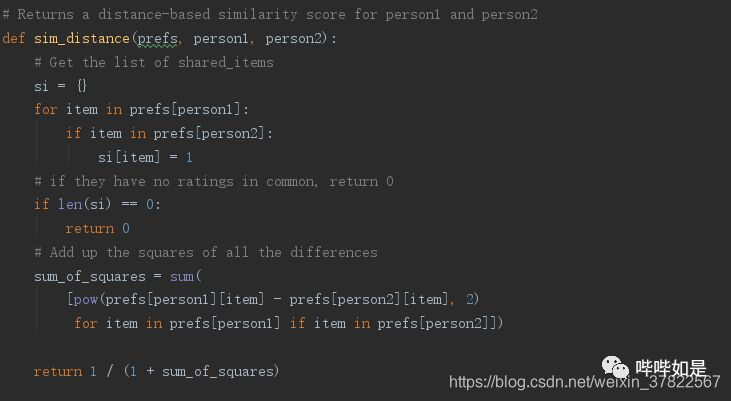
- 皮尔逊相关度评价
皮尔逊相关系数的理解相对复杂,需理解统计上协方差和标准差的概念。

从初步理解推荐算法角度,并无需过于深入理解皮尔逊相关系数的计算方法,只需了解其在推荐算法中的作用即可。以下定义摘自百度百科:皮尔逊相关系数。

皮尔逊相关系数是判断两组数据与某一直线拟合程度的一种度量,在数据不是很规范时(例如存在小部分用户对内容的偏好远远偏离平均值),相对欧几里得距离往往可给出更好的距离评价效果。
计算两个个体的皮尔逊相关系数的python的实现脚本如下:
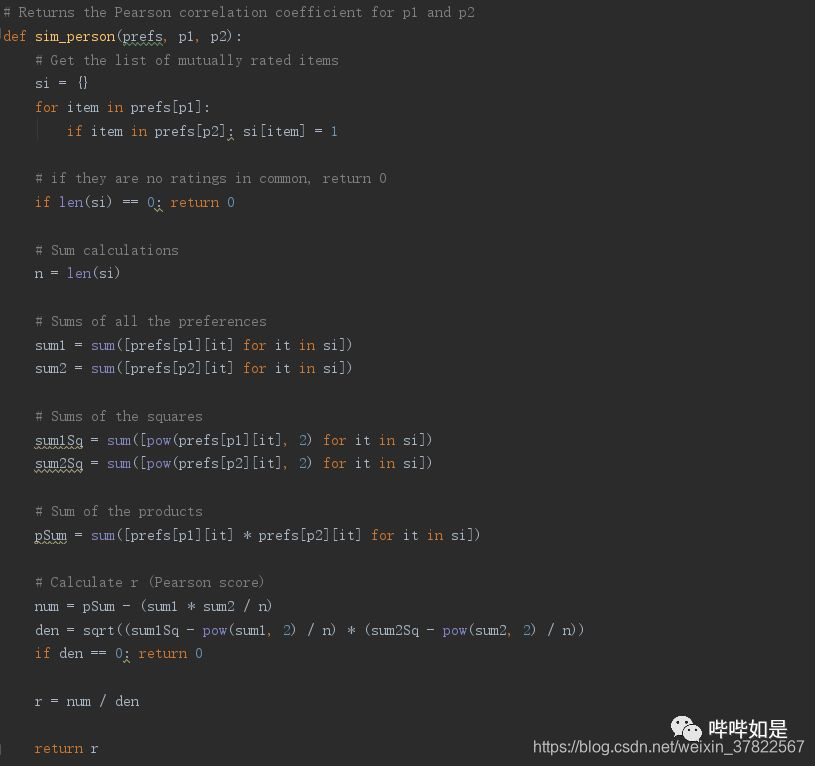
皮尔逊相关系数介于-1至1之间,1表明两者对每一项内容均有完全一致的偏好程度。对于皮尔逊相关系数,没有需要进行数值的转换。
- 三、内容推荐
通过欧几里得距离或皮尔逊相关系数,我们可以了解群体内两两之间的相似程度,从而可以从相似度最大的个体的偏好中,为用户提供内容推荐,但若只考虑相似度最大的个体,推荐结果可能存在片面性。
为此,可以考虑结合用户和其他个体的相似度,利用加权的评价值为影片评分,形成对于用户的影片评分列表,从而可为用户进行更好的推荐。
脚本实现如下:
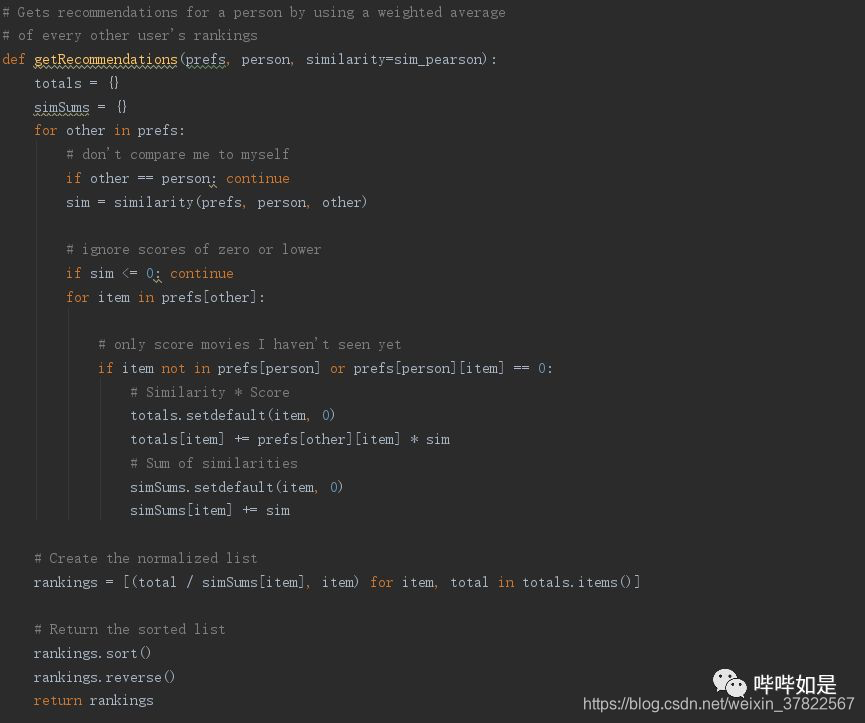

以对Toby的推荐为例,计算Toby与其他评论者的皮尔逊相关系数作为相似度,并统计每部电影的加权总分,最初除以相似度的累计值(减少评论者的未评分电影的影响),即可得到对Toby的电影推荐评分。
综上所述,基于用户的协作型过滤算法,概述步骤如下:
- 搜集群体对特定内容的偏好信息,并进行量化,创建数据集;
- 利用相似度模型,计算用户与群体内每个个体的两两之间的相似度;
- 利用相似度系数,对群体内偏好数据进行加权统计,获得对用户的最佳推荐。
以上为基于用户的协作型过滤,基于内容的协作型过滤原理相似。在本质上,基于内容和基于用户的协作型过滤的思路是相同的:基于用户的协作型过滤,是根据用户对内容的评分,计算用户之间的相似度;基于内容的协作型过滤,则是根据内容的用户评分情况,计算不同内容之间的相似度,从而可以根据用户的内容偏好,向用户推荐类似的内容。

对于基于用户或基于内容的协作型过滤的选择,往往需考虑数据的“稀疏程度”。例如对于电影推荐,假如每个评论人都对所有电影进行了评分,则可称评论人的电影评分数据集是“密集”的;若大部分评论人仅对其中小部分电影进行了评分,则可称该数据集是相对“稀疏”的。对于密集数据,基于用户的过滤往往有更好的推荐效果;反之则是基于物品的过滤更有优势。
以上为协作型过滤的全文介绍。对于前文中提及的距离评价体系,如欧几里得距离、皮尔逊相关度等,本文中未详细介绍他们之间的异同。在下一篇推送中将分享如何在各种距离评价体系中进行选择。
详情请见下回分解,拜~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









