







【数据结构】排序算法
算法的时间复杂度
时间频度T(n)怎么计算
比如:计算1-100的所有数字之和,我们设计了两种算法:
1.使用for循环计算
int total=0;
int end=100;
//使用for循环计算
for(int i=1;i<=end;i++){
total+=i;
}
T(n)=n+1
这里的+1,是因为for循环最后还要判断一次i<=end,不符合跳出for循环
2.直接计算
total=(1+end)*end/2;
T(n)=1
一条公式,只需要计算一次
忽略常数项
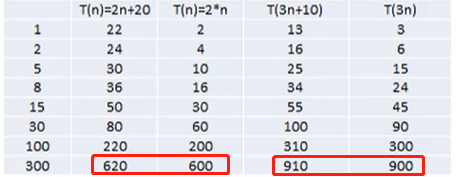

忽略低次项
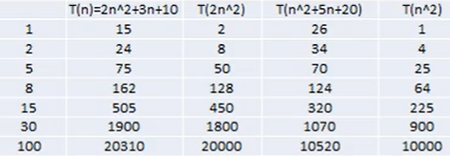


有幂可以忽略斜率
n2可以忽略系数
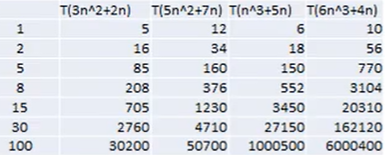


渐进时间复杂度O(n)
时间复杂度与时间频度的关系:

计算时间复杂度的方法:

常见的时间复杂度



常数阶O(1)
无论代码执行了几多行,只要是没有循环等复杂结构,那这个代码的时间复杂度就是O(1)
对数阶O( log 2 n \log_2 n log2n)
回顾对数:
如果N=ax(a>0,
a
≠
1
a\neq1
a=1),
即a的x次方等于N,那么x叫做以a为底,N的对数(logarithmic),记作
x
=
log
a
N
x=\log_a N
x=logaN
int i=1;
while(i<n){
i=i*2;
}
假设n=16
| int i | 条件 while(i<n) | 循环体 i=i*2 | 次数 | 规律 |
|---|---|---|---|---|
| 1 | 1<16 | 2=1*2 | 1 | 21 |
| 2 | 2<16 | 4=2*2 | 2 | 22 |
| 4 | 4<16 | 8=4*2 | 3 | 23 |
| 8 | 8<16 | 16=8*2 | 4 | 24 |
| 16 | 16不小于16 | 跳出循环 | - | - |
观察循环体,可以发现,每进入循环体一次,都会带着之前乘过的次数积再*2,也就是每进入循环体一次,就是2的+1次方,如次数-规律。
再看条件,可以发现,n就是2的次方积。
当n=8,循环了3次,就结束循环。
当n=16,循环了4次,就结束循环。
当n=2x,循环了
log
2
n
\log_2 n
log2n次,就结束循环,所以时间复杂度为
log
2
n
\log_2 n
log2n。
当上述代码改成
int i=1;
while(i<n){
i=i*3;
}
时间复杂度为 log 3 n \log_3 n log3n。
线性阶O(n)
for(i=1;i<=n;++i){
j=i;
j++;
}
这段代码中,for循环里面的代码会执行n+1遍,(++i),忽略常数项,
因此他消耗的时间随着n的变化而变化,这类代码都可以用O(n)来表示它的时间复杂度
线性对数阶O(N log 2 n \log_2 n log2n)
for(m=1;m<N;m++){
i=1;
while(i<n){
i=i*2;
}
}
将时间复杂度为O( log 2 n \log_2 n log2n)的代码循环N遍的话,那么它的时间复杂度就是N*O( log 2 n \log_2 n log2n),也就是O(N log 2 n \log_2 n log2n)
平方阶O(n2)
for(x=1;x<=n;x++){
for(i=1;i<=n;i++){
j=i;
j++;
}
}
把O(n)的代码再嵌套循环一遍,也就是嵌套了2层n循环,它的时间复杂度就是O(n*n),也就是平方阶O(n2)
for(x=1;x<=m;x++){
for(i=1;i<=n;i++){
j=i;
j++;
}
}
把其中一层循环改成m,那么它的时间复杂度就是O(m*n)
平均时间复杂度与最坏时间复杂度

空间复杂度
- 一个算法在运行过程中临时占用存储空间大小的量度.
- 在做算法分析时,主要讨论的是时间复杂度.从用户使用体验上看,更看重的程序执行的速度.
- 一些缓存产品(redis,memcache)和算法(基数排序)本质就是用空间换时间















 1686
1686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









