







 本文介绍了如何利用pandas在Python中处理数据,具体操作是根据某一层索引进行分组,然后找出每组中某一列的最大值对应的行。通过重置索引、分组、idxmax()函数以及iloc选择器,实现按需求筛选数据。原始问题来源于StackOverflow,但原解决方案可能已因pandas更新而不再适用。
本文介绍了如何利用pandas在Python中处理数据,具体操作是根据某一层索引进行分组,然后找出每组中某一列的最大值对应的行。通过重置索引、分组、idxmax()函数以及iloc选择器,实现按需求筛选数据。原始问题来源于StackOverflow,但原解决方案可能已因pandas更新而不再适用。
本文是根据stackoverflow上一个问题进行的复盘,若涉及任何侵权,请联系我修改或删除。
stackoverflow原文链接 -->
https://stackoverflow.com/questions/32459325/python-pandas-dataframe-select-row-by-max-value-in-group
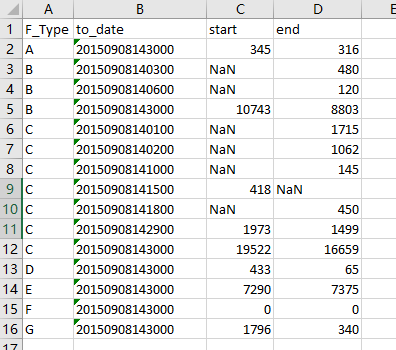
我将上面的数据直接复制粘贴到excel中,分列及填充F_Type列后,保存为csv格式。
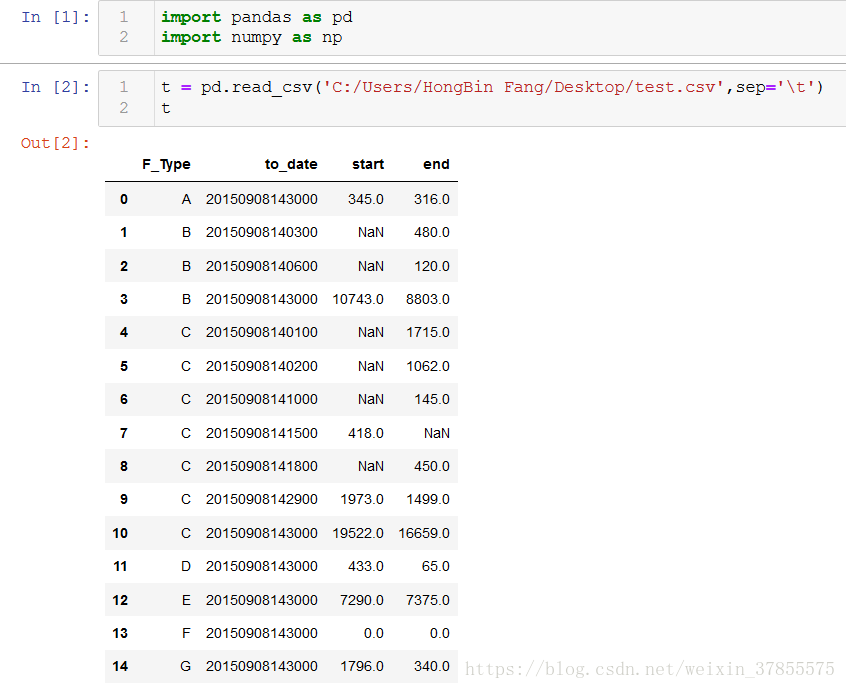
接下来,用pandas.read_csv导入到python中,
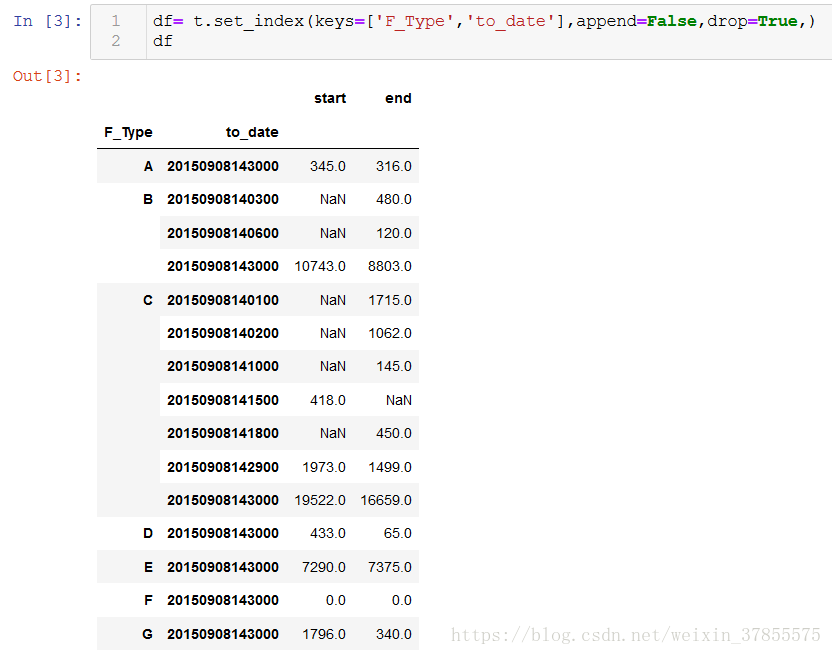
重新设置索引就可以显示出与原问题相同的结构
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1373
1373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









