







使用 Dall-E 3 生成
**注意:**本文摘录自我的最新笔记本《使用 Mistral 7b 进行检索增强生成 📁 | Kaggle》。为了获得增强的阅读体验,我建议您在 Kaggle 上查看。
介绍
大型语言模型是令人惊叹的工具,它可以帮助人类获得问题的答案、总结大量文本、将文档从一种语言翻译成另一种语言、帮助我们编码等等。
然而,LLM 有一个主要问题:幻觉。当 LLM 从其训练数据中吐出随机事实时,即使它可能与用户的提示没有真正的联系,也会发生幻觉。大型语言模型很难对没有答案的问题说*“我不知道” 。*
**检索增强生成 (RAG)**是一个 AI 框架,有两个主要目标:通过将模型连接到外部知识源来提高生成的响应的质量,并确保用户可以访问模型的源,以便您可以检查其答案的准确性。
通过 RAG,我们还可以确保大型语言模型能够访问**专有数据,**方法是将其连接到可从中检索信息的自定义数据源。
下图可以清楚地理解 RAG 的工作原理。首先,用户向 LLM 提出问题。在到达模型之前,问题会到达检索器**。检索器将负责从知识库中查找和检索相关文档以回答问题。**然后将问题以及相关文档发送给 LLM,LLM 将能够根据收到的文档中的来源生成基于来源的答案。
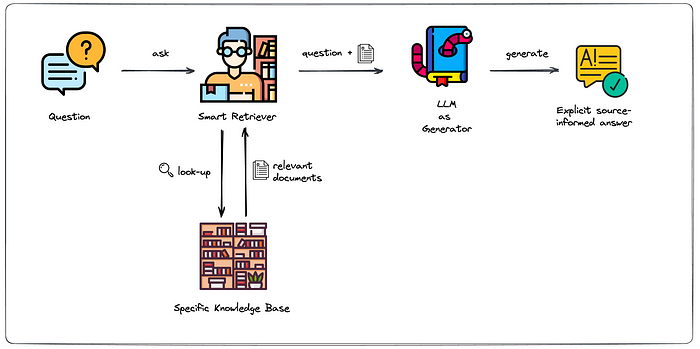
来源:ml6.eu
在此笔记本中,我们将使用Wikipedia Crypto Articles(我几天前在 Kaggle 上上传的数据集)为 LLM 实现检索增强生成系统。
在开始编写代码之前,让我们先安装一些相关的软件包。这些软件包包括:
• Chromadb**:**一个开源嵌入数据库,允许我们将 LLM 插入知识库。它允许我们存储和查询嵌入及其元数据。
• LangChain**:**一个允许我们开发由 LLM 提供支持的多个应用程序的框架。
•句子转换器**:**该框架利用预先训练的转换器模型,提供一种简单的方法来计算句子、段落和图像的密集向量表示。
• bitsandbytes**:**一个旨在通过对模型权重进行 4 位量化来优化大型模型的训练和部署的库,减少内存占用并提高内存效率。
# 自动 DataViz 工具
!pip install ydata-profiling
# Chromadb
!pip 安装 chromadb
# LangChain
!pip 安装 langchain
# 句子转换器
!pip install sentence_transformers
#bitsandbytes
!pip 安装 bitsandbytes
# 导入库
# 数据处理
import pandas as pd
import numpy as np
# 自动 EDA
from ydata_profiling import ProfileReport
# Torch 和 Transformers
import torch
from torch import bfloat16
import transformers
from transformers import AutoTokenizer
# LangChain
from langchain.llms import HuggingFacePipeline
from langchain.document_loaders import DataFrameLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain.vectorstores import Chroma
# 隐藏警告
import warnings
warnings.filterwarnings( "ignore" )
# 检查 GPU 是否可用
if torch.cuda.is_available():
gpu_name = torch.cuda.get_device_name(torch.cuda.current_device())
total_memory = torch.cuda.get_device_properties( 0 ).total_memory
total_memory_gb = total_memory / ( 1024 ** 3 ) # 将内存转换为 Gb
print ( "GPU 可用。\n使用 GPU" )
print ( "\nGPU 名称:",gpu_name)
print ( f"总 GPU 内存:{total_memory_gb:.2 f} GB" )
device = torch.device( 'cuda' )
else:
print ( "GPU 不可用。\n使用 CPU" )
device = torch.device( 'cpu' )
GPU 可用。
正在使用 GPU
GPU 名称:Tesla T4
总 GPU 内存:14.75 GB
数据检查
正如我之前提到的,我们将使用Wikipedia 加密文章数据集作为该模型的知识源库。
我们将使用自动可视化工具 YData Profiling,仅用几行代码从数据集中提取一些信息。
# 加载数据框
df = pd.read_csv( '/kaggle/input/wikipedia-crypto-articles/Wikipedia Crypto Articles.csv' )
# 生成报告
report = ProfileReport(df, title = 'Wikipedia Crypto Articles' )
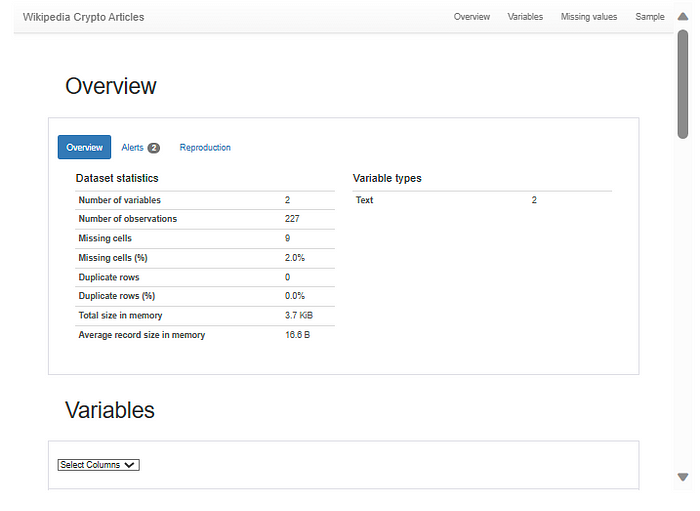
报告片段。访问Retrieval Augmented Generation with Mistral 7b 📁 | Kaggle与其互动
数据集由两列title和组成article。我们有九个条目包含空文章。我们将删除这些行。
数据框长度:227 行
删除空值后的长度:218 行
让我们看一下数据框的内容。我将打印article最后一条条目的标题和文本内容。
标题:NEO(加密货币)
Neo 是一个基于区块链的加密货币和应用平台,用于运行智能合约和去中心化应用程序。该项目最初名为 Antshares,由达鸿飞和张铮文于 2014 年创立,2017 年更名为 Neo。2017 年和 2018 年,尽管中国最近颁布了加密货币禁令,但该加密货币在中国市场仍取得了一些成功。
== 技术规格 ==
Neo 网络在多个中央批准节点之间采用权益证明去中心化拜占庭容错 (dBFT) 共识机制运行,每秒最多可支持 10,000 笔交易。Neo 区块链的基础资产是不可分割的 Neo 代币,可生成 GAS 代币。这些 GAS 代币是网络上的独立资产,可用于支付交易费用,可分割为最小单位 0.00000001。 GAS 的通胀率由衰减半衰期算法控制,旨在在约 22 年内释放 1 亿个 GAS。X.509 数字身份允许开发人员将代币与现实世界的身份绑定,这有助于遵守 KYC/AML 和其他监管要求。
== 历史 ==
2014 年,达鸿飞和张铮文创立了小蚁。次年,它在 GitHub 上开源,并于 2015 年 9 月发布白皮书。创世区块共创建了 1 亿个 Neo。2016 年,通过首次代币发行向早期投资者出售了 5000 万个 Neo,筹集了 465 万美元,其余 5000 万个 Neo 锁定在智能合约中。每年最多解锁 1500 万个 Neo 代币,Neo 开发团队使用这些代币为长期开发目标提供资金。2017 年 6 月,Neo 由 Antshares 正式更名,旨在将过去与未来相结合。Neo3 或 N3 于 2018 年由 Erik Zhang 首次宣布,作为对之前 Neo 协议(现称为 Neo Legacy)的升级。某些新功能与 Neo Legacy 区块链不具有向后兼容性。N3 已实施并随新的创世块一起推出。2018 年 3 月,Neo 的母公司 Onchain 为用户加密货币钱包中每持有 5 个 NEO 分发 1 个 Ontology 代币 (ONT)。这些代币旨在用于对 Neo 平台上的系统升级、身份验证机制和其他治理问题进行投票。
== 参考资料 ==
== 外部链接 ==
官方网站
存储数据
LangChain 有一个称为文档加载器的工具,它允许我们从源加载几种类型的数据作为document。document包含文本和相关元数据。我们将使用该类DataFrameLoader从 pandas DataFrame 加载数据。
# 将数据框内容加载到文档中
articles = DataFrameLoader(df,
page_content_column = "title" )
# 将整个数据框加载到文档格式
document = articles.load()
在从文档创建嵌入之前,我们必须将其拆分成更小的块。这样做有几个原因。
首先,嵌入模型可能具有最大令牌限制,并且拆分数据可确保每个块都符合这些限制。
其次,较小的块更节省内存,从而降低计算成本。
第三,嵌入更小且连贯的文本片段可能会带来更高的准确性和更有意义的表示。
我们将使用 LangChainsRecursiveCharacterTextSplitter来分割我们的数据。
# 将文档分割成更小的块
splitter = RecursiveCharacterTextSplitter(chunk_size = 1000 ,
chunk_overlap = 20 )
splitted_texts = splitter.split_documents(document)
我们将使用HuggingFaceEmbeddingsSentenceTransformers 🤗 加载模型。更具体地说,我们将加载模型sentence-transformers/all-MiniLM-L6-v2,该模型将句子和段落映射到 384 维密集向量空间。
# 加载模型以创建嵌入
embedding_model = HuggingFaceEmbeddings(model_name= "sentence-transformers/all-MiniLM-L6-v2" )
使用Chroma,我们将创建嵌入数据的索引数据库。我们使用.from_documents( )Chroma 类中的方法并输入文本块、splitted_texts嵌入模型embedding_model,最后指定将存储索引数据库的目录。
# 创建和索引数据库
chroma_database = Chroma.from_documents(splitted_texts,
embedding_model,
persist_directory = 'chroma_db' )
您可以在下面看到那chroma_database是一个矢量存储。
# 可视化数据库
chroma_database
<langchain_community.vectorstores.chroma.Chroma 位于 0x7bc54e8b2ec0>
我们使用向量存储来存储嵌入数据。当我们向模型询问某件事时,链将嵌入此查询,并根据它们与嵌入查询之间的“相似性”使用它从向量存储中检索嵌入向量。向量存储仅负责存储嵌入数据并执行向量搜索以找到我们问题的高质量答案。
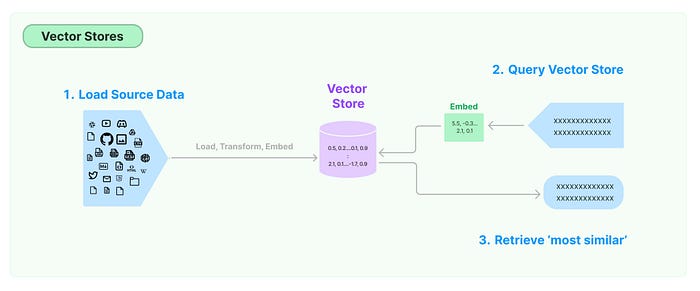
下面,我们定义一个检索器。检索器负责根据给定的查询从向量存储中检索文档。它们接受字符串查询作为输入,并返回documents 列表作为输出。
# 定义检索器 triester
= chroma_database.as_retriever()
VectorStoreRetriever(标签=['Chroma', 'HuggingFaceEmbeddings'], vectorstore=<langchain_community.vectorstores.chroma.Chroma 对象位于 0x7bc54e8b2ec0>)
您可以在上面看到,对象retriever是的实例VectorStoreRetriever,并且它链接到向量存储chroma_database。
加载 Mistral 7b 模型
我们可以使用类加载大型语言模型HuggingFacePipeline,这使我们能够访问 Huggingface.co 上公开提供的超过 120,000 个开源模型。我们将加载的模型是mistralai/Mistral-7B-v0.1该text-generation任务的模型。
Mistral 7B 是一款开源 7.3B 参数模型,在所有基准测试中均优于 Meta 的 Llama 2 13B。它是 2024 年 1 月上市的最强大的开源模型之一。
由于这是一个大型模型,我们将使用该bitsandbytes库来创建变量,quantization_config该变量将以 4 位量化格式加载模型并启用双量化。我们还将计算数据类型设置为 bfloat16。这些设置可优化模型的大小和性能,避免内存使用问题。
# 配置 BitsAndBytesConfig 以最佳方式加载模型
quantization_config = transformers.BitsAndBytesConfig(load_in_4bit = True ,
bnb_4bit_quant_type = 'nf4' ,
bnb_4bit_use_double_quant = True ,
bnb_4bit_compute_dtype = bfloat16)
我们最终将模型加载到llm变量中。使用model_kwargs字典,我们为模型定义一些行为。例如,temperature是一个范围从 0.0 到 1.0 的参数,它定义了模型的*“创造性”*max_length 。较低的值使响应更可预测。定义生成的输出的最大长度,并quantization_config应用先前定义的量化配置来优化模型。
# 加载 Mistral 7b 模型
llm = HuggingFacePipeline.from_model_id(model_id= '/kaggle/input/mistral/pytorch/7b-instruct-v0.1-hf/1' ,
task = 'text-generation' ,
model_kwargs={ 'temperature' : .3 ,
'max_length' : 1024 ,
'quantization_config' : quantization_config},
device_map = "auto" )
在 LangChain 中,我们有称为Chains的模块,即对 LLM 的一系列调用。其中一个链是RetrievalQA,它从索引数据库中获取相关文档,然后将这些文档传递到 LLM 以生成响应。让我们定义一个问答链。
# 定义 QnA 链 QnA
= RetrievalQA.from_chain_type(llm = llm,
chain_type = 'stuff' ,
triest = triest,
verbose = False )
查询模型
下面,我将定义一个get_answers函数,它接受QnA我们上面创建的链和一个查询,这是我们向 LLM 提出的问题。
# 定义函数根据查询获取文档
def get_answers ( QnA, query ):
answer = QnA.run(query)
print ( f"\033[1mQuery:\033[0m {query} \n" )
print ( f"\033[1mAnswer:\033[0m " , answer)
现在我们可以向模型提问了!让我们从几个例子开始。
问题:谁创造了比特币?它是什么时候创造的?
答案:比特币是由一个不知名的人或一群人使用中本聪的名字创建的。它于 2009 年创建。
问题:加密货币历史上最大的骗局是什么?
答:加密货币历史上最大的骗局是 2021 年 Squid Game 加密货币骗局。
问题:2030 年一枚比特币的价格是多少?
答案:我不知道。
问题:请列举五个与加密货币相关的人的名字?
答案:1. Andreas Antonopolous 2. Brian Armstrong 3. Changpeng Zhao 4. Andreas Antonopolous 5. Andreas Antonopolous
问题:我可以使用哪些交易所购买加密货币?
答案:Crypto.com 是一家加密货币交易所,为各种加密货币提供首次交易发行 (IEO)。 它在欧洲和世界其他地区均可使用。
问题:谁构想了以太坊?
答案:Vitalik Buterin 构想了以太坊。
当被问及谁创造了比特币以及比特币何时被创造时,模型回答正确。老实说,我不知道鱿鱼游戏骗局是否是最大的骗局,但它是 2021 年左右发生的骗局,你可以在维基百科上阅读有关它的内容。
当被问及 2030 年一枚比特币的价格时,模型回答**“我不知道”**,这很好。我们不希望模型对它无法访问的信息进行猜测。
当被问及加密货币领域五位相关人士的名字时,该模型多次重复了Andreas Antonopoulos的名字,甚至拼错了他的姓氏。这里肯定还有改进的空间,但尽管如此,该模型还是正确地说出了与加密货币相关的人的名字。
在下面的代码中,我们将使用query从向量存储中检索文档并显示检索到的文档数量和这些文档的来源,即 Wikipedia 上显示的文章标题。我还将从文档的元数据中打印文章文本的前 350 个字符,以便您可以阅读其中的一部分。
# 获取来源和搜索的文档
docs = chroma_database.similarity_search(query)
print ( f'Query: {query} ' )
print ( f'Retrieved documents: { len (docs)} ' )
for doc in docs:
details = doc.to_json()[ 'kwargs' ]
print ( "\nSource (Article Title):" , details[ 'page_content' ])
print ( "\nText" , details[ 'metadata' ][ 'article' ][: 350 ] + ". . ." )
print ( '\n\n\n' )
查询:谁构思了以太坊?
检索到的文档:4
来源(文章标题):以太坊
文本 以太坊是一个具有智能合约功能的去中心化区块链。以太币(缩写:ETH;符号:Ξ)是该平台的原生加密货币。在加密货币中,以太币的市值仅次于比特币。它是开源软件。
以太坊由程序员 Vitalik Buterin 于 2013 年构思。其他创始人...
来源(文章标题):比特币的历史
文本 比特币是一种加密货币,是一种使用加密技术来控制其创建和管理而不是依赖中央权威的数字资产。比特币最初设计为一种交换媒介,现在主要被视为一种价值储存手段。比特币的历史始于中本聪的发明和实施,他整合了...
来源(文章标题):以太坊经典
文本 以太坊经典是一个基于区块链的分布式计算平台,提供智能合约(脚本)功能。它是开源的,并通过在公共以太坊虚拟机(EVM)上执行的基于交易的状态转换支持修改版的中本聪共识。
以太坊经典保留了原始的、未经改变的历史记录。 。
来源(文章标题):比特币的崛起
文本 比特币的崛起是一部 2014 年美国纪录片,由 Nicholas Mross 执导。该片采访了在比特币历史扩展中发挥重要作用的多家公司和人士。它于 2014 年 4 月 23 日在纽约翠贝卡电影节首映。该片被提名为“最佳国际纪录片”。 。 。
# 尝试不同的查询
query = """我可以使用哪些交易所购买加密货币?"""
docs = chroma_database.similarity_search(query)
print ( f'Query: {query} ' )
print ( f'Retrieved documents: { len (docs)} ' )
for doc in docs:
details = doc.to_json()[ 'kwargs' ]
print ( "\nSource (Article Title):" , details[ 'page_content' ])
print ( "\nText" , details[ 'metadata' ][ 'article' ][: 350 ] + ". . ." )
print ( '\n\n\n' )
查询:我可以使用哪些交易所购买加密货币?
检索到的文件:4
来源(文章标题):加密货币交易所
文本 加密货币交易所或数字货币交易所 (DCE) 是一种允许客户将加密货币或数字货币交易为其他资产(例如传统法定货币或其他数字货币)的业务。 交易所可能会接受信用卡付款、电汇或其他形式的付款以换取数字货币或 。 。
来源(文章标题):Crypto.com
文本 Crypto.com 是一家总部位于新加坡的加密货币交易所公司。 截至 2023 年 6 月,该公司据称拥有 8000 万客户和 4,000 名员工。 该交易所发行自己的交易所代币 Cronos (CRO)。
== 历史 ==
该公司最初由 Bobby Bao、Gary Or、Kris Marszalek 和 Rafael Melo 于 2016 年在香港创立,名为“Mon...
来源(文章标题):首次交易所发行
文本 首次交易所发行 (IEO) 是相当于股票发行或首次公开募股 (IPO) 的加密货币交易所。IEO 是通过已建立的交易所采购数字资产(例如硬币或代币)的过程,目的是为初创公司筹集资金。交易所充当投资者和投资者之间的中间人...
来源(文章标题):欧洲的加密货币
文本 欧洲加密货币的一般概念表示欧洲加密货币的立法监管、分发、流通和存储过程。 2023 年 4 月,欧盟议会通过了《加密市场法案》(MiCA),这是欧盟内部加密资产的统一法律框架。
== 加密货币的合法性...
结论
在本笔记本中,我们探索了检索增强生成 (RAG),这是一种通过索引矢量化数据库让 LLM 访问外部数据以检索信息,从而改进 LLM 输出的过程。
我们使用了Mistral 7b 模型,这是 2024 年 1 月最有效的开源模型之一。为了进行测试,我们使用了Wikipedia Crypto Articles,这是我通过从 Wikipedia 获取与加密货币相关的文章创建的数据集。
检索增强生成 (RAG),这是一种通过索引矢量化数据库让 LLM 访问外部数据以检索信息,从而改进 LLM 输出的过程。
我们使用了Mistral 7b 模型,这是 2024 年 1 月最有效的开源模型之一。为了进行测试,我们使用了Wikipedia Crypto Articles,这是我通过从 Wikipedia 获取与加密货币相关的文章创建的数据集。
我希望这篇笔记能帮助您更深入地了解 RAG 是什么。如果您喜欢这里的内容,请随时留下您的点赞和反馈。我总是喜欢阅读您的评论和您对这个主题的见解。
博客原文:专业人工智能技术社区















 1604
1604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









