






在数字艺术和图像处理的新时代,技术的进步不断拓宽着创意的边界。ComfyUI 提供了一套高效、易用的工作流,通过简单的节点操作即可实现从线稿到真人图像的转换。

这一技术不仅简化了创作流程,还极大地提升了图像生成的质量和效率。本文将详细介绍这一工作流的各个节点及其功能,帮助您全面了解和应用这项强大的技术。

基础节点(Primitive Nodes)
KSampler:
功能: 用于图像采样和生成。KSampler 可以从潜在空间中抽取样本,并将其转换为高质量的图像。这一过程涉及到对图像细节的重构,确保最终生成的图像清晰且富有细节。
CLIPTextEncode:
功能: 对文本进行编码,以便在图像生成过程中融合文本信息。通过将文本描述转化为向量表示,CLIPTextEncode 可以帮助系统理解用户的创作意图,并在图像生成过程中精准地表现出来。
ControlNetApply:
功能: 将控制网络应用于图像处理流程中。ControlNetApply 通过调节生成参数,增强了对图像生成过程的控制性和准确性,使得最终生成的图像更符合预期。
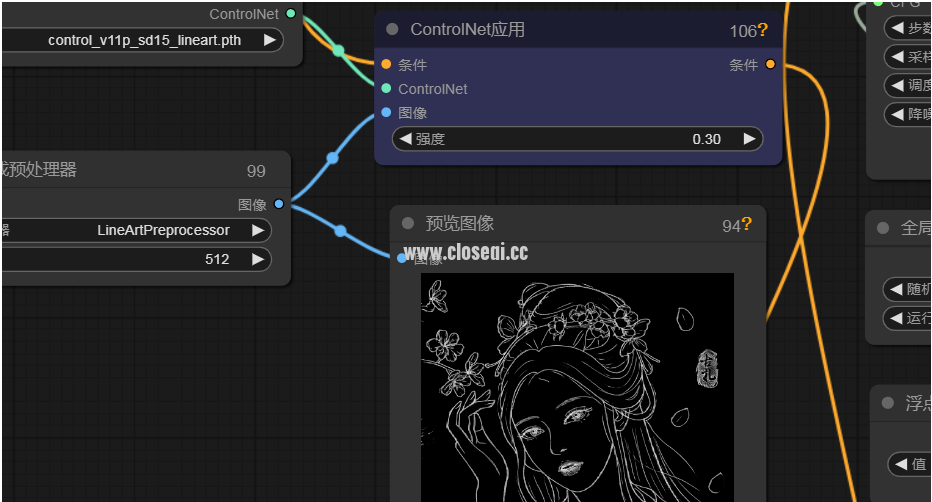
DiffControlNetLoader:
功能: 加载差异控制网络。DiffControlNetLoader 用于进一步精细调整图像生成参数,确保生成过程中的每一个细节都达到最佳效果。
PreviewImage:
功能: 实时预览生成的图像。通过 PreviewImage,用户可以随时查看生成进度和效果,便于及时调整和优化。
VAEDecode:
功能: 变分自编码器解码器。VAEDecode 从潜在空间中生成图像,确保图像的多样性和创新性。
RepeatImageBatch:
功能: 批量处理图像。RepeatImageBatch 提高了处理效率和一致性,适合大规模图像生成需求。
LoadImage:
功能: 加载输入图像,作为生成过程的基础。LoadImage 支持各种图像格式,方便用户导入线稿进行处理。
ImageUpscaleWithModel:
功能: 使用模型对图像进行放大处理。ImageUpscaleWithModel 提升图像分辨率,确保放大后的图像仍然保持高质量。
**VAEEncode:
**功能: 变分自编码器编码器。VAEEncode 将图像编码到潜在空间中,为后续的解码生成做好准备。
UpscaleModelLoader:
功能: 加载图像放大模型。UpscaleModelLoader 支持高质量的图像放大,确保生成的图像清晰且富有细节。
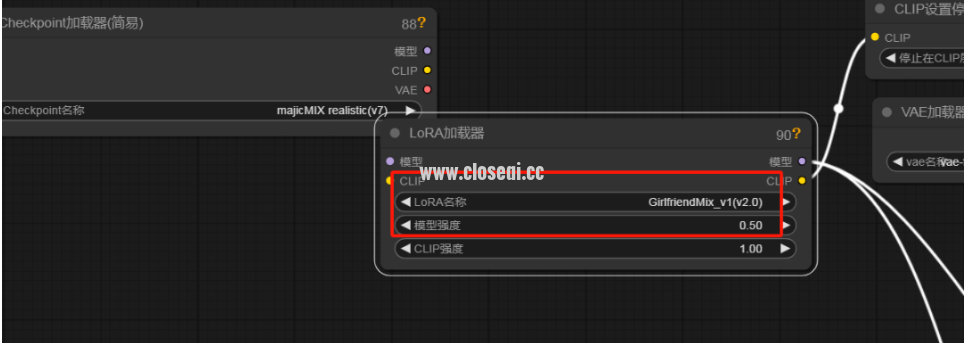
LoraLoader:
功能: 加载 Lora 模型,用于特定风格或特性生成。LoraLoader 可以实现风格化的图像生成,满足用户的个性化需求。
SaveImage:
功能: 保存生成的图像。SaveImage 支持多种图像格式,便于后续使用和分享。
CLIPSetLastLayer:
功能: 设置 CLIP 模型的最后一层。CLIPSetLastLayer 优化了文本与图像的匹配度,确保生成的图像更符合文本描述。
CheckpointLoaderSimple:
功能: 加载检查点,恢复和保存生成状态。CheckpointLoaderSimple 支持随时恢复生成进度,便于长时间的图像生成任务。
VAELoader:
功能: 加载 VAE 模型,支持变分自编码器的使用。VAELoader 提供了多样化的模型选择,满足不同生成需求。
自定义节点(Custom Nodes)
ComfyUI-Custom-Scripts:
功能: 提供自定义脚本支持,增加工作流的灵活性和扩展性。ComfyUI-Custom-Scripts 允许用户根据具体需求编写和加载自定义脚本,提升系统的可操作性。
ComfyUI-Inference-Core-Nodes:
功能: 核心推理节点,提升推理效率和准确性。ComfyUI-Inference-Core-Nodes 通过优化算法和计算流程,确保生成过程快速且准确。
ComfyUI-Easy-Use:
功能: 简化使用流程,使工作流更加用户友好。ComfyUI-Easy-Use 提供了一系列简化操作,降低了用户的使用门槛。
cg-use-everywhere:
功能: 广泛适用于各种场景的节点,增加工作流的通用性。cg-use-everywhere 支持多种生成场景,满足不同创作需求。
检查点(Checkpoints)
majicMIX realistic/v7:
功能: 主要用于生成真实感强的图像,提升最终图像质量。majicMIX realistic/v7 通过优化生成算法,确保生成的图像逼真且富有细节。
Loras
Miao girl costume/v1.0:
功能: 用于生成具有特定服装特征的图像,如苗族女孩的服饰。Miao girl costume/v1.0 提供了丰富的服装细节,增强了图像的文化和视觉表现力。
未知节点(Unknown Nodes)
easy setNode:
功能: 功能未知,可能用于简化某些步骤的设置。easy setNode 或许可以帮助用户快速配置和调整工作流节点。
DF_Image_scale_to_side:
功能: 功能未知,可能与图像比例调整有关。DF_Image_scale_to_side 或许可以在图像生成过程中自动调整图像比例,确保最终图像的视觉效果。
工作流示例
**1.加载线稿图像:**通过LoadImage节点加载输入的线稿图像。无论是简单的草图还是复杂的线稿,都可以作为生成过程的起点。
**2.文本编码:**使用CLIPTextEncode节点对描述线稿的文本进行编码。用户可以输入详细的文本描述,如“穿着苗族服饰的女孩”,系统会将其转化为向量用于生成。
**3.控制网络应用:**通过ControlNetApply节点将控制网络应用到图像生成中。ControlNetApply 通过精细调整生成参数,确保生成的图像符合用户预期。
**4.图像放大:**利用ImageUpscaleWithModel节点将生成的图像放大,提高分辨率。即使是细节丰富的图像,放大后也能保持清晰。
**5.保存图像:**最后使用SaveImage节点保存生成的最终图像。用户可以选择多种格式保存,以便于后续使用和分享。

博客原文:专业人工智能技术社区















 7917
7917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









