







- 内容:Pytorch基本语法
已学完。但是照着代码敲10分类问题准确率只有10%,肯定哪里有问题,有空再回来看吧。敲的代码
Autograd自动求导
- 不太熟悉的函数,来源:
x.data.norm()
又叫“欧几里得范数”,其实就是高中学的取模长||x||。具体计算为 ( x 1 2 + x 2 2 + . . . + x n 2 ) \sqrt{(x1^{2}+x2^{2}+...+xn^{2})} (x12+x22+...+xn2)
- backward的使用,即dy/dx
注意:y必须是标量才能使用backward;若y=[y1,y2],backward是会报如下错误的:“RuntimeError: grad can be implicitly created only for scalar outputs”。正确代码如下
import torch
'''d(scalar)/d(Tensor)'''
x = torch.ones(2, 2, requires_grad=True)
y = x + 2
z = y * y * 3
out = z.mean() # tensor(27., grad_fn=<MeanBackward0>),此时out为标量scalar
out.backward() # scalar可直接使用backward()反向传播
print(x.grad) # 即求导数d(out)/dx,scalar对每个分量求偏导,组成雅各比矩阵
'''Tensor不能对Tensor求导!'''
x = torch.ones(3, requires_grad=True)
y = x * 2 # tensor([2., 2., 2.], grad_fn=<MulBackward0>)
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(v) ???????
print(x.grad)
代码中不是很懂这个y.backward(v)为什么要套一个v?(还是没懂)
解答:其实就是给每一项添加了一个系数,不加的话默认为相同size的1。
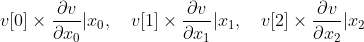
初步构建CNN神经网络
记录下代码,有点地方还不是很懂。比如CNN各层的传输参数,完整的前向、反向传播。
import torch
import torch.optim as optim # 优化器
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
# out_size = (in_size - Kernel+2Padding)/Stripe + 1
def __init__(self):
'''输入四位张量[N, C, W, H]'''
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1,6,3) # 卷积层1,in_channel=1,out_channel=6,kernel_size=3*3
self.conv2 = nn.Conv2d(6,16,3) # 卷积层2
# 三层全连接网络,y = Wx + b
self.fc1 = nn.Linear(16*6*6, 120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10) # 10分类
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))
x = F.max_pool2d(F.relu(self.conv2(x)),2)
x = x.view(-1, self.num_flat_feature(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_feature(self, x):
size = x.size()[1:] # 除batch维度外的所有维度
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
params = list(net.parameters())
'''图片输入'''
input = torch.randn(1,1,32,32)
out = net(input)
print(out)
'''梯度归零+反向传播'''
net.zero_grad()
out.backward(torch.randn(1,10))
'''loss function'''
target = torch.randn(10)
target = target.view(1,-1) # ≈reshape,-1表示不清楚行/列
criterion = nn.MSELoss()
loss = criterion(out, target)
print(loss)
'''SGD:weight = weight-learning_rate * gradient'''
optimizer = optim.SGD(net.parameters(), lr=0.01)
optimizer.zero_grad()
output = net(input)
loss = criterion(output, target)
optimizer.step() # 参数更新















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









