









《深度探索C++对象模型》学习笔记 — 构造函数语义学(The Semantics of Constructors)
第二章开篇就提到了,很多程序员抱怨C++编译器在背地里做了太多工作。那么我们提高使用编译器的效率的方式就是了解编译器到底做了哪些工作
一、不安全的转换
以前已经写过关于不安全转换的例子,这里放到一起总结一下
1、从类到基本类型的不安全转换
以前写过的基于Qt5.14.2和mingw的Qt源码学习(一) — Qt中的智能指针之QScopedPointer提到过SafeBool问题,就是这部分的例子。那么我们参考其发展历史,就可以知道包括提供将类对象转化为int、指针的弊端所在。
2、从基本类型到类的不安全转换
这种情况大部分出现在构造函数。使用单个参数的构造函数容易引起该问题。这也是为什么我们引入了explicit关键字。
二、默认构造函数
1、trivial 默认构造函数
在 C++ Annotated Reference (ARM) 中,对于构造函数的说法从需要时被创建变为如果没有用户定义的构造函数就会隐式声明一个trivial的构造函数。其含义并没有发生变化。针对下述代码:
class CLS_Test
{
int m_iMem;
double m_dbMem;
};
编译器对于这个类会生成一个trivial的构造函数。为何是trivial的呢?构造函数并不会对成员变量进行初始化(和临时变量一样,没有被初始化的值就是原来内存中的值)。对内置类型变量的赋值被认为是程序员所该负责的。
2、编译器创建non-trivial 默认构造函数的条件1 — 带有默认构造函数的 Member Class Object
(1)示例
class CLS_TestMem
{
public:
CLS_TestMem()
{
...
}
};
class CLS_Test
{
public:
int m_iMem;
CLS_TestMem m_clsTestMem;
};
int main()
{
CLS_Test test;
return 0;
}
这里由于CLS_Test类中的成员变量属于CLS_TestMem类型,而CLS_TestMem类型有一个显式声明的构造函数。因此编译器会为这个类声明一个non-trivial 默认构造函数,并在其中调用CLS_TestMem的构造函数初始化该成员变量。
(2)问题1:不同的编译模块在包含相同头文件时为包含的类声明多个构造函数怎么办?
解决方法是把构造函数声明成内联函数。我们知道普通函数的定义和原型是分开放在cpp和h文件中的,目的是防止我们把他们都写在头文件中,在不同的包含该头文件的编译单元中会给函数进行不同的链接。但是由于内联函数是静态连接的,所以没有这个限制。只要我们声明的内联函数定义都相同,就会被认为是同一个内联函数的同一份拷贝。
(3)问题2:已有显式声明的构造函数如何插入必要的初始化代码?
编译器保证在执行用户定义的构造函数构造体之前会执行必要的初始化代码。
#include <iostream>
class CLS_TestMem
{
public:
CLS_TestMem()
{
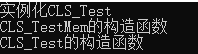
std::cout << "CLS_TestMem的构造函数" << std::endl;
}
};
class CLS_Test
{
public:
CLS_TestMem m_clstTestMem;
CLS_Test()
{
std::cout << "CLS_Test的构造函数" << std::endl;
}
};
int main()
{
std::cout << "实例化CLS_Test" << std::endl;
CLS_Test clsTest;
return 0;
}
(4)问题3:多个member class object初始化的顺序是怎样的?
按照它们在类中声明的顺序进行初始化。
#include <iostream>
class CLS_TestMem1
{
public:
CLS_TestMem1()
{
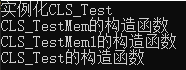
std::cout << "CLS_TestMem1的构造函数" << std::endl;
}
};
class CLS_TestMem
{
public:
CLS_TestMem()
{
std::cout << "CLS_TestMem的构造函数" << std::endl;
}
};
class CLS_Test
{
public:
CLS_TestMem m_clstTestMem;
CLS_TestMem1 m_clstTestMem1;
CLS_Test()
{
std::cout << "CLS_Test的构造函数" << std::endl;
}
};
int main()
{
std::cout << "实例化CLS_Test" << std::endl;
CLS_Test clsTest;
return 0;
}
3、编译器创建non-trivial 默认构造函数的条件2 — 带有默认构造函数的基类
#include <iostream>
class CLS_Base
{
public:
CLS_Base()
{
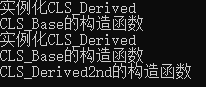
std::cout << "CLS_Base的构造函数" << std::endl;
}
};
class CLS_Derived : public CLS_Base
{
int m_iMem;
};
class CLS_Derived2nd : public CLS_Base
{
public:
CLS_Derived2nd()
{
std::cout << "CLS_Derived2nd的构造函数" << std::endl;
}
};
int main()
{
std::cout << "实例化CLS_Derived" << std::endl;
CLS_Derived clsDerived;
std::cout << "实例化CLS_Derived" << std::endl;
CLS_Derived2nd clsDerived2nd;
return 0;
}
4、编译器创建non-trivial 默认构造函数的条件3 — 带有虚函数的类
我们知道C++的多态有很大一部分是借助于vtable所实现。那么vtable的生成及vptr的绑定是由编译器所完成的。因此对于包含虚函数的类,编译器需要生成默认构造函数以完成上述操作。
5、编译器创建non-trivial 默认构造函数的条件4 — 虚基承于父类的类
这部分类似vtable。为了防止菱形拷贝,C++中提供了虚继承的技术。为了防止菱形继承中顶部类中的数据或方法被底部类保存多份,C++中同时提供了base class table和bptr来进行搜索其基类数据。因此这个指针的初始化就需要编译器生成默认构造函数来完成。
三、拷贝构造函数
1、拷贝构造函数的调用时间
(1)将一个Object赋值给另一个Object
(2)值传递方式调用函数
(3)返回一个非引用类型的Object
#include <iostream>
using namespace std;
class CLS_Test
{
public:
CLS_Test()
{
}
CLS_Test(CLS_Test& test)
{
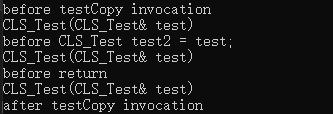
cout << "CLS_Test(CLS_Test& test)" << endl;
}
};
CLS_Test testCopy(CLS_Test test)
{
cout << "before CLS_Test test2 = test;" << endl;
CLS_Test test2 = test;
cout << "before return" << endl;
return test2;
}
int main()
{
CLS_Test test1;
cout << "before testCopy invocation" << endl;
testCopy(test1);
cout << "after testCopy invocation" << endl;
return 0;
}
2、Bitwise Copy Semantics
当我们没有显式地声明拷贝构造函数的时候, 上述拷贝过程是以递归形式的位逐次拷贝进行的。将所由基本类型的变量直接复制给新的Object对应的变量,对于Class Member再对其进行递归的位逐次拷贝直至完成整个赋值过程。在这种情况下,大部分编译器不会再为对应的类生成默认的拷贝构造函数。
#include <iostream>
using namespace std;
class CLS_Test
{
public:
CLS_Test()
{
m_strMem = "123";
m_iMem = 5;
}
int m_iMem;
string m_strMem;
};
int main()
{
CLS_Test test;
CLS_Test testCopy = test;
cout << "test.m_iMem = " << test.m_iMem << " \t test.m_strMem = " << test.m_strMem << " \t\t (ptrdiff_t)test.m_strMem.c_str() = " << (ptrdiff_t)test.m_strMem.c_str() << endl;
cout << "testCopy.m_iMem = " << testCopy.m_iMem << " \t testCopy.m_strMem = " << testCopy.m_strMem << " \t (ptrdiff_t)testCopy.m_strMem.c_str() = " << (ptrdiff_t)testCopy.m_strMem.c_str() << endl;
return 0;
}

当然这里由于string类实现了拷贝构造函数,使用浅拷贝方式防止了指针在有引用计数时被释放,所以即使前面的对象貌似被释放了,后面的对象也可以正常使用该对象。然而如果是我们自己声明的指针变量可能会导致释放后调用的异常问题。
#include <iostream>
using namespace std;
class CLS_Test
{
public:
CLS_Test()
{
m_strMem = "123";
m_iMem = 5;
m_pcMem = new char[5]{ "123" };
}
~CLS_Test()
{
delete m_pcMem;
}
int m_iMem;
string m_strMem;
char* m_pcMem;
};
int main()
{
CLS_Test *testCopy;
{
CLS_Test test;
testCopy = new CLS_Test{ test };
cout << test.m_pcMem << endl;
}
cout << (ptrdiff_t)testCopy->m_strMem.c_str() << endl;
cout << testCopy->m_pcMem << endl;
return 0;
}

3、编译器创建默认拷贝构造函数的条件
情况和上述 non-trivial构造函数的生成条件类似:
带有拷贝构造函数的 Member Class Object
带有拷贝构造函数的基类
声明虚函数
虚基承于父类
前面两种情况和前面的理由类似,这里主要讨论下后两种情况。
(1)声明虚函数
前面我们讨论过vtable和vptr需要由编译器初始化,但是我们要注意,vtable是属于类而非对象的。因此对于声明了虚函数的类对象进行位逐次拷贝是安全的。那么我们为何要生成拷贝构造函数呢?用于父子类对象的拷贝构造。
#include <iostream>
using namespace std;
class CLS_Base
{
public:
virtual void testBase()
{
cout << "CLS_Base::testBase" << endl;
}
};
class CLS_Derived : public CLS_Base
{
public:
virtual void testBase()
{
cout << "CLS_Derived::testBase" << endl;
}
};
void test(CLS_Base baseObject)
{
baseObject.testBase();
}
int main()
{
CLS_Derived derived;
test(derived);
return 0;
}
在上面的例子中,像我们前面提到的,调用test方法时,会先调用CLS_Base的某种默认拷贝方式将derived的内容拷贝到临时对象中。如果这时执行的是位逐次拷贝,那么当派生类的大小比基类大时(在大多数情况下也确是如此),会发生截断操作;同时,拷贝时将vptr一并拷贝。当调用base对象的虚函数时,通过虚表找到的实际上是传进来的派生类的vtable,其行为实则和我们预期的是不一样的。
在这种情况下,编译器需要提供默认的拷贝构造函数执行正确的vptr拷贝。
(2)虚继承于父类
和上面的讨论类似,当同类对象之间进行赋值和初始化时,位逐次拷贝可以满足我们的要求。但是在父子类对象之间执行拷贝时需要由编译器确保相应的变量能够被正确的调用到。
#include <iostream>
using namespace std;
class CLS_Base
{
public:
int m_iTest;
};
class CLS_VirtualDerived : virtual public CLS_Base
{
};
class CLS_Derived : public CLS_VirtualDerived
{
};
void test(CLS_VirtualDerived virtualDerivedObject)
{
cout << "virtualDerivedObject.m_iTest = " << virtualDerivedObject.m_iTest << endl;
}
int main()
{
CLS_Derived derived;
test(derived);
return 0;
}
在编译器对代码进行编译之后,test方法中类成员的访问已经变成了由bptr执行的访问。
有可能如下:
((int*)(((int*)&virtualDerivedObject)[i]))[j]
这里的 ((int)&virtualDerivedObject)[i] 是为了找到bptr。然而如果我们在调用test方法时执行了位逐次拷贝,这里的virtualDerivedObject变成了截断的derived对象。由于bptr可能是存在对象内存末端的,那么可能就被删除了;即使没有被删除,二者的bptr也未必在同样的偏移量上;即使二者在同样的偏移量上,对于derived对象的bptr来说,访问CLS_VirtualDerived类对象的成员需要两倍于virtualDerivedObject对象的bptr到CLS_VirtualDerived类对象寻址次数。
在这种情况下,编译器需要提供默认的拷贝构造函数执行正确的bptr拷贝。
(3)问题:当位逐次拷贝能满足拷贝构造的需求时,是否应该抑制拷贝构造函数的调用?因为凡是函数调用,必会消耗一部分性能。
(4)安全的使用拷贝构造函数
我们现在知道了拷贝构造函数都需要做什么。呈现良好位拷贝行为的类当然不需要我们再提供拷贝构造函数。如果要为类提供拷贝构造函数,我们要安全合理地初始化数据。
#include "time.h"
#include <iostream>
using namespace std;
class CLS_Test
{
public:
double array[100];
CLS_Test()
{
memset(array, 0, sizeof(double) * 100);
}
CLS_Test(const CLS_Test& t)
{
memset(this, 0, sizeof(CLS_Test));
}
virtual void test()
{
cout << "test";
}
};
int main()
{
CLS_Test first;
CLS_Test test(first);
CLS_Test* pTest = &test;
pTest->test();
}
程序发生错误,因为我们把vptr置空了.
四、程序转化
上面我们讨论了拷贝构造函数其作用的条件。不难发现,在作为函数入参和返回值时,对于过于庞大的类对象来说,执行一次拷贝构造函数实在是浪费时间。因此,对于入参,从程序员的角度我们使用引用传参的方式,通过const变量控制是否可修改,减少了这种拷贝函数调用的性能浪费。
1、函数参数的初始化方式
上述我们所说的优化入参拷贝函数调用的方式是建立在后期的函数参数初始化方式上,也就是将咱们的形参直接以拷贝构造实参的方式放置在函数入参的堆栈中。我们使用引用传参实际把参数的地址以函数的形参方式传递过去。todo
早期的C++编译器所使用的初始化方式是在当前运行堆栈中构建临时变量,再让函数到当前堆栈中取出对应变量。
对于下面的代码:
class CLS_Test
{
}
void foo(CLS_Test test);
int main()
{
CLS_Test test;
foo(test);
}
它将被转化为:
CLS_Test test;
CLS_Test __temp;
__temp.CLS_Test::CLS_Test(test); // copy constructor
foo(__temp);
相应的,此时函数的声明也需要由编译器修改为引用的调用。因为这里 __temp 是可以被改变的。
这就是我们引入了”拷贝构建“的传参方式的原因。
那么对于返回值我们该如何优化呢?
2、返回值的初始化
还是先列举早期的返回值初始化方式:
class CLS_Test
{
};
CLS_Test foo()
{
CLS_Test test;
...
return test;
}
int main()
{
CLS_Test test = foo();
}
这部分代码将被转化为:
void foo(CLS_Test &__result)
{
CLS_Test test;
test.CLS_Test::CLS_Test()
...
__result.CLS_Test::CLS_Test(test);
return;
}
int main()
{
CLS_Test test;
foo(test);
}
一方面,这样的拷贝浪费效率;同时,对于编译器能否正确的转化我们的函数调用也是一个考验。如下:
foo().memberFunc();
// transformation
CLS_Test __Temp;
(foo(__Temp), __Temp).memberFunc();
下面我们从两个层次来讨论优化效率的方案:
(1)从使用者层面优化
一句话概括就是定义计算用Constructor。
修改一下上面我们的foo函数:
template <typename T1, typename T2>
CLS_Test foo(T1 _t1Para, T2 _t2Para)
{
CLS_Test test;
... // dispose test with _t1Para and _t2Para
return test;
}
这样的模板函数可以被优化为:
CLS_Test foo(T1 _t1Para, T2 _t2Para)
{
return CLS_Test(_t1Para, _t2Para);
}
// transformation
foo(CLS_Test& test, T1 _t1Para, T2 _t2Para)
{
test(_t1Para, _t2Para);
return;
}
函数的构造只执行了一次带参构造,确实进行了一定的优化,而且把转化封装到了类内实现。但是很明显,对于模板函数不同的输入类型,我们要提供很多种构造函数。
(2)在编译器层面做优化
在我们开头所提及的早期的编译器对函数返回值的初始化的基础上,编译器是有能力进行优化的。以引用的返回对象名(result)取代被返回的对象名(test)进行操作。
void foo(CLS_Test &__result)
{
CLS_Test test;
test.CLS_Test::CLS_Test()
...
__result.CLS_Test::CLS_Test(test);
return;
}
// optimization
void foo(CLS_Test &__result)
{
__result.CLS_Test::CLS_Test();
...
return;
}
上述优化被称为NRV优化(named return value optimization)。
这里我们需要注意的是两点:
按照书中所说:NRV优化的条件是拷贝构造函数的存在。
那么可能会有这样的问题:在我们进行NRV优化时,并没有调用拷贝构造函数,为何一定需要呢?如果没有拷贝构造函数默认执行的是位逐次拷贝,本身就足够高效了,这可能是原因之一。然而这个条件存在与否也可能跟编译器的实现有关。例如我在下面列举的例子在vs下编译在没有拷贝构造函数的情况下也进行了NRV优化。
NRV优化虽然并不在标准编译器需求之内。虽然大部分编译器被要求进行此优化,但是真正优化与否存疑。
#include "time.h"
#include <iostream>
using namespace std;
class CLS_Test
{
public:
double array[100];
CLS_Test()
{
memset(array, 0, sizeof(double) * 100);
cout << "CLS_Test()";
}
/*inline CLS_Test(const CLS_Test& t)
{
memcpy(this, &t, sizeof(CLS_Test));
cout << "CLS_Test(const CLS_Test& t)";
}*/
};
CLS_Test foo()
{
CLS_Test test;
test.array[0] = 1.2;
test.array[99] = 1.2;
return test;
}
int main()
{
time_t tStart = clock();
for (int i = 0; i < 10000000; i++)
{
CLS_Test test = foo();
}
time_t tEnd = clock();
cout << "time = " << (tEnd - tStart) << endl;
}
这个例子和书中给出的类似,但是结果是截然不同的(IDE为 vs2019 community)。
该示例主要比较的是声明拷贝构造函数和不声明(及上面注释掉的情况)下运行10000000次返回类对象的函数。按照书中所说,其优化后的性能应该提升一倍。但是我这里并未得到相同的结论。
如果我们在开启优化前后以及声明拷贝构造函数前后对代码进行反汇编可以得到如下汇编代码:
// before optimization
CLS_Test foo()
{
009D58D0 push ebp
009D58D1 mov ebp,esp
009D58D3 sub esp,3A4h
009D58D9 mov eax,dword ptr [__security_cookie (09DC004h)]
009D58DE xor eax,ebp
009D58E0 mov dword ptr [ebp-4],eax
009D58E3 push ebx
009D58E4 push esi
009D58E5 push edi
009D58E6 mov ecx,offset _893702FA_AdvancedTest@cpp (09DF029h)
009D58EB call @__CheckForDebuggerJustMyCode@4 (09D1393h)
CLS_Test test;
009D58F0 lea ecx,[test]
009D58F6 call CLS_Test::CLS_Test (09D1389h)
test.array[0] = 1.2;
009D58FB mov eax,8
009D5900 imul ecx,eax,0
009D5903 movsd xmm0,mmword ptr [__real@3ff3333333333333 (09D9BD8h)]
009D590B movsd mmword ptr test[ecx],xmm0
test.array[99] = 1.2;
009D5914 mov eax,8
009D5919 imul ecx,eax,63h
009D591C movsd xmm0,mmword ptr [__real@3ff3333333333333 (09D9BD8h)]
009D5924 movsd mmword ptr test[ecx],xmm0
return test;
009D592D mov ecx,0C8h
009D5932 lea esi,[test]
009D5938 mov edi,dword ptr [ebp+8]
009D593B rep movs dword ptr es:[edi],dword ptr [esi]
009D593D mov eax,dword ptr [ebp+8]
}
// after optimization
CLS_Test foo()
{
001958D0 push ebp
001958D1 mov ebp,esp
001958D3 push esi
001958D4 mov ecx,offset _893702FA_AdvancedTest@cpp (019F029h)
001958D9 call @__CheckForDebuggerJustMyCode@4 (0191393h)
001958DE mov esi,dword ptr [ebp+8]
001958E1 mov ecx,esi
001958E3 call CLS_Test::CLS_Test (0191389h)
001958E8 movsd xmm0,mmword ptr [__real@3ff3333333333333 (0199BD8h)]
001958F0 mov eax,esi
001958F2 movsd mmword ptr [esi],xmm0
001958F6 movsd mmword ptr [esi+318h],xmm0
001958FE pop esi
CLS_Test test;
test.array[0] = 1.2;
test.array[99] = 1.2;
return test;
}
// after adding copy constructor
CLS_Test foo()
{
001958D0 push ebp
001958D1 mov ebp,esp
001958D3 push esi
001958D4 mov ecx,offset _893702FA_AdvancedTest@cpp (019F029h)
001958D9 call @__CheckForDebuggerJustMyCode@4 (0191393h)
001958DE mov esi,dword ptr [ebp+8]
001958E1 mov ecx,esi
001958E3 call CLS_Test::CLS_Test (0191389h)
001958E8 movsd xmm0,mmword ptr [__real@3ff3333333333333 (0199BD8h)]
001958F0 mov eax,esi
001958F2 movsd mmword ptr [esi],xmm0
001958F6 movsd mmword ptr [esi+318h],xmm0
001958FE pop esi
CLS_Test test;
test.array[0] = 1.2;
test.array[99] = 1.2;
return test;
}
之后我在centos使用 g++ (gcc version 8.3.1 20191121 (Red Hat 8.3.1-5) (GCC) ) 以及使用qt提供的mingw进行编译都未得到明显的在相同优化选项添加和删除拷贝构造函数的不同结果。
也许我们可以得出一个结论:拷贝构造函数已经不是NRV优化的必要条件了!
(3)NRV的优化的问题
书中提到,很多程序员不喜欢NRV优化。因为他们希望在他们的代码中可以对称的调用拷贝构造函数和析构函数。如果实施了NRV优化,二者就不是对称的了。因此作者提出:难道拷贝构造函数在经过拷贝完成初始化的情况下一定要被调用吗?
我个人觉得不是。首先,为什么这些程序员觉得二者是对称的,为什么他们认为返回对象时需要调用拷贝构造函数?因为他们知道编译器在这种条件下的行为。如果他们不知道以前的编译器是怎样处理返回值的,也就不可能希望编译器调用拷贝构造函数以执行他们安插其中的特定的代码。既然他们知道编译器的行为,他们就不应该做出这种对效率有影响的行为。因为我们了解程序是如何编译的,是为了让我们更有效率的编写代码,而不是利用编译器一些不足去实现我们的功能。再者说,可能某些版本的编译器还没优化这部分功能。那他们应该以条件编译或者适配器的方式去匹配不同的编译器优化。
五、成员初始化列表
1、成员初始化列表的作用
initialization — 成员初始化列表的作用就是初始化。什么是初始化?给变量分配空间。初始化的时候可以赋值,但是赋值不一定在初始化变量的时候。
#include <iostream>
using namespace std;
class CLS_TestMember
{
public:
CLS_TestMember()
{
cout << "CLS_TestMember()" << endl;
}
};
class CLS_Test
{
CLS_TestMember member;
public:
CLS_Test()
{
member = CLS_TestMember();
}
};
int main()
{
CLS_Test first;
}
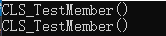
上述代码的赋值实则发生了两次。第一次就像我们前面所说的,编译器会在我们声明的构造函数体前调用class member object的构造函数。第二次才是我们以为的初始化(实则是赋值)。
class CLS_Test
{
CLS_TestMember member;
public:
CLS_Test():
member(CLS_TestMember())
{
}
};

这时我们使用初始化成员列表的优势就体现出来了。
2、成员初始化列表的初始化顺序
按照成员在类中声明的顺序初始化;基类成员的初始化发生在子类成员之前。
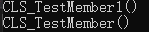
(1)编译器插入的初始化代码和成员列表的初始化哪个先执行?
我测试了一下,还是与我们的声明顺序保持一致。
class CLS_TestMember
{
public:
CLS_TestMember()
{
cout << "CLS_TestMember()" << endl;
}
};
class CLS_TestMember1
{
public:
CLS_TestMember1()
{
cout << "CLS_TestMember1()" << endl;
}
};
class CLS_Test
{
CLS_TestMember1 member1;
CLS_TestMember member;
public:
CLS_Test():
member(CLS_TestMember())
{
}
};
(2)良好的构造函数初始化习惯
在构造函数中,使用初始化列表初始化class member object,按照基类构造函数以及变量声明的殊顺序进行初始化。看个反例:
class CLS_Test
{
int i;
int j;
public:
CLS_Test():
j(10),
i(j++)
{
cout << "i =" << i << " j = " << j << endl;
}
};

3、成员列表初始化的时机
成员列表初始化保证在任何显式用户代码之前。
4、必须使用成员初始化列表的条件
初始化引用成员变量
初始化const成员变量
调用基类构造函数,而它拥有一组参数
调用class member object的构造函数,而它拥有一组参数
前两种条件是因为这两种类型的成员变量只能初始化而不能赋值;后两种条件是因为很多类的构造函数开放了一部分成员的初始化,而没有提供公有的set接口。因此我们必须通过初始化列表来初始化这些对象。否则编译器将调用默认构造函数。
5、问题
(1)初始化列表中能否使用成员函数初始化成员变量?
可以是可以,但是到底初始化了哪个变量就不一定了。
class CLS_TestMember
{
public:
CLS_TestMember()
{
cout << "CLS_TestMember()" << endl;
}
};
class CLS_TestMember1
{
public:
CLS_TestMember1()
{
cout << "CLS_TestMember1()" << endl;
}
};
class CLS_Test
{
CLS_TestMember member;
CLS_TestMember1 member1;
CLS_TestMember init()
{
member1 = CLS_TestMember1();
return CLS_TestMember();
}
public:
CLS_Test():
member(init())
{
}
};
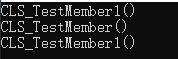
(2)this指针的初始化在什么时候发生?
一定是在初始化列表调用之前。因为我们知道类方法中成员变量和方法的调用前面都省略了this。如果this在初始化列表之后构建,那根本无从初始化这些变量。这部分可以通过反汇编跟踪源代码查看,这里不再列举。















 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









