






以下谈一点个人的看法
一、pandas的两种索引方式
众所周知,.loc,.iloc是两种常用的索引方式,分别是基于标签索引,基于位置索引。具体用法不再赘述。曾经还有一种混合索引.ix,可以“自由”地使用标签或位置进行索引。
二、为什么弃用.ix。
.ix方法看起来很爽,但是暗藏一个坑。举例:
d1={'城市':['北京','昆明','广州','武汉','沈阳'],
'一月销售额':[103.5,105,108.2,102.0,110],
'二月销售额':[120.4,125.6,120.2,140.9,108.4],
'三月销售额':[121.4,128.8,122.3,130.5,120.2]}
d=pd.DataFrame(d1,index=[2,4,6,8,10])
得到数据:
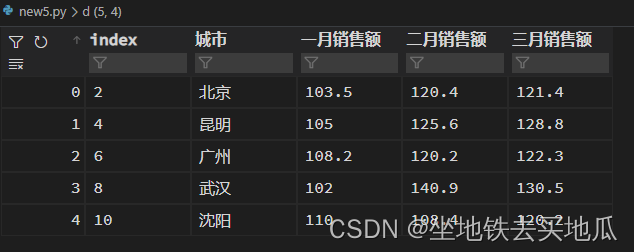
注意我在这里故意设置了一个不是0123序列的数字型index。实际操作中,这种现象非常常见。很多数据经过一番增删改查、各种拼接之后,index早已混乱不堪。
那么,d.ix[2,‘城市’]返回的什么?
你可能以为数字2代指第二行,但是,实际上程序理解的是标签2.所以你想得到“广州”,它返回的却是“北京”,与d.loc[2,‘城市’]效果完全相同。
所以.ix又有什么存在的意义呢?干脆就废弃了吧。
三、如何变通
1.使用loc,将index设置为0123序列
使用重置索引的方法将index设置为0123序列。
d.reset_index(drop=True,inplace=True)
print(d.loc[2,'城市'])
此时输出的就是“广州”。
drop=True表示原来的index废弃不用了。inplace=True表示直接修改原DataFrame对象。
2.使用iloc,用get_loc返回标签索引所在的位置
icity=d.columns.get_loc('城市')
print(d.iloc[2,icity])
此时输出的就是“广州”。















 2417
2417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









