







来自ACL2020

paper:SEEK: Segmented Embedding of Knowledge Graphs
code:https://github.com/Wentao-Xu/SEEK
本文提出一种轻量级的知识图谱嵌入框架SEEK
本文的贡献有两个:
1.提出了 轻量级框架SEEK,同时满足模型的低复杂性、高表达力
2.提出了新 打分函数,同时完成特征整合、关系留存
同时,此模型SEEK强调两个关键特性:
1.利用足够多的特征进行交叉计算(先分块)
2.同时在计算时,区别对称关系、非对称关系的特征
名字来源:Segmented Embedding for KGs (SEEK).
1.引言
知识图谱 (KG)含有大量的实体和关系,表示为三元组(h, r, t),即(头实体 , 关系, 尾实体)。图谱的嵌入(KGE)变成热点之一,对下游任务至关重要(如个性化推荐1、问答2 等)。图谱嵌入的目标是,把相关三元组映射到低维空间,同时保留潜在的语义信息。
现有的KGE模型存在的问题:不能很好地平衡模型复杂性(模型参数的数量)和模型表达力(获取语义信息的能力),如下分为两类:
- 模型简单、表达有限
如:TransE3、DistMult4(简单易用,获取语义信息的能力欠佳) - 模型复杂、表达力强
如:TransH5、TransR6、Single DistMult7、ConvE8、InteractE9 (模型复杂,需要大量向量计算,扩展性差)
本文的轻量级KGE框架SEEK有如下特性:特征有交互、保留关系特性、高效的打分函数
- 特征交互:把嵌入空间分为多块,让各块之间相互计算(而不用增加模型参数)
- 关系特性:同时保留对称的、非对称的关系(对称关系:双向关系;非对称关系:单向关系)
- 打分函数:结合上述两种特征,计算得分(灵感来自于3个模型的打分函数:DistMult、HoIE10、ComplEx11)
2.相关工作
现有KGE模型(1-2为一类,3-5为一类):
1.TransE3 :把关系r看作是一种从实体h到实体t的翻译
2.DistMult:用多维线性点积作为得分函数
3.TransH、TransD、 ITransF :TransE升级版,增加参数,将实体和关系映射到不同的语义空间
4.Single DistMult:加大了DistMult嵌入维度的大小
5.ProjE12 , ConvE,InteractE:采用神经网络,参数很多

3.SEEK的框架
各种打分函数是KGE(knowledge graph embedding)的基础,基于此我们建立了SEEK
本文提出的SEEK模型的参数和TransE、DistMult一样少,却能更好地表达图谱
3.1打分函数(四种)
一共四种打分函数,逐步进阶
⭐ f1 :点积 (早期方法,过于简单)
r关系,h头实体,t尾实体,第 i 维
⭐ f2 : 分块点积(整合了不同分块之间的特征,但把关系统一认为是对称的关系)
将h,t,r都分为k块,每一块的维度是d/k,比如r:
⭐ f3 : 区分对称/非对称关系,复杂度O(k2d)
奇——非对称关系;偶——对称关系
当k=2时,f3的计算方式如图:
(当r为偶,代表对称关系,系数都为正;r为奇数,代表非对称关系,系数取决于是否x + y ≥ k)

缺点:1.数据驱动型方法 2.计算量大, 一个三元组k3次点积运算,时间复杂度O(k3d/k) =O(kd)
⭐ f4 : 减少多余计算量,复杂度O(kd)
引入尾实体 t 的索引向量Wij
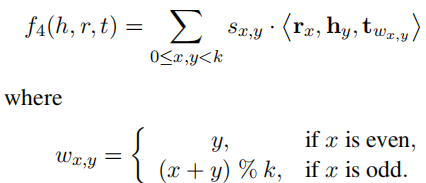
f4只需k2次点积,则复杂度为y O(k2×d/k) = O(kd)
当k=4时,f4计算如下:

f4的特性:1.超参数k,决定计算复杂度,一般k=4或k=8 2.同时考虑对称/非对称关系 3. 不同分块之间维度可以不同
3.2讨论
复杂度分析
时间复杂度:O(kd)
空间复杂度:O(d)
与其他方法比较
SEEK普适性更强,传统模型如DistMult、ComplEx、HolE等
可以推导,当k = 1 和 k = 2时,以上模型是SEEK的特例
Proposition 1 SEEK (k = 1) 等同于DistMult
Proposition 2 SEEK (k = 2) 等同于ComplEx 和 HolE
3.3训练
损失函数为-log函数,L2正则化,激活函数sigmoid
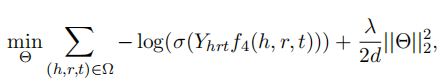
Θ:向量嵌入时的参数
Ω:图谱中本来的三元组、生成的负样本三元组
梯度的计算公式:
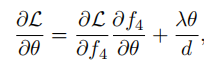
L目标函数,Θ参数,对f4求导时:
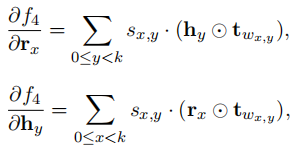
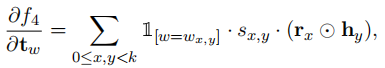
4.实验
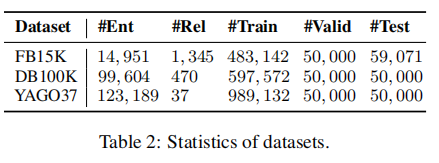
数据集
FB15K:数据库Freebase的子集
DB100K:DBpedia的一些核心映射
YAGO37:YAGO3的一些核心事实
参数
优化:SGD / AdaGrad
找超参数: grid search方法
分块个数k:k ∈ {1, 2, 4, 8, 16, 20}
嵌入维度D:D ∈ {100, 200, 300, 400}
L2正则系数:λ ∈ {0.1, 0.01, 0.001, 0.0001}
负样本个数:η ∈ {10, 50, 100, 500, 1000}
最优参数:
- FB15K:k = 8, D = 400, λ = 0.001, η = 1000
- DB100K:k = 4, D = 400, λ = 0.01, η = 100
- YAGO37:k = 4, D = 400, λ = 0.001, η = 200
对比实验
面对连接预测任务,在不同数据集上的效果如下:
相比于SEEK,用f2函数,得到Sym-SEEK框架


k的取值
在数据集FB15K上,k的不同取值对时间、MRR的影响:

由上图可知,k的取值至关重要。k=8时,性能最佳。而运行时间是线性变化的,符合之前的推论,即线性复杂度为O(kd) 。
个例说明
通过某一些个例,来证明模型SEEK的表达能力。在数据集DB100K上,使用打分函数f1、f2、f4后,通过激活函数sigmoid函数,分别得到概率值P1、P2、P4,如下图:

上述三元组中,左边为对称关系,右边为非对称关系。前者的相反关系在测试集为正,P1、P2、P4的值依然较高;而后者的相反关系在测试集为负,却只有概率P4较低。原因是,f1、f2不考虑非对称关系,而f4考虑,故得到一个很低的概率值P4,表示反转后的关系与原始关系有较大不同。和预设的模型表达力一致。
5.总结
本文提出一个轻量级框架SEEK,利用打分函数,在不增加模型参数的情况下,提高了模型对知识图谱的嵌入表示效果。主要原理是:1.分块并利用不同块之间的特征交叉计算 2.区分并保留多种关系 。同时SEEK是一个普适性更强的模型,DistMult, ComplEx, HolE可作为SEEK的特例。本文从效率、效果、鲁棒性方面阐述了SEEK的性能。
6.参考文献
(主要的参考文献)
Hongwei Wang, Fuzheng Zhang, Xing Xie, and Minyi Guo. 2018. Dkn: Deep knowledge-aware network for news recommendation. In Proceedings of WWW, pages 1835–1844. ↩︎
Xiao Huang, Jingyuan Zhang, Dingcheng Li, and Ping Li. 2019. Knowledge graph embedding based question answering. In Proceedings of WSDM, pages 105–113. ↩︎
Antoine Bordes, Nicolas Usunier, Alberto Garcia Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi relational data. In Proceedings of NIPS, pages 2787– 2795. ↩︎ ↩︎
Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. 2015. Embedding entities and relations for learning and inference in knowledge bases. In Proceedings of ICLR. ↩︎
Zhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng Chen. 2014. Knowledge graph embedding by translating on hyperplanes. In Proceedings of AAAI, pages 1112–1119. ↩︎
Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of AAAI, pages 2181–2187. ↩︎
Rudolf Kadlec, Ondrej Bajgar, and Jan Kleindienst. 2017. Knowledge base completion: Baselines strike back. arXiv preprint arXiv:1705.10744. ↩︎
Tim Dettmers, Minervini Pasquale, Stenetorp Pontus, and Sebastian Riedel. 2018. Convolutional 2d knowledge graph embeddings. In Proceedings of AAAI, pages 1811–1818. ↩︎
Shikhar Vashishth, Soumya Sanyal, Vikram Nitin,
Nilesh Agrawal, and Partha Talukdar. 2019. Interacte: Improving convolution-based knowledge graph embeddings by increasing feature interactions. arXiv preprint arXiv:1911.00219. ↩︎Maximilian Nickel, Lorenzo Rosasco, Tomaso A Poggio, et al. 2016. Holographic embeddings of knowledge graphs. In Proceedings of AAAI, pages 1955–1961. ↩︎
Theo Trouillon, Johannes Welbl, Sebastian Riedel, ´ Eric ´Gaussier, and Guillaume Bouchard. 2016. Complex embeddings for simple link prediction. In Proceedings of ICML, pages 2071–2080. ↩︎
Baoxu Shi and Tim Weninger. 2017. Proje: Embedding projection for knowledge graph completion. In Proceedings of AAAI, pages 1236–1242. ↩︎















 534
534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









