







Chapter 1 介绍
Chapter 2 基础知识
数据
数据集(data set)、样本(sample)、特征(feature)[如身高、体重等]、标记(label)、特征空间(feature space)[各个特征组成的空间]

监督学习
给机器的训练数据有标记
分类:二分类、多分类
回归:结果是一个连续数字的值
无监督学习
给机器的训练数据没有标记
对数据进行降维、特征提取[信用评级与体重无关?]、特征压缩[PCA]、异常检测
聚类:对没有标记的数据进行分类
半监督学习
一部分数据有标记,另一部分数据没有
通常先使用无监督学习手段对数据处理,之后使用监督学习手段做模型训练和预测
增强学习
根据周围环境的情况采取行动,根据采取行动的结果学习行动方式

批量学习
简单、但不能适应环境变化
在线学习
及时反映环境变化、但新数据有可能带来不好的变化
参数学习
一旦学习到参数,就不再需要原有数据集
非参数学习
不对模型进行过多假设(建模)
Chapter 3 Jupyter Notebook使用
魔法命令
%run
%timeit、%%timeit
%time、%%time
numpy.array基础
argmin最小元素的索引
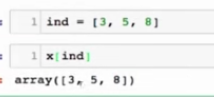
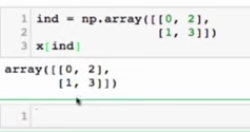
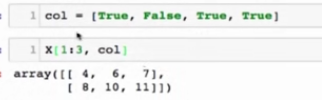
FancyIndexing

Chapter 4 kNN算法
算法—>模型的过程:拟合(fit)

判断算法性能
train_test_split

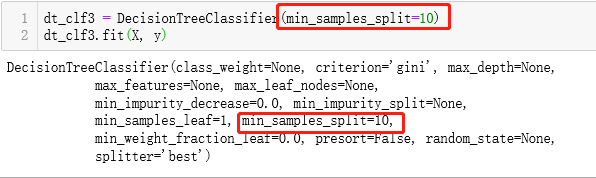
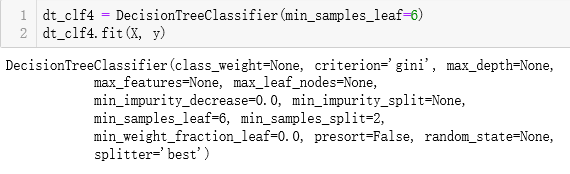
超参数
超参数:运行算法之前需要指定的参数
模型参数:算法过程中学习的参数

明可夫斯基距离:
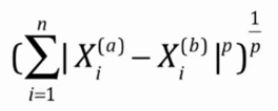
kNN的超参数:k, p, method
网格搜索

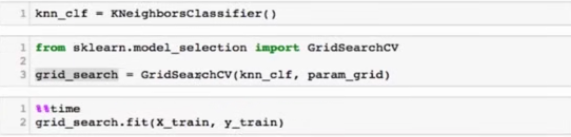


数据归一化
将所有数据映射到同一尺度


S是特征值的方差
总结
解决分类问题、缺点效率低、高度数据相关、预测结果不具有可解释性、维度灾难

Chapter 5 线性回归算法
· 解决回归问题
· 结果具有很好的可解释性
简单线性回归
 目标:找到a和b,使得Σ(y(i)-ax(i)-b)2尽可能小
目标:找到a和b,使得Σ(y(i)-ax(i)-b)2尽可能小
使损失函数尽可能小和效用函数尽可能大


向量化运算


回归算法的评价



R Squared




R方其实是对比我们的模型和Baseline之间的差距

多元线性回归




正规方程解
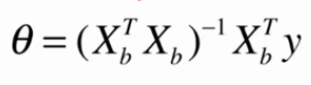
时间复杂度过高O(n3)

关于线性回归模型的思考
可解释性:得到的系数表明目标与特征的正负相关性

梯度下降法


太小,收敛速度太慢;太大,不收敛甚至发散


多元线性回归中的梯度下降



向量化


使用梯度下降前进行归一化


随机梯度下降



关于梯度的调试
导数近似:

小结
小批量梯度下降法: 结合批量梯度下降法和随机梯度下降法
随机: 跳出局部最优解、速度快
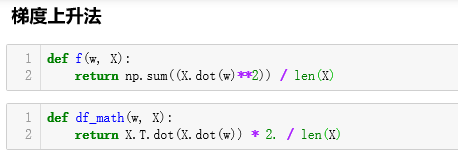
梯度上升: 求最大值
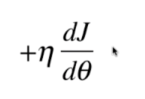
Chapter 7 PCA

找到样本间间距最大的轴
样本间间距——方差:描述样本每一个变量与整体均值之间的差距
方差越大,样本越稀疏
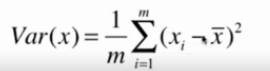
主成分分析: 找到一个轴,使得样本空间的所有点映射到这个轴后,方差最大



梯度上升法解决主成分分析

向量化

第一主成分


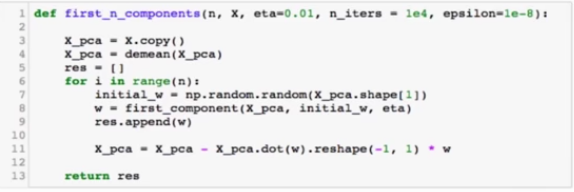
求数据的前n个主成分
求出第一主成分后,如何求出下一个主成分?
数据进行改变,将数据在第一个主成分上的分量去掉

在新的数据上求第一主成分


高维数据向低维数据映射

sklearn中的PCA

数据降噪
Chapter8 多项式回归与模型泛化
多项式回归的基本思想
思路:与PCA相反,通过升高维度更好地拟合高维度数据
数据:

一维拟合:

升维:
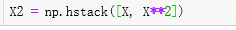


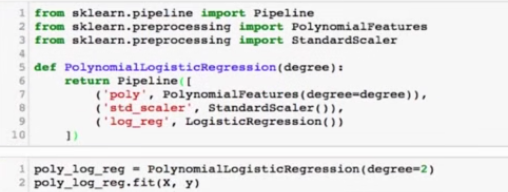
sklearn中的多项式回归
生成数据:





Pipeline

过拟合和欠拟合

学习曲线



验证数据集与交叉验证







偏差方差权衡

模型误差=偏差+方差+不可避免的误差
导致偏差的主要原因:对问题本身的假设不正确,如非现行数据使用线性回归,欠拟合是导致偏差的主要原因
导致方差的主要原因:通常是使用的模型太复杂,如高阶多项式回归,数据的一点点扰动都会较大地影响模型,没有学习到问题的实质,学习到了过多的噪音,过拟合会极大地引入方差

偏差和方差通常是矛盾的,降低偏差就会提高方差;降低方差会提高方差

模型泛化与岭回归
模型正则化:限制参数的大小

称为岭回归

LASSO回归



L1, L2和弹性网络
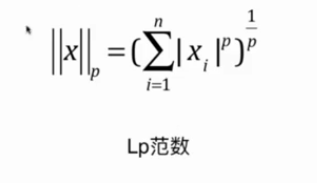

L0:正则项:非0θ元素的个数

Chapter 9 逻辑回归
解决分类问题:将样本特征和样本发生的概率联系起来,概率是一个数


sigmoid函数
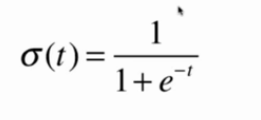
值域(0, 1):t>0时,p>0.5;t<0时,p<0.5
逻辑回归的损失函数

惩罚函数:
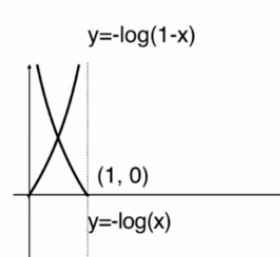
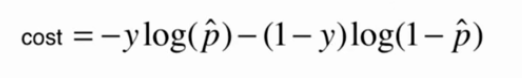
逻辑回归的损失函数:

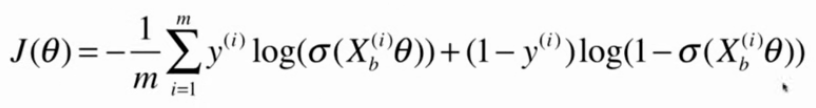

决策边界


使用多项式特征

sklearn中的逻辑回归





OvR&OvO
逻辑回归只能解决二分类问题,解决多分类问题:OnevRest&OvO

n个类别进行n次分类,选择分类得分最高的

n个类别进行C(n, 2)次分类,选择赢数最高的分类
OvO:



Chapter 10 评价分类结果
准确度陷阱和混淆矩阵
分类准确度的问题:对于极度偏斜的数据,只用分类准确度是远远不够的

精准率和召回率

做了100次分类为1的预测,有几次是准确的
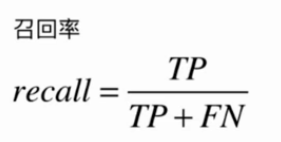
实际上有100次关注事件发生,有几次是准确的

例

精准率:预测8个人有癌症,预测中有8/(8+12)是准确的
预测数据为1,预测对了的概率;即预测癌症预测的成功率;每做100次患病的预测,会有40次是对的
召回率:实际有10个癌症病人,预算算法能从中正确的挑出8/(8+2)
真实发生的事件中,成功预测的概率;实际有100个癌症患者,能成功找出80个


注重精准率,如股票预测
注重召回率,如病情诊断
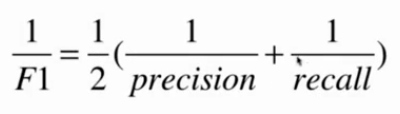
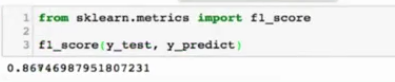
F1 Score
精准率和召回率的调和平均值
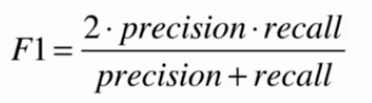
Precision-Recall的平衡


Precision-Recall曲线




红圈处可能表示精确率召回率达到平衡的点
ROC曲线
Receiver Operation Characteristic Curve,描述TPR和FPR之间的关系
True Positive Rate = Recall = TP / (TP + FN)
预测为1,并且预测对的数量占真实值为1的百分比
False Positive Rate = FP / (TN + FP)
预测为1,预测错了的数量占真实值为0和真实值不为1的百分比
TPR和FPR的关系


ROC曲线观察模型正确地识别正例的比例与模型错误地把负例数据识别成正例的比例之间的权衡。TPR的增加以FPR的增加为代价。ROC曲线下的面积(AUC)是模型准确率的度量。
多分类问题中的混淆矩阵
Chapter 11 支撑向量机
不适定问题:决策边界不唯一的问题

解决的是线性可分问题
【思想】将问题转化成最优化问题,进一步解决
最大化margin–>最大化d





有条件的最优化问题
Soft Margin和SVM正则化


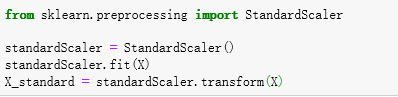
使用SVM之前,数据要做标准化处理
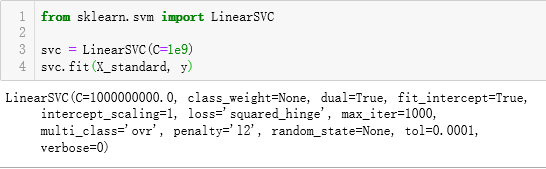
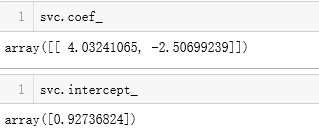
SVM中使用多项式特征
生成数据



使用多项式核函数的SVM

核函数
K(x, y)表示x和y的点乘
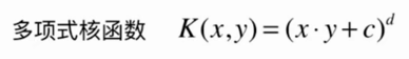
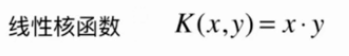
高斯核函数
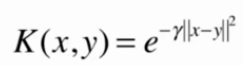
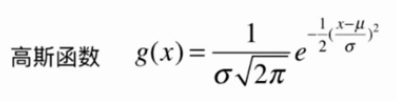

将每一个样本点映射到一个无穷维的特征空间


sklearn中的RBF核

与高斯函数中的6(yita)参数相反

γ=1.0

γ=100.0

γ越低,模型越倾向于欠拟合;γ越高,模型越倾向于过拟合
SVM思路解决回归问题
margin范围内的数据点越多越好(与解决分类问题相反)

Chapter 12 决策树


非参数学习算法,可以解决分类问题,天然可以解决多分类问题,也可以解决回归问题,非常好的可解释性
问题:每个节点在哪个维度做划分;某个维度在哪个值上做划分
信息熵
熵在信息论中代表随机变量不确定度的度量

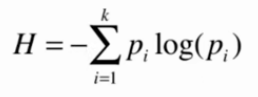
pi代表k类信息中第i类所占比例,H>0
划分要使得信息熵降低
使用信息熵寻找最优划分


基尼系数
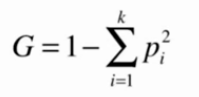
基尼系数越大,不确定性越大;基尼系数越小,不确定性越小



信息熵vs基尼系数
信息熵计算比基尼系数稍慢
sklearn中默认为基尼系数
大多数时候二者没有特别的效果优劣
CART
Classification And Regression Tree,根据某一个维度d和某一个阈值v进行二分

剪枝:降低复杂度,解决过拟合





决策树解决回归问题

决策树的局限性
决策边界是与X轴Y轴平行的

对个别数据敏感


非参数学习的缺点:普遍依赖于调参
Chapter 13 集成学习和随机森林
集成学习
集成多个算法,让不同算法对同一组数据进行分析得到结果,最终投票决定公认的最好结果

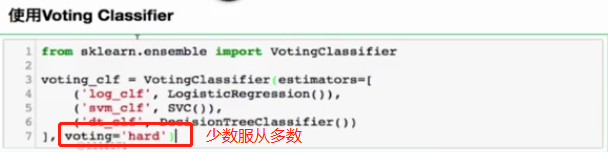

Soft Voting Classifier

要求集合的每一个模型都能估计概率




Bagging和Pasting
如何创建差异性:每个子模型只看样本数据的一部分
取样:放回取样Bagging(常用);不放回取样Pasting
以n_samples=500,noise=0.3, random_state=42的make_moon数据为例:

关于Bagging的讨论
Out-of-Bag



极易进行并行化处理


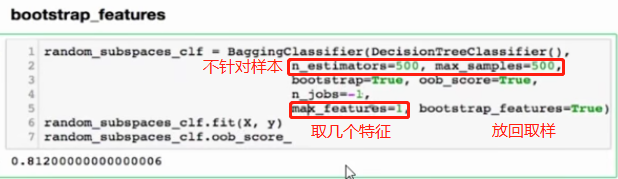
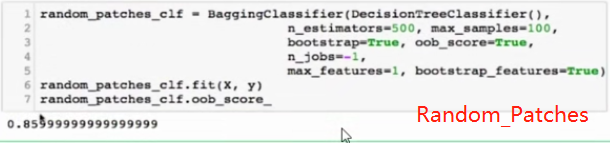
随机森林和Extra-Trees
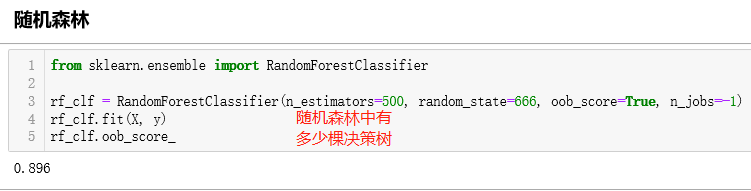
随机森林


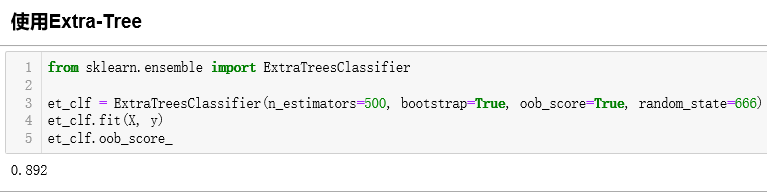
Extra-Trees

Boosting
集成多个模型
每个模型都在尝试增强整体的效果
1.Ada Boosting

每次生成的子模型都在弥补上一次生成模型没有成功预测的样本点

2.Gradient Boosting



Stacking


















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









