







Python 是一种流行的编程语言,也是数据科学界最受欢迎的语言。由于 Python 的动态性和多功能性,与其他流行编程语言相比,Python 的速度主要较慢,C语言的执行比 Python 代码快10到100倍。
在本文中,我们将讨论如何多模块并行执行自定义Python函数,并进行性能比较。
Multiprocessing
数据探索、数据分析和特征工程是数据科学模型开发的重要元素。在将原始数据输入机器学习模型之前,需要对其进行设计和处理。对于小尺寸的数据集,执行过程在几秒钟内完成,但是对于大尺寸的数据集,执行过程将变得非常繁琐。
如果单核处理器同时分配多个任务,它必须不断地中断每个任务并切换到一个任务来保持所有进程的运行。对于多核处理器来说,可以在 CPU 的不同核上同时执行多个任务,这个概念称为并行处理。
并行处理是提高 Python 程序性能的有效途径。Python 有一个多处理模块,使我们能够在CPU的不同内核上并行执行程序。
实施
我们将使用 multiprocessing 模块中的 Pool 类,它可以针对多个输入值并行执行函数。
现在,让我们使用 multiprocessing 模块中的 Pool 类为数据集的不同块并行执行函数。数据集的每个块都将被并行处理。
import multiprocessing
from functools import partial
from QuoraTextPreprocessing import preprocess
BUCKET_SIZE = 50000
def run_process(df, start):
df = df[start:start+BUCKET_SIZE]
print(start, "to ",start+BUCKET_SIZE)
temp = df["question"].apply(preprocess)
chunks = [x for x in range(0,df.shape[0], BUCKET_SIZE)]
pool = multiprocessing.Pool()
func = partial(run_process, df)
temp = pool.map(func,chunks)
pool.close()
pool.join()
数据集有 537361 条需要处理的记录或文本问题。对于大小为 50000 的 BUCKET_SIZE,数据集被划分为11个较小的数据块,这些数据块可以并行处理,以加快程序的执行时间。
数据对比
我比较了数据并行性和一次对整个数据集执行后运行时间。
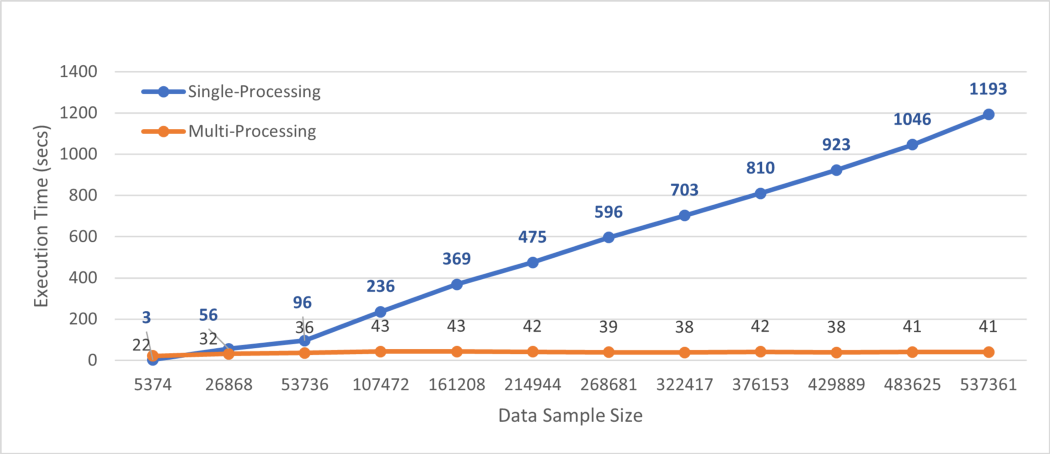
从上面的图中,我们可以看到 Python 的并行处理,将执行速度提高了近30倍。
总结
本文讨论了Python中多处理模块的实现,该模块可以用于加速 Python 的执行。添加几行代码,对于具有537k实例的数据集,执行时间几乎是30倍。
对于处理大型数据集,建议使用并行处理,因为它可以节省了大量时间。
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友超过2000人,添加方式如下:
如下方式均可,添加时最好方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式一、发送如下图片至微信,进行长按识别,回复加群;
- 方式二、直接添加小助手微信号:pythoner666,备注:来自CSDN
- 方式三、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

















 793
793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









