







提起李宏毅老师,熟悉机器学习的读者朋友一定不会陌生。最典型的就是开局一言不合就“宝可梦”。李宏毅老师幽默风趣的教学风格也吸引力很多机器学习爱好者。
李宏毅老师,是宝岛台湾大学电机工程系教授,他分别于2010年和2012年获得硕士和博士学位,主要研究机器学习尤其是深度学习、语言理解和语音识别。李宏毅老师的机器学习课程可以说是最具代表性的中文公开课之一,已经成为大量国内初学者的首选。
截至目前,2021年版的机器学习40节课程已经全部更新完毕,全程中文讲解,覆盖的内容也非常丰富,视频均长约40分钟,内容较多,喜欢的小伙伴先收藏、关注,慢慢学习!

今年李宏毅老师的课程视频会与时俱进,课程新增 Transformer、流模型和对抗攻击等新内容。去年的课程则对BERT、XLNet 等语言模型做了很多介绍。
李教授的课幽默风趣、重点突出、基础知识和最新技术一应俱全,PPT 也做得简洁易懂,非常用心,还有课后作业,记得用心完成哦!
李老师说了面向所有人,而且完全可以在家自学。在 B 站上视频已被“机器学习社区”整理为合集,可以方便观看。

视频链接:
2021年李宏毅老师机器学习
视频课程目录
- 1、预测本频道观看人数(上)-机器学习基本概念简介
- 2、预测本频道观看人数(下)-深度学习基本概念简介
- 3、机器学习任务攻略
- 4、类神经网络训练不起来怎么办(一):局部最小值(local minima)与鞍点(saddle point)
- 5、类神经网络训练不起来怎么办(二):批次(batch)与动量(momentum)
- 6、类神经网络训练不起来怎么办(三):自动调整学习率(learning rate)
- 7、类神经网络训练不起来怎么办(四):损失函数(loss)也可能有影响
- 8、类神经网络训练不起来怎么办(五):批次标准化(batch normalization)简介
- 9、卷积神经网络(Convolutional Neural Networks,即CNN)
- 10、注意力机制(self-attention)(上)
- 11、注意力机制(self-attention)(下)
- 12、Transformer(上)
- 13、Transformer(下)
- 14、生成对抗网络(Generative Adversarial Network,即GAN)(一) – 基本概念介绍
- 15、生成对抗网络(Generative Adversarial Network,即GAN)(二) – 理论介绍与WGAN
- 16、生成对抗网络(Generative Adversarial Network,即GAN)(三) – 生成器效能评估与条件式生成
- 17、生成对抗网络(Generative Adversarial Network,即GAN)(四) – Cycle GAN
- 18、自监督式学习(Self-supervised Learning) (一) – 芝麻街与进击的巨人
- 19、自监督式学习(Self-supervised Learning) (二) – BERT简介
- 20、自监督式学习(Self-supervised Learning) (三) – BERT的奇闻异事
- 21、自监督式学习(Self-supervised Learning) (四) – GPT的野望
- 22、自编码器(Auto encoder)(上) - 基本概念
- 23、自编码器(Auto encoder)(下) - 领结变声器与更多应用
- 24、来自人类的恶意攻击(Adversarial Attack) (上) – 基本概念
- 25、来自人类的恶意攻击(Adversarial Attack) (下) – 类神经网络能否躲过人类深不见底的恶意?
- 26、机器学习模型的可解释性(Explainable ML) (上) - 为什么神经网络可以正确分辨宝可梦和数码宝贝呢?
- 27、机器学习模型的可解释性(Explainable ML) (下) - 机器心中的猫长什么样子?
- 28、概述领域自适应(Domain Adaptation)
- 29、概述增强式学习(Reinforcement Learning, RL) (一) – 增强式学习跟机器学习一样都是三个步骤
- 30、概述增强式学习(Reinforcement Learning, RL) (二) – Policy Gradient与修课心情
- 31、概述增强式学习(Reinforcement Learning, RL) (三) – Actor-Critic
- 32、概述增强式学习(Reinforcement Learning, RL) (四) – 回馈非常罕见的时候怎么办?机器的望梅止渴
- 33、概述增强式学习(Reinforcement Learning, RL) (五) – 如何从示范中学习?逆向增强式学习
- 34、机器终身学习(Life Long Learning, LL) (一) - 为什么今日的人工智能无法成为天网?灾难性遗忘(Catastrophic Forgetting)
- 35、机器终身学习(Life Long Learning, LL) (二) - 灾难性遗忘(Catastrophic Forgetting)的克服之道
- 36、神经网络压缩(Network Compression) (一) - 类神经网络剪枝(Pruning)与大乐透假说(Lottery Ticket Hypothesis)
- 37、神经网络压缩(Network Compression) (二) - 从各种不同的面向来压缩神经网络
- 38、元学习Meta Learning (一) - 元学习跟机器学习一样也是三个步骤
- 39、元学习Meta Learning (二) - 万物皆可Meta
- 40、课程结语 - 最后的作业并改编《为学一首示子侄》作结
课程作业
- 1、你应该自己完成作业。
- 2、您不应手动修改您的预测文件。
- 3、不要与任何生物共享代码或预测文件。
- 4、不要使用任何方法每天提交超过 5 次的结果。
- 5、不要搜索或使用额外的数据或预先训练的模型。
- 6、如果您违反上述任何规则,您的最终成绩将受到 10% 的处罚。
- 7、Lee教授和助教保留更改规则和等级的权利。
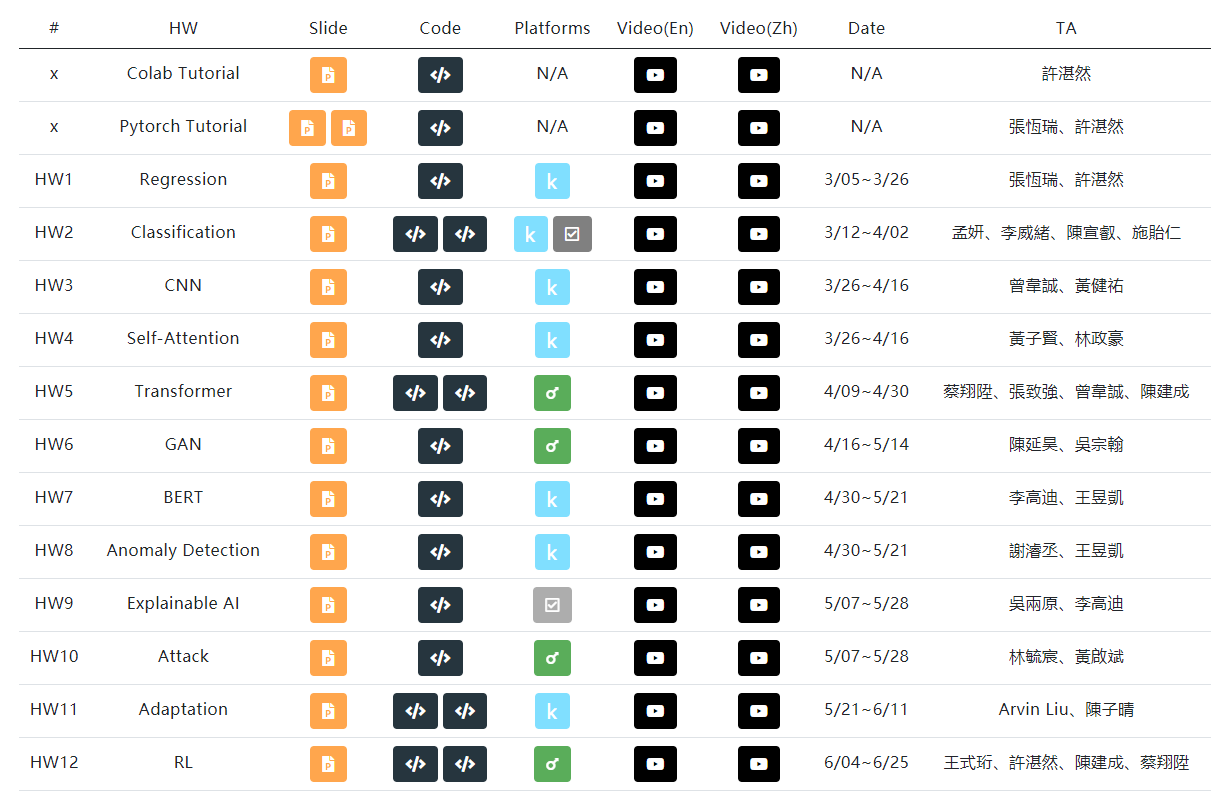
作业内容
技术交流
欢迎转载、收藏本文,码字不易,有所收获点赞支持一下!
为方便进行学习交流,本号开通了技术交流群,添加方式如下:
直接添加小助手微信号:dkl88191,备注:CSDN+机器学习,或者按照如下方式(发送至微信,识别即可)添加均可!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









