







I/O多路复用 (单个线程,通过记录跟踪每个I/O流(sock)的状态,来同时管理多个I/O流
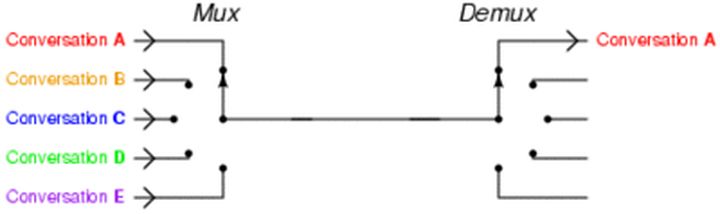
IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。
select, poll, epoll 都是I/O多路复用的具体的实现
select
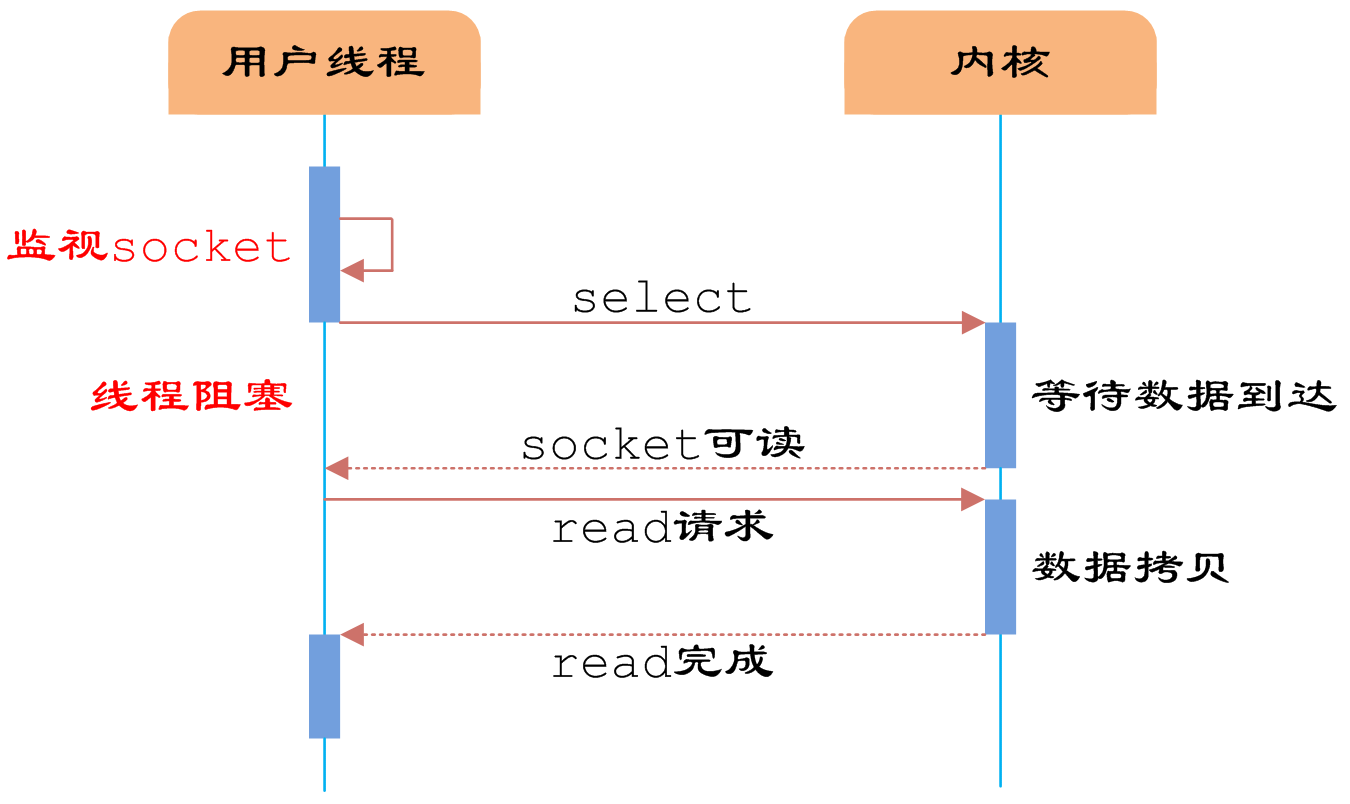
用户首先将需要进行IO操作的socket添加到select中,然后阻塞等待select系统调用返回。当数据到达时,socket被激活,select函数返回。用户线程正式发起read请求,读取数据并继续执行。
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。
但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
select具有的问题
- select 会修改传入的参数数组,这个对于一个需要调用很多次的函数,是非常不友好的。
- select 如果任何一个sock(I/O stream)出现了数据,select 仅仅会返回,但是并不会告诉你是那个sock上有数据,只能自己一个一个的找。
- select 只能监视1024个链接,linux 定义在头文件中的,参见FD_SETSIZE。
- select 不是线程安全的。
用户线程使用select函数的伪代码描述为:
{
select(socket);
while(1) {
sockets = select();
for(socket in sockets) {
if(can_read(socket)) {
read(socket, buffer);
process(buffer);
}
}
}
}其中while循环前将socket添加到select监视中,然后在while内一直调用select获取被激活的socket,一旦socket可读,便调用read函数将socket中的数据读取出来。
poll
poll使用链表保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
epoll的改进
- epoll 是线程安全的。
- epoll 不仅告诉你sock组里面数据,还会告诉你具体哪个sock有数据。
epoll的设计思路
epoll的设计和实现与select完全不同。epoll通过在Linux内核中申请一个简易的文件系统(文件系统一般用什么数据结构实现?B+树)。把原先的select/poll调用分成了3个部分:
- epoll_create()系统调用。此调用返回一个句柄,之后所有的使用都依靠这个句柄来标识。
- epoll_ctl()系统调用。通过此调用向epoll对象中添加、删除、修改感兴趣的事件,返回0标识成功,返回-1表示失败。
- epoll_wait()系统调用。通过此调用收集收集在epoll监控中已经发生的事件。
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。
如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。
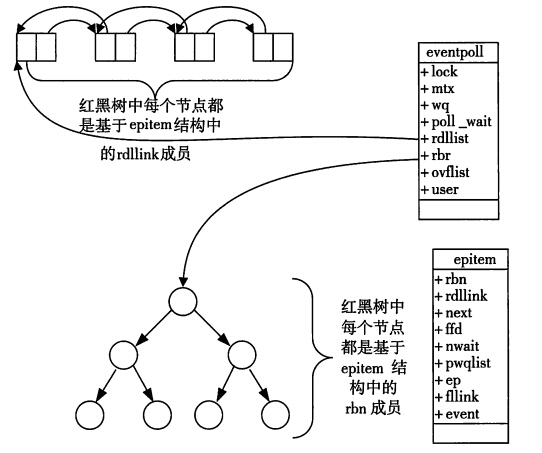
通过红黑树和双链表数据结构,并结合回调机制,造就了epoll的高效。















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









