







目录
1 模型引入与概述
机器学习的第一个算法也是最简单的算法是线性回归,对于输入x,模型输出的y是连续的,这也是回归问题(预测)和分类问题的区别,分类问题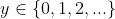 ,二分类问题
,二分类问题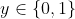 都是离散值,而回归问题
都是离散值,而回归问题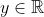 。明明是分类算法为什么称作Logistic regression,个人理解是因为Logistic Function的输出是
。明明是分类算法为什么称作Logistic regression,个人理解是因为Logistic Function的输出是![\left [ 0,1 \right ]](https://i-blog.csdnimg.cn/blog_migrate/7428f8f18de599c20782096f25a94a3e.gif) 之间的实数,这与回归问题的输出是如出一辙的。
之间的实数,这与回归问题的输出是如出一辙的。
1.1 sigmoid函数
下面进行Logistic regression模型的详解,Logistic regression不仅能解决二分类问题,也能处理多分类问题,以二分类问题为例,多分类问题会在后面讲解。Logistic regression的主要思想是使得目标函数的输出![h_\theta {\left ( x \right )}\in\left [ 0,1 \right ]](https://i-blog.csdnimg.cn/blog_migrate/ff13d0657d14783be53876d98d3ceb5d.gif) ,而能够使得函数输出在0,1之间的则关键在于阶跃函数sigmoid function:
,而能够使得函数输出在0,1之间的则关键在于阶跃函数sigmoid function: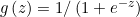 ,sigmoid函数的图像如下图所示:从图上可以看出,对于输入值大于零,输出值大于0.5;输入值小于零,输出值小于0.5,这也是用于分类的依据,另外,当输入值接近正无穷大时,函数输出为1,当输入值趋近无穷小时,函数输出为0。
,sigmoid函数的图像如下图所示:从图上可以看出,对于输入值大于零,输出值大于0.5;输入值小于零,输出值小于0.5,这也是用于分类的依据,另外,当输入值接近正无穷大时,函数输出为1,当输入值趋近无穷小时,函数输出为0。

1.2 模型表示
对于Logistic regression模型,具体表示为:
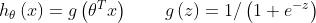 ,
,
即:
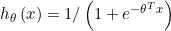
模型预测的是对于给定x和参数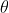 ,其输出值为1的概率:
,其输出值为1的概率: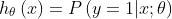 ,并且有
,并且有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3791
3791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









