







【机器学习】学习理论(learning theory)
1.偏差\方差权衡

假设的泛化误差是训练集中不一定出现的例子的期望误差。最左图和最右图的模型的泛化误差都很大,但两者的情况并不一样。如左图,用线性模型去拟合非线性关系,就会产生较大偏差而欠拟合;像右图一样,用五阶多项式拟合,看起来对现有训练集的数据确实拟合得很好,但也容易被当前有限的训练数据所“欺骗”,从而不能反映所有的数据的结构,存在较大方差,出现过拟合现象。
一般都需要在偏差和方差之间进行权衡。因为只有少量参数的简单模型极有可能存在大偏差小方差,而带有大量参数的复杂模型,极可能存在大方差小偏差。上面例子中,二阶多项式模型的拟合效果就会优于一阶和五阶模型。
2.预备知识
- union bound
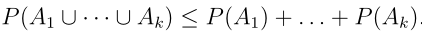
以上k个事件不一定相互独立。这个式子说明k个事件中任意一个发生的概率至多是k个不同事件的概率之和。 - Hoeffding inequality(Chernoff bound)
设 X 1 , . . . , X m X_{1},...,X_{m} X1,...,Xm是m个独立同分布且服从参数为 ϕ \phi ϕ的伯努利分布。令 ϕ ^ = ( 1 / m ) ∑ i = 1 m X i \hat{\phi}=(1/m)\sum_{i=1}^{m}X_{i} ϕ^=(1/m)∑i=1mXi, γ > 0 \gamma>0 γ>0为一定值。则:
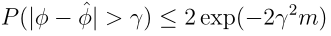
即只要 m m m足够大,我们直接令 ϕ = ϕ ^ \phi=\hat{\phi} ϕ=ϕ^,我们远离正确结果的概率就很小。
下面以二分类问题为背景,利用这两个引理来证明一些机器学习领域非常重要的理论。
假设我们有一个训练集S,里面有m个独立同分布的样本点,服从于某个分布D。对于假设h,我们定义训练误差(也叫empirical risk或 empirical error)为:
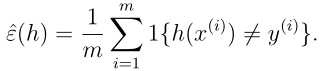
下面我们想搞清楚训练误差对训练集的依赖程度,定义训练误差为:
ε
^
S
(
h
)
\hat{\varepsilon }_{S}(h)
ε^S(h),定义泛化误差为:
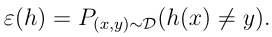
这是对一个服从D分布的新数据点分类错误的概率。我们将在PAC(probably approximately correct) 框架下评价泛化误差。empirical risk minimization (ERM) 是最基础的学习算法,通过使训练误差最小来对参数进行拟合。考虑线性分类的情况:
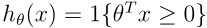
一种比较合适的对参数
θ
\theta
θ进行拟合的方就是最小化训练误差,然后选择:
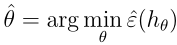
我们定义学习算法所用的假设类
H
H
H为相关分类器的集合。例如线性分类器:
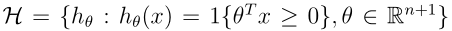
ERM现在可以被认为是对H类函数进行最小化,即在H类函数中学习算法将选择满足下式的假设h:
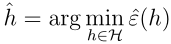
3.H类有限的情况
- 定理
假设H中有k个h, 令m,
δ
\delta
δ为定值,则有:
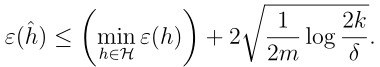
- 推论
假设H中有k个h, 令
γ
\gamma
γ,
δ
\delta
δ为定值, 若
ε
(
h
^
)
≤
m
i
n
h
∈
H
ε
(
h
)
+
2
γ
\varepsilon(\hat{h})\leq min_{h\in H} \varepsilon(h)+2\gamma
ε(h^)≤minh∈Hε(h)+2γ的概率至少为
1
−
δ
1-\delta
1−δ,则训练集数据量应满足:
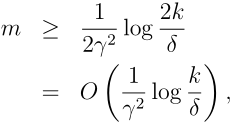
4.H类无限情况
假设一个与训练集无关的集合 S = { x ( i ) , . . . , x ( d ) } S=\{x^{(i)},...,x^{(d)}\} S={x(i),...,x(d)},如果H能够实现S上的任意标签,即对于任意标签集合 { y ( 1 ) , . . . , y ( d ) } \{y^{(1)},...,y^{(d)}\} {y(1),...,y(d)},总存在一些 h ∈ H h\in H h∈H使 h ( x ( i ) ) = y ( i ) , i = 1 , . . . , d h(x^{(i)})=y^{(i)},i=1,...,d h(x(i))=y(i),i=1,...,d我们称 “H shatters S” 。
给定一个假设类H,我们定义它的Vapnik-Chervonenkis dimension(写作VC(H)) 为H可以shatter的最大集合的大小。例如,线性分类器的H,可以对平面上的三个点实现完全分类,但不能对四个点实现完全分类,则VC(H)=3。注意这可能有一些大小为3的集合它不能shatter。如下图:















 1546
1546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









