









FLink-11-Flink相关概念-Flink时间语义和waterMark
Flink时间语义和waterMark
1.三种时间概念
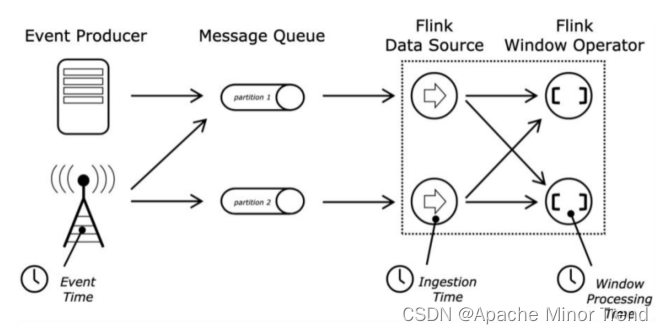
- flink 内部为了直观地统一计算时所用的时间标准,特制定了两种时间语义:
- processing time 处理时间
- event time 事件时间
- Ingestion time 注入时间
- 时间语义主要影响“窗口计算”
2.时间语义
- Flink 搞出 “事件时间语义”:时间按数据中的业务时间戳来推进!
- 主要是,实时流式计算中,有大量跟时间相关的统计需求,比如:时间窗口计算,定时器等,而这些 需求,如果都让用户像上面的代码那样自己去进行判断、处理,那么它觉得自己的 api 不够强大!
- 所以,flink 想在 api 的层面,将两类时间定义的计算需求进行 api 层面的统一,它才搞出” 事件时间语义“,
- 有了“事件时间”语义,那么,处理时间 和 事件时间,都可以看成 ”时间”。
- 用户在不同时间定义下,要进行一个定时动作时,就不需要再像之前的代码那种去进行各种判断时间维度,而 是一个统一的动作: 到 xxx 时间,做什么事!
process(EventLog eventlog,TimeStamp timestamp){
// 不管需求是需要用哪种时间来计算,用户代码只需要看到一个 timestamp 了
}
代码中的 timestamp 到底是事件时间,还是处理时间,取决于环境中设置的“时间语义”
- 在数据计算(处理)的时候,依据的时间标准不同,处理结果可能差异很大,所以,flink中设计了两种时间语义。
- 所谓时间语义:就是用那种时间作为时间判断标准。
1.处理时间(processing time)语义
Processing Time 是指数据被 Operator 处理时所在机器的系统时间。 处理时间遵循客观世界中时间的特性:单调递增,恒定速度,永不停滞,永不回退;
2.事件时间(event time)语义
- 迟到、乱序等时间观念,只有在事件时间语义中才存在,在处理事件中不存在。
- Event Time 是指在数据本身的业务时间(如用户行为日志中的用户行为时间戳);
- Event Time 语义中,时间的推进完全由流入 flink 系统的数据来驱动: 数据中的业务时间推进到哪,flink 就认为自己的时间推进到了哪;
- 它可能停滞,也可能速度不恒定,但也一定是单调递增不可回退!
3.时间语义的设置
1.老版本API中指定时间语义
1.12 以前,flink 默认以 processing time 作为默认的时间语义;可以在 env 上设置所想要的时间语义;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置 EventTime 作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//设置 IngestionTime 作为时间标准
//env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
//设置 ProcessingTime 作为时间标准
//env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
2.新版本API中指定时间语义
- 1.12 及以后,flink 以 event time 作为默认的时间语义,并 deprecated 了上述设置 api;
在需要指定时间语义的相关操作(如时间窗口)时,可以通过显式的 api 来使用特定的时间语义;
keyedStream.window(SlidingEventTimeWindows.of(Time.seconds(5),Time.seconds(1))); keyedStream.window(SlidingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(1))); keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(5))); keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
- 新版 api 中禁用事件时间语义 如果需要禁用 event time 机制,则可以通过设置 watermark 生成频率间隔来实现:
// 如果设置为 0,则禁用了 watermark 的生成;从而失去了 event time 语义 ExecutionConfig.setAutoWatermarkInterval(long);
3.WaterMark
1.相关概念
- 所谓 watermark,就是在事件时间语义世界观中,用于单调递增向前推进时间的一种标记;
- 它的核心机制是在数据流中周期性地插入一种时间戳单调递增的特殊数据元素(watermark), 来不可逆转地在整个数据流中进行时间的推进;
- Watermark 是从某一个算子实例(源头)开始,根据数据中的事件时间,来周期性地产生,并插入到 数据流中,持续不断地往下游传递,以推进整个计算链条上各个算子实例的时间!
// watermark 的生成周期(默认值即为 200ms)
env.getConfig().setAutoWatermarkInterval(200);
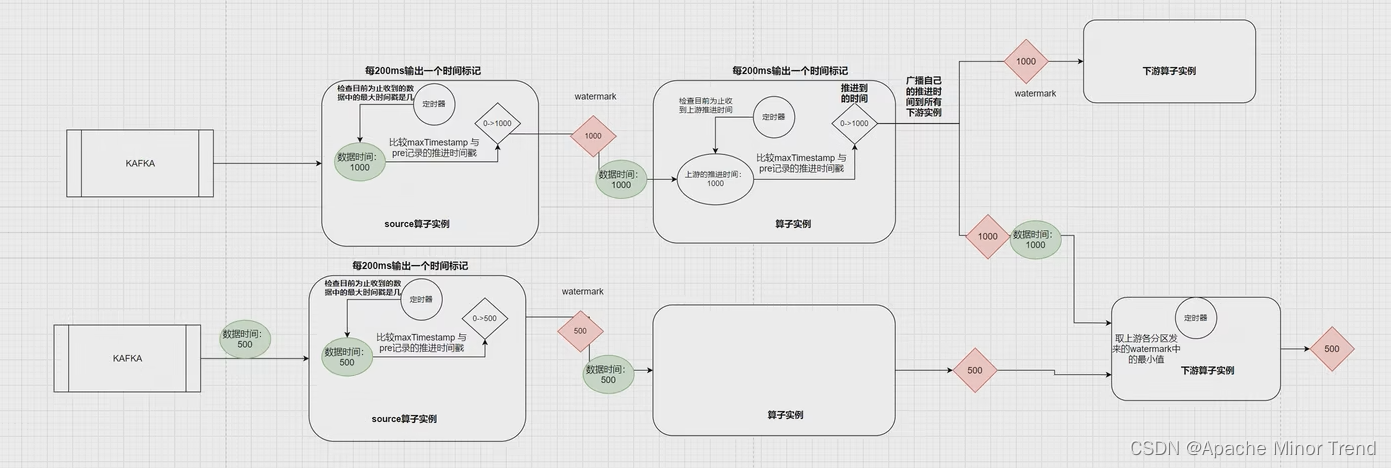
- watermark,本质上也是 flink 中各算子间流转的一种标记数据,只不过与用户的数据不同,它是 flink 内部自动产生并插入到数据流的;
总结
-
1.waterMark实际上是一个时间标志位,是定时器对外暴露的一个时间标志位。
-
2.在一个单独的数据流中,数据到达时会依据数据的时间一直更新waterMark,判断当前数据时间跟waterMark中记录的时间,取两者的最大值作为waterMark的最新时间,当waterMark的时间到达此时设置的时间窗口的最大值时,触发了定时器进行窗口的统计计算;
- 如果数据是在窗口统计完成后又来了,且此数据的时间小于刚刚的时间标志位的时间,那此条数据就是迟到数据,不会统计在刚刚结束的窗口期内汇算。
-
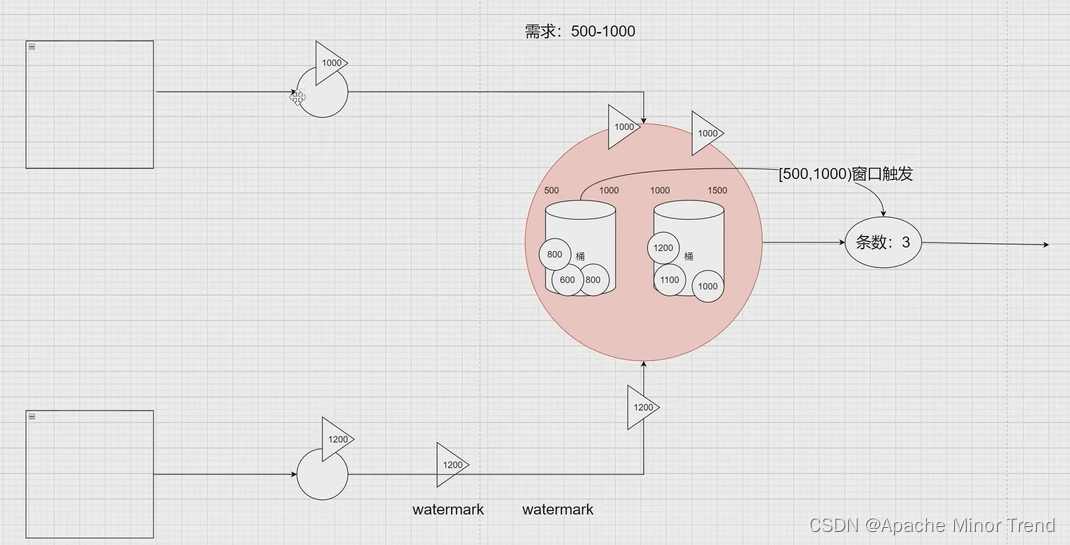
3.两个数据流进行汇算的时候,waterMark取的是两流中最小的一个时间作为waterMark的当前时间;
- 因为需要进行两个流的数据汇算,如果waterMark以另一个流大的时间为准的话,就会造成提前触发时间窗口的汇算,刚刚那个流会出现大量的迟到数据。
- 所以取两个流中小的时间存入waterMark,同时流入的数据,小于当前waterMark记录的时间,则waterMark不会更新,直到两个流的数据时间都到达了窗口临界值,此时waterMark中记录的时间和窗口临界值一致,则触发定时器进行窗口计算。
-
4.waterMark中有种机制,当某个流中超过一定时间没有数据产生,那么waterMark会主动更新内部时间,可能会提升几秒,这样的话,就不会造成窗口迟滞、数据大量积压的情况,主动触发窗口,这种机制就是:watermark-idle-timeout,需要主动设置此参数,在程序的源头。
-
- 容错时间:如果waterMark的时间紧跟收到的数据的最大事件时间,那么会造成大量数据被抛弃,所以需要设置缓冲策略,可以设置为 waterMark = 最大事件时间-5s.此刻这个5S就是容错时间。这样就一定程度上缓解了大量数据被抛弃的问题。
-
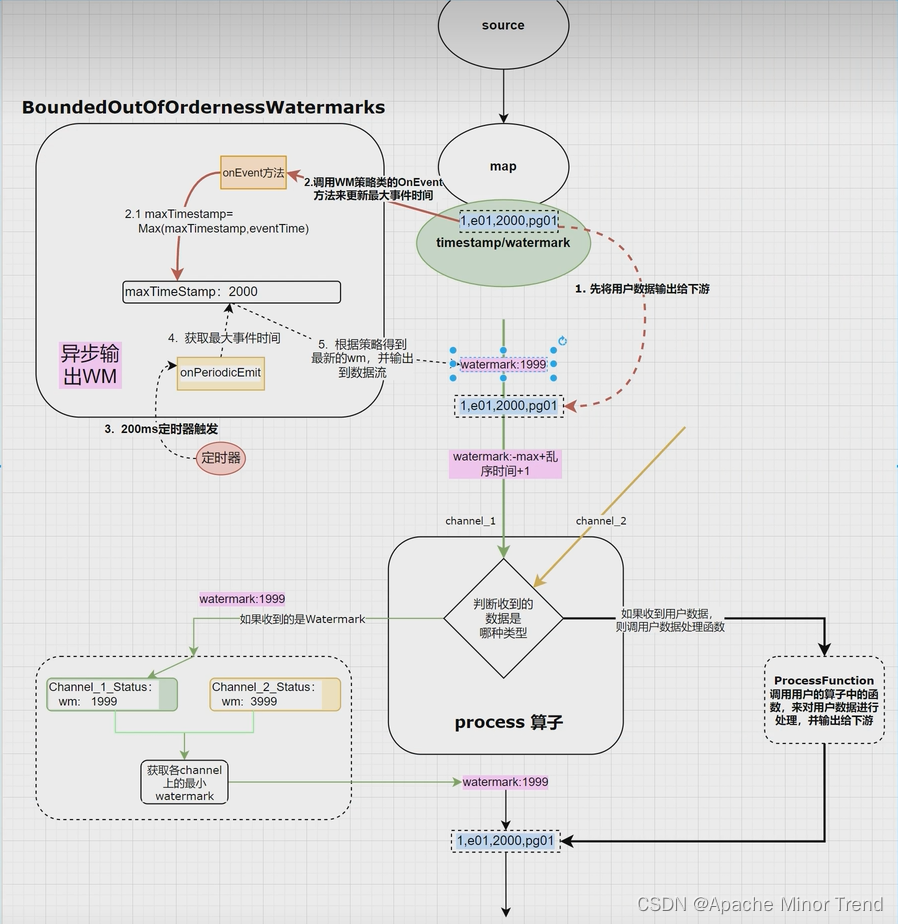
6.数据驱动时间的推进,waterMark的推进,一定是在数据流入之后先往外输出数据,再更新waterMark。宗旨是:优先处理数据,数据处理完毕以后,再更新waterMark中的时间为数据流的时间。
-
下面图中样例就是第一次数据来的时候,waterMark的调用机制,以及在后面算子中的waterMark的更新时间是在数据处理完成后次更新的waterMark中的时间。
-
先回收数据然后进行调用waterMark如下面源码:
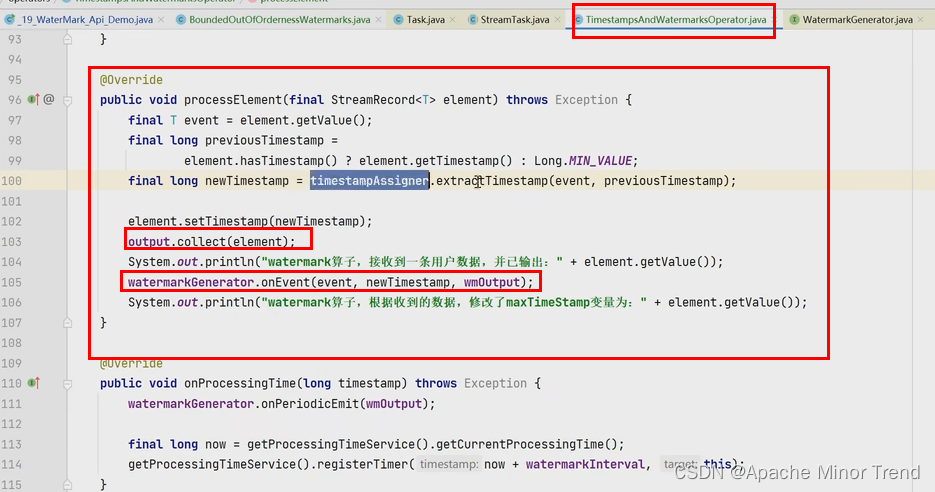
-
process算子中间判断机制的源码信息如下:
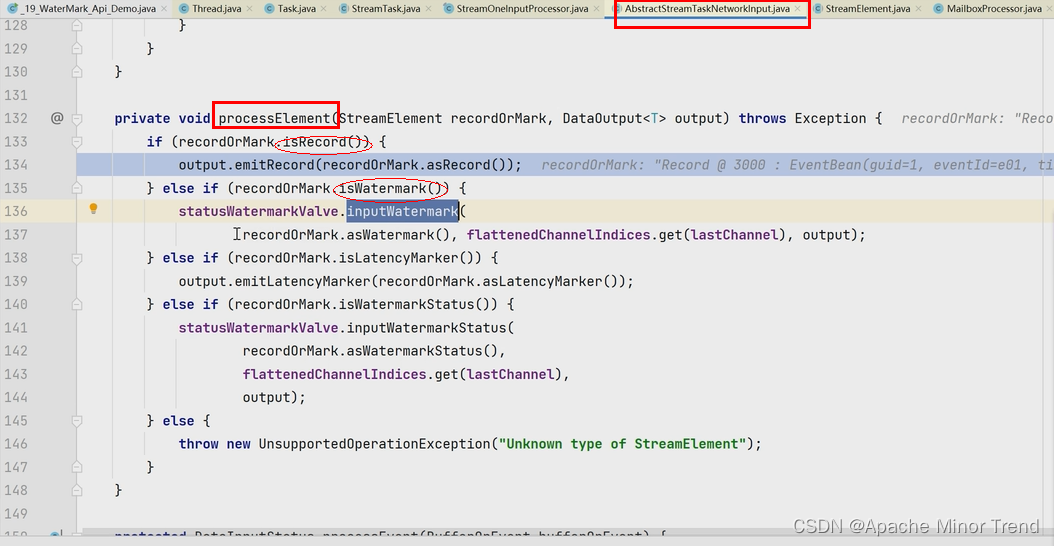
-
-
7.想要进行局部源码测试,但是通过开发工具点出来的源码中,无法添加代码,此时需要怎么处理?
- 1.将需要测试的源码 类,原封不动的写出到本地代码库中,程序加载的时候,会优先加载我们写的这个源码类,这样的话就可以在里面进行书写自己的测试代码了-- 狸猫换太子。
2.waterMark的API的使用
-
watermark 生成时机策略 此前有两种生成时机策略:
- AssignerWithPeriodicWatermarks 周期性生成 watermark
- AssignerWithPunctuatedWatermarks[已过期] 按指定标记性事件生成 watermark
- 在 flink1.12 后,watermark 默认是按固定频率周期性地产生;
-
watermark 的生成值算法策略
- 紧跟最大事件时间的 watermark 生成策略(完全不容忍乱序)
WatermarkStrategy.forMonotonousTimestamps(); - 允许乱序的 watermark 生成策略(最大事件时间-容错时间)
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10)); // 根据实际数据的最大乱序情况来设置 - 自定义 watermark 生成策略
WatermarkStrategy.forGenerator(new WatermarkGenerator(){ ... } );
- 紧跟最大事件时间的 watermark 生成策略(完全不容忍乱序)
-
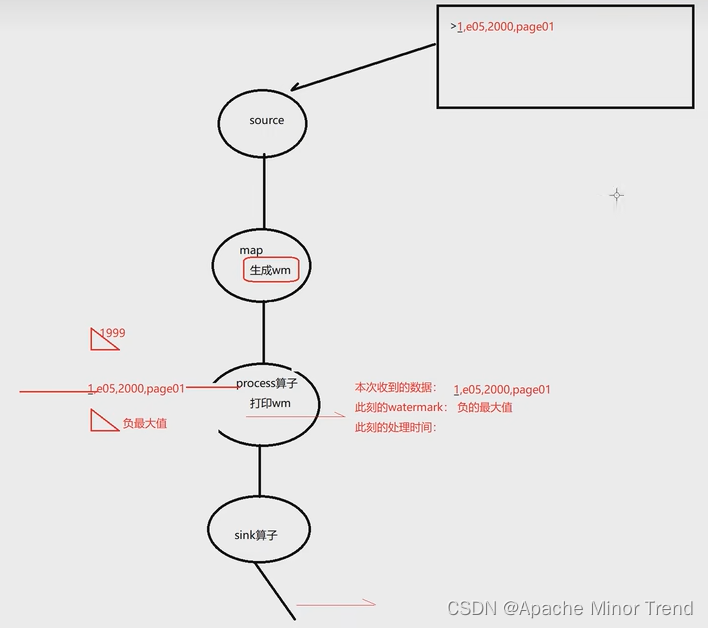
waterMark在程序处理的最开始的时候,是负最大值,当程序开始触发,进入第一条数据的时候,此时waterMark依然是负最大值,直到第一条数据处理完毕以后,waterMark才更新为第一条数据的时间戳字段。waterMark的数值=最大事件时间的值-1.
- 相关分析:
- 相关数据截图
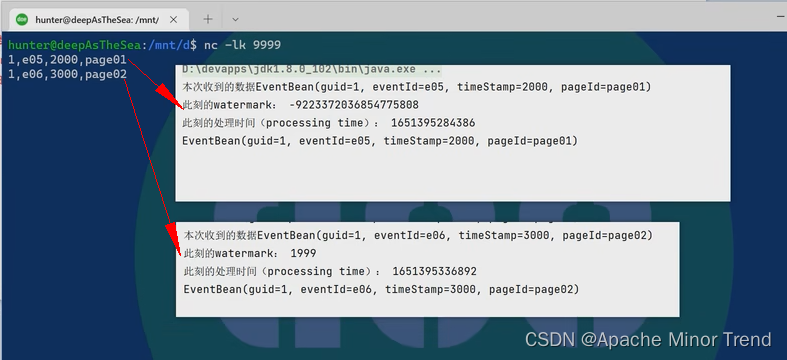
- 相关分析:
-
单并行度下,waterMark的代码示例:
package com.yang.flink.waterMark;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkGenerator;
import org.apache.flink.api.common.eventtime.WatermarkGeneratorSupplier;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class WaterMarkApiDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//数据样例:1,e01,1674053498497,pg01
DataStreamSource<String> streamSource = env.socketTextStream("hadoop102", 9999);
/** waterMark生成策略
* 策略1:WatermarkStrategy.noWatermarks(); 不生成WaterMark,禁用事件时间的推进机制
* 策略2:WatermarkStrategy.forBoundedOutOfOrderness(); 允许乱序的watermark生成策略
* 策略3:WatermarkStrategy.forMonotonousTimestamps(); 紧跟最大事件时间
* 策略4:WatermarkStrategy.forGenerator(); 自定义watermark生成算法
*
*/
WatermarkStrategy<String> watermarkStrategy = WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofMillis(2000))//选择waterMark生成策略为 允许乱序的waterMark生成策略
.withTimestampAssigner(new SerializableTimestampAssigner<String>() { //选择哪一个时间作为事件时间
@Override
public long extractTimestamp(String element, long recordTimestamp) {
return Long.parseLong(element.split(",")[2]);
}
});
/*
示例一:从源头开始,生成waterMark
*/
streamSource.assignTimestampsAndWatermarks(watermarkStrategy);
/*
示例二:不从最源头算子开始生成waterMark,而是从中间环节的某个算子开始生成waterMark
注意:如果已经从源头生成了waterMark了,就不要在下游再次产生waterMark
*/
SingleOutputStreamOperator<EventBean> stream = streamSource.map(s -> {
String[] split = s.split(",");
return new EventBean(Long.parseLong(split[0]), split[1], Long.parseLong(split[2]), split[3]);
}).returns(EventBean.class)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<EventBean>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<EventBean>() {
@Override
public long extractTimestamp(EventBean element, long recordTimestamp) {
return element.getTs();
}
}));
stream.process(new ProcessFunction<EventBean, EventBean>() {
@Override
public void processElement(EventBean value, Context ctx, Collector<EventBean> out) throws Exception {
//打印此刻的waterMark
long currentWatermark = ctx.timerService().currentWatermark();
long currentProcessingTime = ctx.timerService().currentProcessingTime();
System.out.println("本次数据:"+value);
System.out.println("此刻wm:"+currentWatermark);
System.out.println("此刻处理时间:"+currentProcessingTime);
}
}).print();
env.execute();
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
class EventBean{
private long uid;
private String aa;
private long ts;
private String cc;
}
- 多并行度下,两个流中取waterMark最小的那个值作为waterMark的时间。
package com.yang.flink.waterMark;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkGenerator;
import org.apache.flink.api.common.eventtime.WatermarkGeneratorSupplier;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class WaterMarkApiDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//数据样例:1,e01,1674053498497,pg01
DataStreamSource<String> streamSource = env.socketTextStream("hadoop102", 9999);
SingleOutputStreamOperator<EventBean> stream = streamSource.map(s -> {
String[] split = s.split(",");
return new EventBean(Long.parseLong(split[0]), split[1], Long.parseLong(split[2]), split[3]);
}).returns(EventBean.class)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<EventBean>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<EventBean>() {
@Override
public long extractTimestamp(EventBean element, long recordTimestamp) {
return element.getTs();
}
})).setParallelism(2);
stream.process(new ProcessFunction<EventBean, EventBean>() {
@Override
public void processElement(EventBean value, Context ctx, Collector<EventBean> out) throws Exception {
//打印此刻的waterMark
long currentWatermark = ctx.timerService().currentWatermark();
long currentProcessingTime = ctx.timerService().currentProcessingTime();
System.out.println("本次数据:"+value);
System.out.println("此刻wm:"+currentWatermark);
System.out.println("此刻处理时间:"+currentProcessingTime);
}
}).print();
env.execute();
}
}















 7455
7455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









