









离线数仓-1-数仓前期建设准备工作
离线数仓-1-数仓前期建设准备工作
1.数仓概念
1. 数据仓库概念
数据仓库( Data Warehouse ),是为企业制定决策,提供数据支持的。可以帮助企业,改进业务流程、提高产品质量等。
2. 数据分类
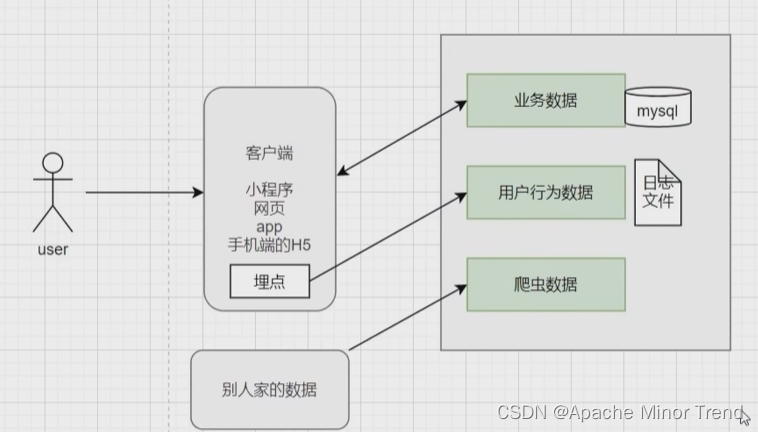
- 业务数据:存放在关系型数据库
- 用户行为数据:前端埋点数据,一般存放在日志文件中
- 爬虫数据:爬取别人家的数据
3.数据仓库总视图
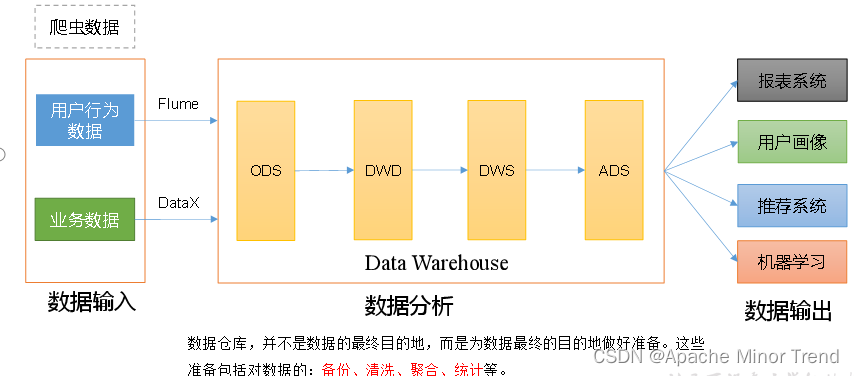
- 数仓各层作用的剖析:
- ODS层进行数据的备份作用,原始数据采集上来是什么样,最终落地ODS层依然是什么样。
- DWD层进行数据清洗工作,清洗的数据有:1.类型不匹配的数据;2.补充数据字段,数据碰撞能否对接成功;3.对敏感数据进行脱敏
- DWS层进行指标统计工作:指标统计工作的处理,指标统计过程中的优化工作(预聚合功能:两大表进行join操作,提前join后,查询数据基于这个提前join完毕的中间表进行查询,提高查询效率,仅需要join一次,即可满足多个指标的查询)。
- ADS层进行统计最终的指标。
4.数据仓库项目需求分析
- 采集平台
- 用户行为数据采集平台搭建
- 业务数据采集平台搭建
- 离线需求处理
- 实时需求处理
5.数仓搭建技术基础分析
数仓搭建技术基础分析相关思考:
1.项目技术如何选型:
- 项目技术选型主要考虑因素:数据量大小、业务需求、行业内经验、技术成熟度、开发维护成本、总成本预算等维度考虑,相关层面技术选型如下,仅针对本项目,其他项目自行选择
| 功能 | 实时+离线 | 仅离线 | 仅实时 | 不采用 |
|---|---|---|---|---|
| 数据采集传输 | Flume,Kafka,Maxwell | DataX | Sqoop,Logstash | |
| 数据存储 | Mysql | HDFS | HBase,Redis | MongoDB(机器学习中使用) |
| 数据计算 | Hive,Spark | Flink | Storm,Tez | |
| 数据查询 | Presto | ClickHouse | Kylin,Impala,Druid,Doris | |
| 数据可视化 | Superset | Sugar | Echarts,QuickBI,DataV | |
| 任务调度 | DolphinScheduler | Azkaban,Ozzie,Airflow | ||
| 集群监控 | Zabbix | Prometheus | ||
| 元数据管理 | Atlas | |||
| 权限管理 | Ranger,Sentry |
2.框架版本如何选型;
- 1.框架发型版本选择
- 1.如何选择Apache/CDH/HDP版本

- 2.云服务选择
- 阿里云的EMR、MaxCompute、DataWorks
- 亚马逊云EMR
- 腾讯云EMR/华为云EMR
- 1.如何选择Apache/CDH/HDP版本
- 2.Apache框架版本选择:框架选型尽量不要选择最新的框架,选择最新框架半年前左右的稳定版本。具体版本如下:
| 技术组件 | 旧版本 | 新版本 |
|---|---|---|
| Hadoop | 2.7.2 | 3.1.3 |
| Zookeeper | 3.4.10 | 3.5.7 |
| Mysql | 5.6.24 | 5.7.14 |
| Hive | 1.2.1 | 3.1.2 |
| Flume | 1.7.0 | 1.9.0 |
| Kafka | 2.4.1 | 3.0.0 |
| Spark | 2.1.1 | 3.0.0 |
| DataX | 3.0.0 | |
| Superset | 1.3.2 | |
| DolphinScheduler | 1.3.9 | 2.0.3 |
| Maxwell | 1.29.2 | |
| Flink | 1.13.0 | |
| Redis | 6.0.8 | |
| HBase | 2.0.5 | |
| Clickhouse | 20.4.5.36-2 |
3.服务器使用物理机还是云主机;
-
1.物理机:
- 单个机器(128G,20C,40线程,8THDD和2TSSD硬盘,戴尔平台),报价4W左右,物理机寿命5年左右。
- 需要有专业的运维人员,平均每月1万左右,电费也是不少开销
-
2.云主机
- 云主机,单个机器 (128G,20C,40线程,8THDD和2TSSD硬盘),阿里云为例,差不多相同配置,每年5W左右。
- 运维工作都是有阿里云完成,运维相对较轻松
-
3.企业如何选择:
- 金融有钱公司,和阿里没有直接冲突的公司 选择阿里云
- 中小公司、为了融资上市,选择阿里云,拉倒融资后买物理机
- 有长期打算,资金充足,选择物理机。
-
4.如何确认集群规模:
- 1.如何确认集群规模 ?(假如:每台服务器8T磁盘,128G内存)
- 1.日活,假设每天活跃用户100万,每人每天平均100条:100万*100条=一亿条
- 2.每条数据1KB左右,每天一亿条数据:总容量:1亿KB/1024/1024 = 约100G
- 3.半年内不扩容服务器来计算:100G*180天=约18T
- 4.HDFS需要保存3副本:18T*3 = 54T
- 5.需要预留20%-30%Buf,54T/0.7 = 77T
- 6.总共需要的服务器:77T/8T 约10台服务器
- 以上计算没有将数据压缩考虑在内,HDFS存储数据的时候必然会进行数据压缩,Parquet格式列式存储,压缩比更高,这里需要将压缩维度考虑在内,然后重新基于刚刚的步骤再进行计算。
- 2.如果考虑数仓分层?数据采用压缩?还需要基于刚刚的重新计算
- 如果基于每天未压缩前100G数据量:
- 使用3台服务器,存储半年时间完全够用
- 使用5-10台服务器,存储1-2年完全够用
- 如果基于每天未压缩前100G数据量:
- 1.如何确认集群规模 ?(假如:每台服务器8T磁盘,128G内存)
5.集群资源规划设计
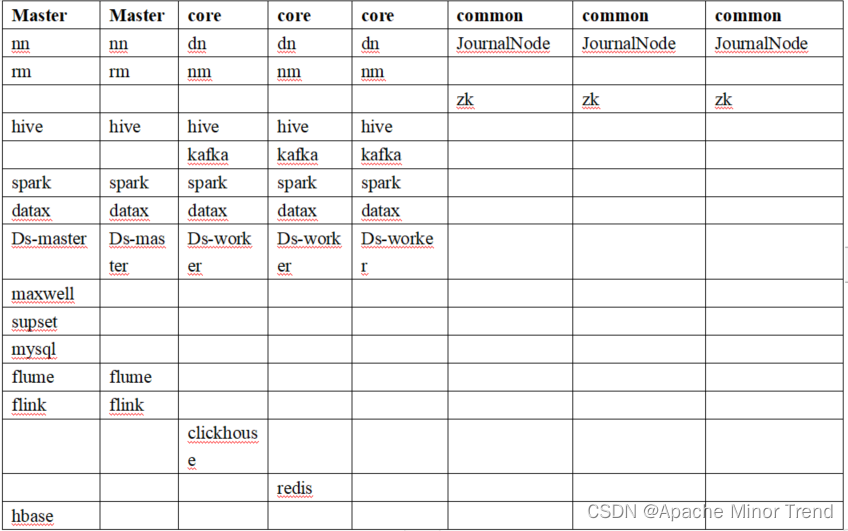
1.生产集群
- 遵循原则
- (1)消耗内存的分开
- (2)数据传输数据比较紧密的放在一起(Kafka 、Zookeeper)
- (3)客户端尽量放在一到两台服务器上,方便外部访问
- (4)有依赖关系的尽量放到同一台服务器(例如:Hive和mysql)
2.测试集群
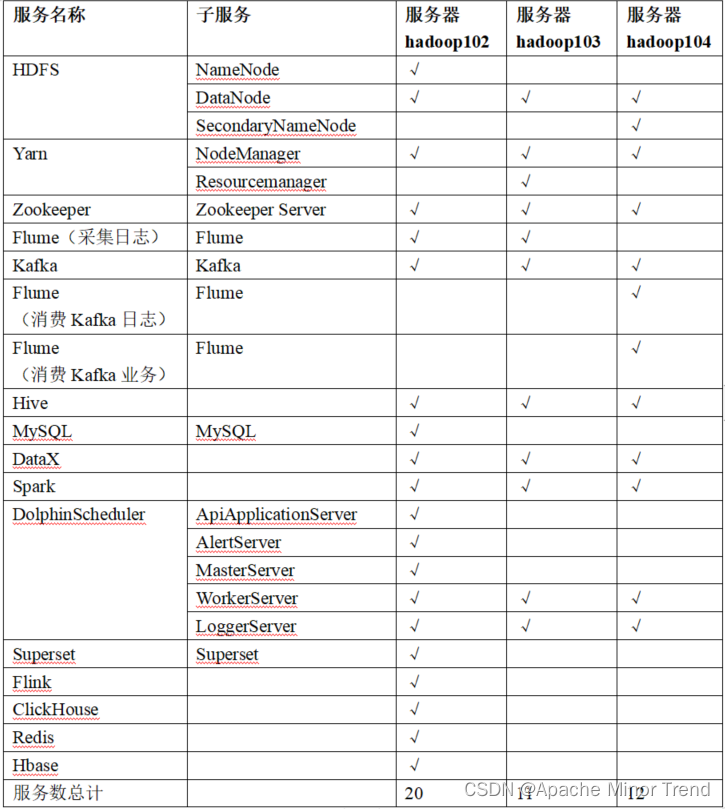
6.系统数据流程图
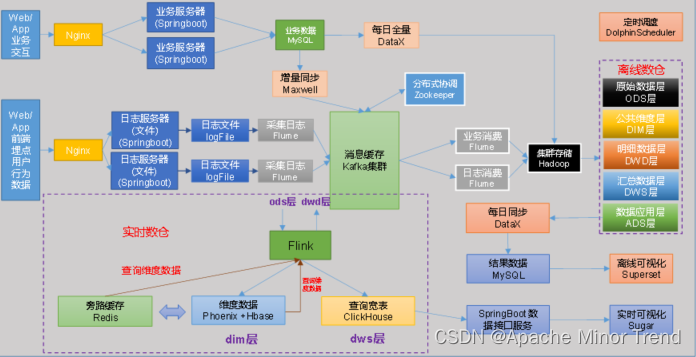
- kafka作用:
- 1.削峰,商城数据量级很大,需要考虑双11或者618这种大促活动,需要将集中式大批量数据进行削峰处理
- 2.解耦,离线计算使用flume同步到HDFS中,同时也可以使用Flink进行实时计算。
















 3749
3749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









