






什么是HDFS RBF
在前文中提到,HDFS 联邦架构使得HDFS 的NameNode 具有可伸缩性,针对多个NameNode,用户该如何去使用这些NameNode 呢?常见的解决方案是针对联邦中的HDFS 子集群提供 联合视图 ViewFs。ViewFs 提供一个挂载表,指明哪些路径实际指向那个NameNode,这个挂载表配置在客户端,如果客户端发现路径的schema 是viewfs,就会去查询挂载表,找到该文件的所在的NameNode,最终去与对应的NameNode交互
ViewFs的优缺点:
优点:
- 负载在客户端,对NameNode无任何影响
- 实现简单
缺点:
- 挂载表 的挂载点访问含义不明确:
(1)由于HDFS客户端原有的机制,一个DFSClient 只对应一个nameservice,所以一次路径处理不能转为多个nameservice的多次PRC
(2)对于跨挂载点的读操作,指根据挂载配置返回假结果
(3)对于跨挂载点的写操作(rename),会报出异常 - 维护成本高,每次修改挂载表,必须及时更新所有客户端的配置文件,用老的挂载逻辑写入NameNode,后果很严重
- 引入ViewFs 由于其shcema 与HDFS 默认的 schema 互不兼容,针对上层应用特别不友好
针对ViewFs 以上的问题,是否有更好的解决方法?
根据上述的描述,发现ViewFs 的核心问题在 负载存在于客户端且修改了Schema 这两个问题上,因此如果解决了这两个问题,将负载加入服务端,沿用原有的HDFS 的 schema 就能很好的解决这个问题。HDFS Router-Based Federation (基于路由器的联邦) 就完美的解决了这两点问题:
- 首先HDFS RBF 提供了共享存储来实现挂载表
- 在服务端额外启动Router 的服务,Router 提供了NameNode相同的接口给客户端直接使用,因此schema 与HDFS完全相同
- 用户使用客户端首先与Router连接,Router 根据 共享挂载表来定位文件具体存储在哪个NameNode中
- 最后客户端直接与对应的DataNode相连进行文件的读写
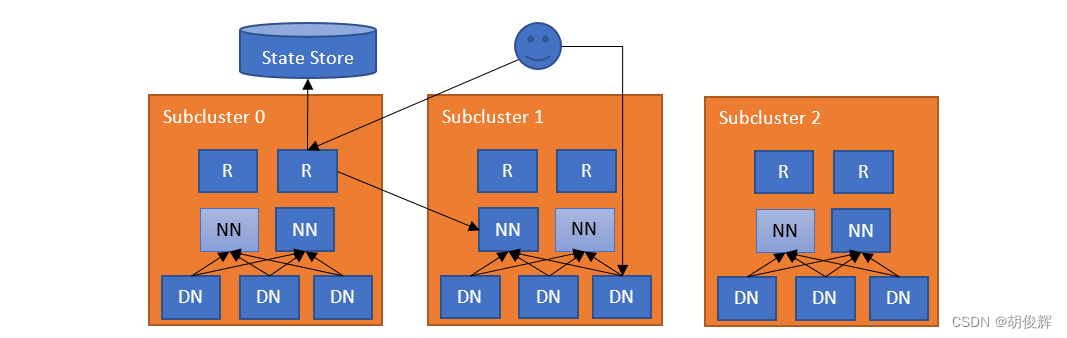
HDFS RBF 架构
- RBF 扩展了一个负责管理联邦 namespace 的服务层,这一层允许用户透明的访问任何子集群
- 每个子集群独立管理自己的块池,同时RBF也支持跨子集群的数据再平衡
- RBF 不需要子集群是一个独立的HDFS集群,可以是普通的联邦集群(内含多个块池)或者是联邦集群和独立集群的混合集群
- RBF 是具有可扩展性、高可用性和容错性的
- 通常最简单的做法就是在每台NameNode上也部署一个Router
- Router会监视本地的NameNode的状态和状态存储的心跳
- 当DFSClient 客户端访问任何一个路由时(由于路由实现了与NameNode完全相同的接口,因此DFSClient 可无缝使用Router),Router会去检测共享的挂载表,找出哪个子集群包含该文件
- 当Router找到对应的NameNode后,会代理访问对应的NameNode并将结果返回给客户端
- 客户端拿到元数据后,就可以根据元数据去访问对应的DataNode 了。















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









