







当数据被多线程并发访问(读/写)时,需要对数据加锁。linux 内核中常用的锁有两类:自旋锁和互斥体。在使用锁的时候,最常见的 bug 是死锁问题,死锁问题很多时候比较难定位,并且影响较大。本文先会介绍两种引起死锁的原因,对比自旋锁和互斥体的区别,最后记录一下可以递归调用的锁。本文通过内核模块来展示锁的使用。
锁保护的是什么 ?
锁保护的是数据,不是代码。数据在代码中要么是一个变量,要么是一个数组,一个链表,红黑树等。如下代码所示,有一个全局静态变量 counter,假如有两个线程分别调用 inc() 和 dec() 函数对 counter 做递增和递减运算。这样在两个线程对 counter 进行修改之前就需要加锁,修改之后解锁。锁保护的是 counter 这个数据,而不是 counter++ 或者 counter-- 这两行代码。
static int counter = 0;
void inc() {
lock();
counter++;
unlock();
}
void dec() {
lock();
counter--;
unlock();
}临界区
临界区指的是代码段,从加锁到解锁的这段代码就称为临界区。终于有一个概念对应的是代码!上边的代码,counter++ 和 counter-- 这两行代码就是临界区。
并发的任务有哪些
最常见的多任务是多个线程,多个线程访问同一个资源,需要加锁。除了线程,任务形式还包括中断和软中断。线程和线程之间,线程和中断之间,线程和软软中断之间,中断和中断之间,分别有不同的锁可以选用。
锁对性能的影响
锁对性能的影响要看临界区所占的线程任务的比例以及并发度。如果并发度比较大,并且每个线程的主要逻辑都在临界区里,这种情况下,锁对性能的影响是比较大的,多线程并发的表现接近于多线程串行的性能。相反,如果并发度不高,并且临界区所占逻辑比例比较小的话,那么对性能影响就会小一些。
在性能分析时,临界区往往会成为程序的热点。
延迟加锁和两次判断
在工作中使用队列,如果队列有多个消费者,消费者在消费的时候往往要先判断队列是不是有数据,如果有数据则消费;否则直接返回。这种场景,往往有两种加锁的方式:
方式 1:
首先加锁,然后判断队列中是不是有数据,有数据则消费,否则返回。
方式 2:
先不加锁,而是先判断队列是不是有数据,如果有数据才加锁。加锁之后还要再进行一次判断,如果有数据则消费,否则返回。
方式 1 少一次判断,适用于队列中经常有数据的场景,因为如果队列中经常没有数据,那么加锁和解锁的操作完全是浪费。方式 2 多一次判断,适用于队列经常没有数据的场景,因为没有数据就直接返回了,减少了加锁和解锁的操作。
// 方式 1
lock();
if (!queue_empty()) {
consume();
}
unlock();
// 方式 2
if (!queue_empty()) {
lock();
if (!queue_empty()) {
consume();
}
unlock();
}
1 死锁
死锁是严重的 bug,造成死锁的原因有两个:自死锁和 ABBA 锁。
1.1 自死锁
自死锁,说的是一个线程已经获取到了这个锁,然后尝试再次获取同一个锁。因为这个锁已经被占用,第二次获取的时候就要一直等。
如下内核模块中,创建了一个内核线程,线程名是 lockThread,线程的入口函数是 thread_func,在这个函数中打印出了线程 id。定义了一个自旋锁 lock,在线程中连续两次调用 spin_lock() 来尝试拿到锁。第一次 spin_lock() 可以成功拿到锁,第二次 spin_lock() 拿不到锁,一直死等。
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/kthread.h>
#include <linux/delay.h>
#include <linux/spinlock.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("Spinlock Example");
spinlock_t lock;
static struct task_struct *thread;
static int thread_func(void *data) {
printk("tid = %d\n", current->pid);
spin_lock(&lock);
spin_lock(&lock);
return 0;
}
static int __init spinlock_example_init(void) {
printk(KERN_INFO "Spinlock Example: Module init\n");
spin_lock_init(&lock);
thread = kthread_run(thread_func, NULL, "lockThread");
return 0;
}
static void __exit spinlock_example_exit(void) {
printk(KERN_INFO "Spinlock Example: Module exit\n");
kthread_stop(thread);
}
module_init(spinlock_example_init);
module_exit(spinlock_example_exit);
如下是内核模块运行情况,线程 id 是 4151。自旋锁死锁问题可以被 soft lockup 机制检测出来并打印相关的信息。
soft lockup 异常检测,参考如下链接:
[linux][异常检测] hung task, soft lockup, hard lockup, workqueue stall
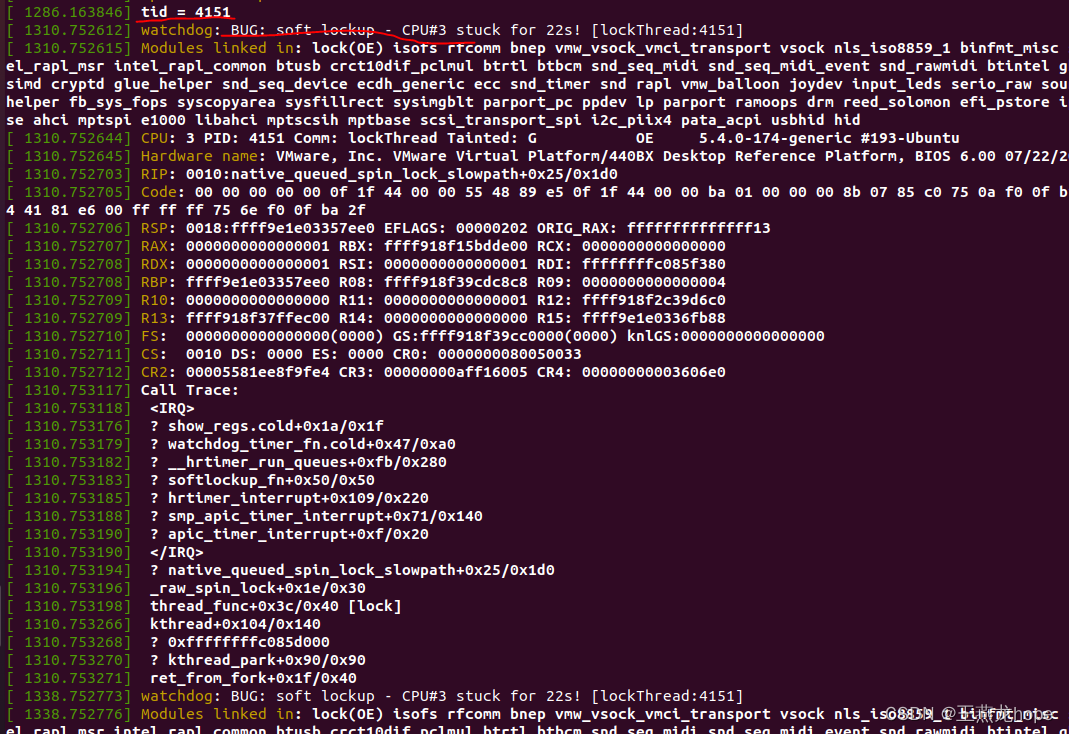
通过 top 命令可以看到线程 4151 的 cpu 占用情况。可以看到 cpu 占用率达到 100%,这也是自旋锁的一个特点,使用自旋锁在等待锁的时候是一直自旋,也就是一直死循环,一直占着 cpu。

1.2 ABBA 锁
读 《明朝那些事》的时候看到了一个例子。朱元璋洪武二十年派兵讨伐北元。当时明军的实力相对于北元有绝对的优势,当明军找到北元的时候并没有进攻,而是采取了劝降的策略。投降仪式在一个饭局进行,明军设盛宴款待北元的纳哈出。
死锁的双方是明军的蓝玉和北元的纳哈出。下边这段话是原文:
就在一切都顺利进行的时候,蓝玉的一个举动彻底打破了这种和谐的气氛。
当时纳哈出正在向蓝玉敬酒,大概也说了一些不喝酒就不够兄弟的话,蓝玉看纳哈出的衣服破旧,便脱下了自己身上的衣服,要纳哈出穿上。
应该说这是一个友好的举动,但纳哈出拒绝了,为什么呢 ?这就是蓝玉的疏忽了,他没有想到,自己和纳哈出不是同一个民族,双方的衣着习惯是不同的,虽然蓝玉是好意,但在纳哈出看来,这似乎是胜利者对失败者的一种强求和恩赐。
蓝玉以为对方客气,便反复要求纳哈出穿上,并表示纳哈出不穿,他就不喝酒,而纳哈出则顺水推舟的表示,蓝玉不喝,他就不穿这件衣服。
蓝玉和纳哈出这样僵持下去,那么蓝玉永远不会喝纳哈出的酒,纳哈出也永远不会穿蓝玉的衣服。
有两个锁,锁 A 和 锁 B。有两个线程,线程 1 和线程 2。线程 1 获取到了锁 A,与此同时线程 2 获取到了锁 B,然后线程 1 尝试获取锁 B,线程 2 尝试获取锁 A。因为锁 A 被线程 1 持有,所以线程 2 无法获取到锁 A,只能一直等待;锁 B 被线程 2 持有,所以线程 1 也只能一直等待。这样两个线程都获取不到锁,只能死等。这就是死锁。

为避免死锁,在开发中应该遵守一些简单的规则:
① 不要重复请求同一个锁,防止自死锁
② 按顺序加锁
如果在代码中要用多个锁,那么要按相同的顺序来加锁,这样可以避免 ABBA 锁。如上面这张图,线程 1 和线程 2 首先都获取锁 A 或者都获取锁 B,这样就不会产生死锁了
③ 防止发生饥饿,保证临界区的代码是可以执行结束的,而不是一直执行,导致锁不会被释放
④ 按顺序释放锁,以加锁的逆顺序来释放锁,比如加锁的时候先加锁 A 再加锁 B,那么释放锁的时候尽量先释放锁 B,再释放锁 A
2 自旋锁与互斥体
2.1 自旋锁
2.1.1 自旋锁
spinlock_t
自旋锁的数据类型,使用 spinlock_t 可以声明一个自旋锁
spin_lock_init()
初始化自旋锁
spin_lock(), spin_unlock()
自旋锁加锁,自旋锁解锁。数据被多线程共享时,可以使用这两个函数加锁和解锁。
spin_lok_irq(),spin_unlock_irq()
关闭本地中断,加锁;解锁并开启本地中断。当数据在线程和中断之间共享时,需要使用这两个函数来加锁和解锁。因为中断可以打断线程的执行,试想,如果在线程中加锁的时候没有关中断,那么在临界区的时候,线程可能被中断打断,这个时候中断处理程序想要获取锁,只能死等,因为这个时候锁被线程拿着,还没有释放,这样就产生了死锁。
spin_lock_irqsave() 和 spin_unlock_irqrestore() 这两个函数也是关中断加锁和解锁开中断。不同的是,加锁的时候会保存当前的中断状态,解锁的时候会将中断恢复到加锁时的状态。
spin_lock_bh() 和 spin_unlock_bh()
关下半部加锁,解锁并开下半部。适用于线程和软中断并发的这种场景,因为软中断也可以打断线程的执行,所以线程中在加锁的同时需要关闭下半部。
| 并发场景 | 锁的选用 |
| 线程和线程 | 普通的加锁方式 没必要关中断,也没必要关软中断 |
| 线程和中断 | 关中断加锁 在线程中需要关中断加锁,在中断中可以使用普通加锁 |
| 线程和软中断 | 关下半部加锁 在线程中可以关软中断加锁,在软中断中可以使用普通加锁 |
| 中断和中断 | 在 linux 下,中断不会抢中断,所以可以使用普通的加锁方式 |
| 中断和软中断 | 关中断加锁 |
| 软中断和软中断 | 普通加锁 |
下半部并发的情况,主要考虑软中断和 tasklet。
对于软中断来说,如果数据只在软中断之间共享,那么只需要普通加锁就可以了。因为在一个 cpu 上,一个正在运行的软中断不会被另一个软中断打断,所以没有必要关下半部。线程和中断并发的时候,之所以需要在线程中关中断加锁,是因为中断可以打断线程;同样的,关下半部加锁,也是因为下半部可以抢占线程。
tasklet 与软中断不同。同一个软中断可以在多个 cpu 上并发执行,同一个 tasklet 只会在一个 cpu 上执行,所以如果数据只在一个 tasklet 中访问,那么不需要加锁。如果数据在不同的 tasklet 中共享,那么就需要加锁,普通加锁就可以,因为一个 cpu 上正在执行一个 tasklet 的时候,不会被另一个 tasklet 打断。
2.1.2 读写自旋锁
有时候,对数据的访问可以明确的分为两个场景,读和写。比如,对一个链表可能既要更新,又要查询。当更新链表时,那么更新操作是互斥的,在同一个时刻,只能有一个更新者,并且在更新的时候不能读。如果此时没有更新,而只有读者,那么多个读者是可以同时进行的。
读写自旋锁的互斥规则:
(1)写和写互斥
(2)写和读互斥
(3)读和读不互斥
自旋锁是完全互斥。在一些场景下,比如读多写少的场景,相对于使用自旋锁,读写锁可以带来性能上的优化。
读写自旋锁,在等待锁的时候也是自旋,一直占着 cpu,这点与自旋锁是类似的。
与自旋锁不同的是,读写自旋锁是可以递归调用的,也就是说一个线程调用一次之后,还可以再次调用。当然,实际使用中很少有这么用的,对于一个线程来说,重复获取一个读自旋锁,毫无意义。
如下内核模块有两个线程,一个线程中获取读锁,一个线程中获取写锁。安装内核模块之后的打印结果截图贴在了下边。从打印信息可以看出来两点:读锁可以多次获取;读锁和写锁是互斥的,只有两次释放读锁之后,写锁才可以被获取到。
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/kthread.h>
#include <linux/delay.h>
#include <linux/spinlock.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("Spinlock Example");
rwlock_t lock;
static struct task_struct *rthread;
static struct task_struct *wthread;
static int rthread_func(void *data) {
printk("rthread tid = %d\n", current->pid);
read_lock(&lock);
printk("first got read lock\n");
read_lock(&lock);
printk("second got read lock\n");
read_unlock(&lock);
printk("first release read lock\n");
mdelay(2000);
read_unlock(&lock);
printk("second release read lock\n");
return 0;
}
static int wthread_func(void *data) {
printk("wthread tid = %d\n", current->pid);
printk("getting write lock\n");
mdelay(2000);
write_lock(&lock);
printk("got write lock\n");
write_unlock(&lock);
return 0;
}
static int __init spinlock_example_init(void) {
printk(KERN_INFO "Spinlock Example: Module init\n");
rwlock_init(&lock);
rthread = kthread_run(rthread_func, NULL, "rThread");
wthread = kthread_run(wthread_func, NULL, "wThread");
return 0;
}
static void __exit spinlock_example_exit(void) {
printk(KERN_INFO "Spinlock Example: Module exit\n");
kthread_stop(rthread);
kthread_stop(wthread);
}
module_init(spinlock_example_init);
module_exit(spinlock_example_exit);

2.2 互斥体
互斥体,从名字就可以看出来能够起到互斥的作用。互斥体和自旋锁是两种典型的同步机制,分别有各自的使用场景。一个事物往往会分为两个方面,有两种实现方式,这两种方式有各自的使用场景,比如通信模型中的传输层,有 udp 和 tcp:tcp 是面向连接的可靠的字节流;而 udp 正好相反,没有连接,不可靠,数据报。udp 和 tcp 分别有各自的使用场景。
互斥体在 linux 内核中是一个 struct mutex 结构体。如下内核模块中,声明了一个互斥体 struct mutex mtx。创建了两个内核线程 thread1 和 thread2,在 thread1 中首先获取了 mtx,然后尝试再次获取 mtx,这种情况下会产生死锁,因为 mutex 不能递归调用;thread2 中首先 delay 了 2s,之所以 delay,是为了先让 thread1 获取锁,这样 thread2 尝试获取锁就会获取失败,一直等待。
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/kthread.h>
#include <linux/delay.h>
#include <linux/spinlock.h>
#include <linux/mutex.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("Spinlock Example");
struct mutex mtx;
static struct task_struct *thread1;
static struct task_struct *thread2;
static int thread1_func(void *data) {
printk("thread1 tid = %d\n", current->pid);
mutex_lock(&mtx);
printk("first got mutex\n");
mutex_lock(&mtx);
return 0;
}
static int thread2_func(void *data) {
printk("wthread tid = %d\n", current->pid);
printk("getting mutex\n");
mdelay(2000);
mutex_lock(&mtx);
return 0;
}
static int __init spinlock_example_init(void) {
printk(KERN_INFO "Spinlock Example: Module init\n");
mutex_init(&mtx);
thread1 = kthread_run(thread1_func, NULL, "Thread1");
thread2 = kthread_run(thread2_func, NULL, "Thread2");
return 0;
}
static void __exit spinlock_example_exit(void) {
printk(KERN_INFO "Spinlock Example: Module exit\n");
kthread_stop(thread1);
kthread_stop(thread2);
}
module_init(spinlock_example_init);
module_exit(spinlock_example_exit);
使用 dmesg 可以查看内核模块的打印信息,两个线程的线程号分别是 2937 和 2938。

使用 top 分别查看两个线程的状态,可以看到两个线程的状态均是 D 状态,并且 cpu 使用率为 0%。这是 mutex 和 spinlock 之间的主要区别,spinlock 在等待琐时忙等,还在占着 cpu,mutex 等待锁时睡眠。


D 状态是的说明可以参考下边的博客。
如果线程长时间处于 D 状态,那么内核也有检测机制,可以检测出来 D 状态异常并打印相关信息。

2.3 区别
2.3.1 等锁的方式不一样
如上所述,自旋锁在等待锁时是忙等,一直占着 cpu,线程状态是 R,也就是运行态;互斥体在等锁时,线程是 D 状态,线程睡眠,不占用 cpu。
2.3.2 使用场景不一样
根据自旋锁和互斥体的区别,两者有不同的适用场景。
只能使用自旋锁的场景
中断上下文。在中断上下文中使用锁,只能使用自旋锁,因为互斥体在等锁的时候会睡眠,睡眠就会引起任务调度。而在中断上下文中,是不能调度的,因为从 linux 内核的语义来说,中断本身就是最紧迫的,优先级最高的任务,需要快速完成的任务,所以中断中不能发生调度。linux 内核并不保存中断的上下文,在中断中发生调度的话,就永远无法调度回来,找不到回家的路。
在临界区需要睡眠,只能使用互斥体
如果在临界区需要睡眠,那么只能使用互斥体。因为睡眠会引起调度,如果在持有自旋锁的时候睡眠,并且新调度的任务也要获取同一个自旋锁,那么就可能产生死锁。为什么持有互斥体,不会产生死锁呢,因为等互斥体的时候线程会睡眠,睡眠的话,原来持有互斥体的线程就会有机会运行,运行完毕,释放互斥体之后,后来的线程就可以运行。而获取自旋锁的话,等锁的线程会一直占着 cpu,已经持有锁的线程可能得不到运行,也就不会释放自旋锁,这样就会死锁。之所以说可能死锁,是因为这是前后两个线程在同一个 cpu 核上运行的情况,如果两个线程在不同的 cpu 核上运行,那么已经持有锁的线程就能继续运行,运行完毕释放锁。为了避免可能的死锁问题,在自旋锁临界区,不能睡眠。
其它选择
低开销加锁,临界区很短。建议使用自旋锁,因为临界区短,所以等锁时间也会比较短,忙等一会可以接收。因为等互斥体的时候会触发调度,如果临界区很短的话,进程调度的时间会大于等锁本身需要消耗的时间,还不如把时间花在等锁上。
短期锁定,优先使用自旋锁;长期加锁,优先选用互斥体。
3 哪种锁可以递归调用
由上边的分析可以知道,读自旋锁可以递归调用。
普通自旋锁,写自旋锁,互斥体都不可以递归调用。















 3364
3364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









