






编码部分
一、CAVLC的目的:用于残差数据的熵编码
二、CAVLC的相关变量及含义:
1、TotalCoffes: 代表ZigZag扫描后序列中非0值的个数;
2、TrailingOnes: 又称做拖尾系数,代表ZigZag扫描后序列中+1,和-1的总个数,如果超过3,则为3
3、TotalZeros: 最后一个非零系数之前零的数目;
4、NC:用来决策coeff如何编码的变量;通过NC查表得到编码模型
NC的取值:
待编码数据为 色度分量的直流系数时 NC= -1
NA:表示左邻的宏块的NC值
NB:表示上邻的宏块的NC值
NA NB NC
X Y (X+Y)/2
null Y Y
X null X
null null 0
从表中可以看出NC越小,编码字越短, 根据NC的取值方法,体现了上下文自适应。
同时,TotalCoffes和TrailingOnes越大,编码字越长;TotalCoffes和TrailingOnes越大,表示数据量越大,至于为什么数据量大,采用更长的编码字,有待高手指点!
映射表如图
 5、ZerosLeft: 当前系数之前所有的0的个数
5、ZerosLeft: 当前系数之前所有的0的个数
6、 RunBefore: 紧邻当前系数的0的个数;
三、编码举例
1、编码准备
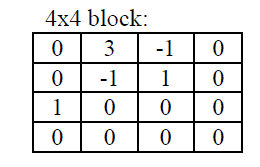
首先对其进行ZigZag扫描,得到序列
0, 3,0,1,-1,-1,0,1,0,0,0,0,0,0,0,0
很显然:TotalCoffes = 5,即扫描后序列中有5个非零值;
TraillingOnes = 3,即+1,-1的个数,从右到左分别是1, -1,-1,由于TrailingOnes最大值为3,因此为3.
TotalZeros = 3,即最后一个非零元素之前零的个数为3.
2、编码过程
编码coeff_token:
coeff_token根据TotalCoffes,TrailiingOnes以及NC而确定,NC如何确定前面有讲解,此处先假设NC = 1, 然后去查表 (标准Table 9-5),可以看到:
 从表中可以看出,coeff_token部分编码为: 0000 100
从表中可以看出,coeff_token部分编码为: 0000 100
编码Traillingones:
对于拖尾部分的编码,用0表示+1,1表示-1,根据之前的分析,拖尾部分为1, -1,-1,从右到左依次编码为011,此时编码后的序列为 0000 100 || 011
编码除拖尾以外的非零系数的level
一个level的编码=[level_prefix]+[level_suffix];
非零系数的level编码首先将非零系数从有符号变成无符号,算法如下:
如果level > 0: levelcode = (levelcode << 1) - 2 ;
如果level < 0: levelcode = -(levelcode << 1) - 1;
level_prefix的计算公式是:
level_prefix = levelcode / (1 << suffix_length),得到level_prefix后,根据level_prefix去查表如何编码
level_suffix = levelcode % (1 << suffix_length)
suffix_length:表示的是level编码后缀的长度,后缀用0填充,长度为多少就填充多少个0,初始值为0;
suffix_length后续的计算:
If ( suffix_length == 0 )
suffix_length ++;
else if ( levelcode > (3 << suffix_length - 1) && suffix_length < 6)
suffix_length++;
当level[i]的绝对值大于(3 << (suffixLength − 1 )), 并且suffixLength小于6时,suffixLength递增1,如下表:在levelcode超过levelcode阈值后,suffixlength++
当前suffixLength LevelCode阈值
0 0
1 3
2 6
3 12
4 24
5 48
6 N/A
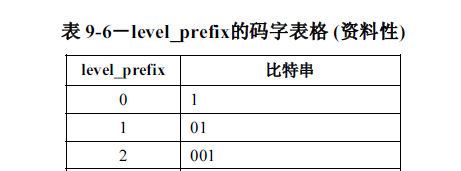
开始计算
根据前面得到的数据,除拖尾外非零系数从右到左分别为1, 3.
编码"1":
levelcode = 1 << 1 - 2 = 0;
suffix_length初始值:如果TotalCoeff( coeff_token )大于10,并且TrailingOnes( coeff_token )小于3,suffixLength等于1,否则为0
则level_prefix = 0 / (1 << 0) = 0;
查表编码为1,此时编码的序列为:0000 100 || 011 | 1
编码"3":
levelcode = 3 << 1 - 2 = 4;
根据之前的计算公式:suffix_length = 1;
则level_prefix = 4 / (1 << 1) = 2;
查表编码为001,此时的编码序列为:0000 100 || 011 | 1 | 0010
编码最后一个非零系数前的0的个数
TotalZeros = 3, TotalCoeffs = 5, 通过查下表得此部分编码为“111”,此时的编码序列为:0000 100 || 011 | 1 | 0010 | 111


 对每个非零系数前零的个数进行编码
对每个非零系数前零的个数进行编码
run_before:每个非零系数前零的个数(直接相邻0的个数,不是所有零的个数)
原始数据为:0, 3,0,1,-1,-1,0,1,0,0,0,0,0,0,0,0
整个序列中非零的系数按照ZigZag逆序分别为 1, -1, -1, 1, 3,分别编码。
对1编码: zerosLeft = 3, run_before = 1,查下表, 编码为“10”;
对-1编码: zerosLeft = 2, run_before = 0, 查下表,编码为“1”;
对-1编码: zerosLeft = 2, run_before = 0, 查下表,编码为“1”
对1编码: zerosLeft = 2, rub_before = 1,查下表, 编码为“01”
对3编码: zerosLeft = 1, run_before = 1, 查下表,最后一个元素不需要编码。
此时编码的序列为: 0000 100 | 011 | 1 | 0010 | 111 | 101101 =0000 1000 1110 0101 1110 1101

解码部分
out=0000 1000 1110 0101 1110 1101
1、解码TotalCoeffs和TrailingOnes:
初始NC=1,根据表9-5,可以从0000100中解码得到TotalCoeffs=5;TrailingOnes=3。这里因为表9-5的编码可以及时、唯一译码,所以遇到的第一个合法的01串就是TotalCoeffs和TrailingOnes编码的结果。
2、解码拖尾系数:此时out = 0 1110 0101 1110 1101
由TrailingOnes=3知,有3个拖尾系数,所以对应的正负号编码为011,所以3个拖尾系数是1,-1,-1。所以解码输出 in是 -1,-1,1(因为编码是逆序的)。
3、解码除拖尾系数外的非零系数:此时out = 10 0101 1110 1101
由TotalCoeffs=5;TrailingOnes=3知除拖尾系数外,还有两个非零系数。初始SuffixLength=0,所以根据表9-6(及时、唯一译码)解码如下:
SuffixLength=0 查表得比特串为1,level_prefix=0,LevelCode=0(偶数),Level=1,没有Level_suffix;(消耗码流0)
SuffixLength=1 查表得比特串为001,level_prefix=2,LevelCode=4(偶数),Level=3,Level_suffix=0;(消耗码流0010)
所以输出 in是 3,1,-1,-1,1
4、解码每个非零系数前0的个数:此时out = 1 1110 1101
TotalCoeffs = 5;根据表9-7解码得 TotalZeros=3,对应码流:111。
然后查表9-10,得到每一个非零系数前连续0的个数,过程如下:此时out = 10 1101
TotalZeros=3,根据码流查表得10对应 RunBefore=1,in是 3,1,-1,-1,0,1
TotalZeros=3-1=2,根据码流查表得1对应 RunBefore=0,in是 3,1,-1,-1,0,1
TotalZeros=2-0=2,根据码流查表得1对应 RunBefore=0,in是 3,1,-1,-1,0,1
TotalZeros=2-0=2,根据码流查表得01对应 RunBefore=1,in是 3,0,1,-1,-1,0,1
TotalZeros=2-1=1,out码流解码完,所以TotalZeros=1表示3之前的0数目,in是 0,3,1,-1,-1,0,1
然后在结尾补0组成16个残差系数,得解码结果0,3,1,-1,-1,0,1,0,0,0,0,0,0,0,0,0
可以看到只要确定了TotalCoeffs和TrailingOnes的值,解码比较容易,但是说到底,没有看出节约码流的原因,与哈夫曼和算术编码相比,熵编码节省码流的效率
x264代码cavlc解析:
x264_slice_write函数中写入数据部分的code如下:
if( IS_SKIP( h->mb.i_type ) )
{
if( h->param.b_cabac )
{
if( mb_xy > 0 )
{
/* not end_of_slice_flag */
x264_cabac_encode_terminal( &h->cabac, 0 );
}
x264_cabac_mb_skip( h, 1 );
}
else
{
i_skip++;
}
}
else
{
if( h->param.b_cabac )
{
if( mb_xy > 0 )
{
/* not end_of_slice_flag */
x264_cabac_encode_terminal( &h->cabac, 0 );
}
if( h->sh.i_type != SLICE_TYPE_I )
{
x264_cabac_mb_skip( h, 0 );
}
x264_macroblock_write_cabac( h, &h->out.bs );
}
else
{
if( h->sh.i_type != SLICE_TYPE_I )
{
bs_write_ue( &h->out.bs, i_skip ); /* skip run,根据h264手册,在slice_data中mb_skip_run,表示连续宏块个数 */
i_skip = 0;
}
x264_macroblock_write_cavlc( h, &h->out.bs );
}
}
TIMER_STOP( i_mtime_write );
write_cavlc
x264_macroblock_write_cavlc
void x264_macroblock_write_cavlc( x264_t *h, bs_t *s )
{
const int i_mb_type = h->mb.i_type;
int i_mb_i_offset;
int i;
switch( h->sh.i_type )
{
case SLICE_TYPE_I:
i_mb_i_offset = 0; //根据h264手册可知,I帧的mb_type偏移量为0
break;
case SLICE_TYPE_P:
i_mb_i_offset = 5; //P帧的mb_type偏移量为5
break;
case SLICE_TYPE_B:
i_mb_i_offset = 23; //B帧的mb_type偏移量为23
break;
default:
fprintf( stderr, "internal error or slice unsupported\n" );
return;
}
/* Write:
- type
- prediction
- mv */
/*接下来的部分需要参考h264语法macroblock_layer()语法*/
if( i_mb_type == I_PCM )/PCM表示不编码,复制原始像素
{
/* Untested */
bs_write_ue( s, i_mb_i_offset + 25 );//根据语法可知,写入mb_type
bs_align_0( s );//然后字节对齐,因为是按位写的,可能一个字节8位还没写完
/* Luma */
for( i = 0; i < 16*16; i++ )//写入luma
{
bs_write( s, 8, h->picture->plane[0][h->mb.i_mb_y * 16 * h->picture->i_stride[0] + h->mb.i_mb_x * 16+i] );
}
/* Cb */
for( i = 0; i < 8*8; i++ )
{
bs_write( s, 8, h->picture->plane[1][h->mb.i_mb_y * 8 * h->picture->i_stride[1] + h->mb.i_mb_x * 8+i] );
}
/* Cr */
for( i = 0; i < 8*8; i++ )
{
bs_write( s, 8, h->picture->plane[2][h->mb.i_mb_y * 8 * h->picture->i_stride[2] + h->mb.i_mb_x * 8+i] );
}
return;
}
else if( i_mb_type == I_4x4 )//此时进入mb_pred( mb_type )部分
{
bs_write_ue( s, i_mb_i_offset + 0 );
/* Prediction: Luma */
for( i = 0; i < 16; i++ )
{
int i_pred = x264_mb_predict_intra4x4_mode( h, i ); //获取当前宏块左或右中较小值,该值可能为当前宏块的预测模式,那么就不用了再传预测模式了
int i_mode = h->mb.cache.intra4x4_pred_mode[x264_scan8[i]];//获取当前的预测模式
if( i_pred == i_mode)//如果相等,就不用在传输了,写1即可
{
bs_write1( s, 1 ); /* b_prev_intra4x4_pred_mode *///放入16个4x4宏块的预测模式
}
else//如果不相等,需要进行编码
{
bs_write1( s, 0 ); /* b_prev_intra4x4_pred_mode */
if( i_mode < i_pred )
{
bs_write( s, 3, i_mode );//花费3位写入帧内预测模式
}
else
{
bs_write( s, 3, i_mode - 1 );
}
}
}
bs_write_ue( s, h->mb.i_chroma_pred_mode );//I4X4预测模式由9种,色度的帧内预测模式只有4种,不需要用到上面的方案,直接写入即可
}
else if( i_mb_type == I_16x16 )
{
bs_write_ue( s, i_mb_i_offset + 1 + h->mb.i_intra16x16_pred_mode +
h->mb.i_cbp_chroma * 4 + ( h->mb.i_cbp_luma == 0 ? 0 : 12 ) );//写入16x16的mb_type
bs_write_ue( s, h->mb.i_chroma_pred_mode );
}
else if( i_mb_type == P_L0 )
{
int mvp[2];
if( h->mb.i_partition == D_16x16 )
{
bs_write_ue( s, 0 );//P_L0_16X16宏块类型对应0
if( h->sh.i_num_ref_idx_l0_active > 1 )//如果i_num_ref_idx_l0_active指明参考队列长度
{
bs_write_te( s, h->sh.i_num_ref_idx_l0_active - 1, h->mb.cache.ref[0][x264_scan8[0]] );//写入当前宏块的参考帧
}
x264_mb_predict_mv( h, 0, 0, 4, mvp );//首先获取到参考帧的mv
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[0]][0] - mvp[0] );//然后将当前宏块的mvp减去参考帧的mvp,得到mvd,即运动矢量残差值
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[0]][1] - mvp[1] );
}
else if( h->mb.i_partition == D_16x8 )
{
bs_write_ue( s, 1 );//P_L0_16X8宏块类型对应1
if( h->sh.i_num_ref_idx_l0_active > 1 )
{
bs_write_te( s, h->sh.i_num_ref_idx_l0_active - 1, h->mb.cache.ref[0][x264_scan8[0]] );//分别写入两个16x8宏块的参考帧
bs_write_te( s, h->sh.i_num_ref_idx_l0_active - 1, h->mb.cache.ref[0][x264_scan8[8]] );
}
x264_mb_predict_mv( h, 0, 0, 4, mvp );//计算第一个16x8宏块的参考帧的mvp,根据预测值减去mvp得到mvd,并写入码流
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[0]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[0]][1] - mvp[1] );
x264_mb_predict_mv( h, 0, 8, 4, mvp );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[8]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[8]][1] - mvp[1] );
}
else if( h->mb.i_partition == D_8x16 )//与16x8类似
{
bs_write_ue( s, 2 );//P_L0_8X16宏块类型对应2
if( h->sh.i_num_ref_idx_l0_active > 1 )
{
bs_write_te( s, h->sh.i_num_ref_idx_l0_active - 1, h->mb.cache.ref[0][x264_scan8[0]] );
bs_write_te( s, h->sh.i_num_ref_idx_l0_active - 1, h->mb.cache.ref[0][x264_scan8[4]] );
}
x264_mb_predict_mv( h, 0, 0, 2, mvp );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[0]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[0]][1] - mvp[1] );
x264_mb_predict_mv( h, 0, 4, 2, mvp );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4]][1] - mvp[1] );
}
}
else if( i_mb_type == P_8x8 )//如果是8x8,此时进入sub_mb_pred( mb_type )部分
{
int b_sub_ref0;
if( h->mb.cache.ref[0][x264_scan8[0]] == 0 && h->mb.cache.ref[0][x264_scan8[4]] == 0 &&
h->mb.cache.ref[0][x264_scan8[8]] == 0 && h->mb.cache.ref[0][x264_scan8[12]] == 0 )
{
bs_write_ue( s, 4 );//P_8X8ref0宏块类型对应4,即4个8x8宏块的参考帧都是0
b_sub_ref0 = 0;
}
else
{
bs_write_ue( s, 3 );//P_8X8宏块类型对应3
b_sub_ref0 = 1;
}
/* sub mb type */
for( i = 0; i < 4; i++ )
{
switch( h->mb.i_sub_partition[i] )//接下来是8x8宏块的4个4x4宏块,对应语法sub_mb_type[ mbPartIdx ] 2 ue(v) | ae(v)
{
case D_L0_8x8:
bs_write_ue( s, 0 );
break;
case D_L0_8x4:
bs_write_ue( s, 1 );
break;
case D_L0_4x8:
bs_write_ue( s, 2 );
break;
case D_L0_4x4:
bs_write_ue( s, 3 );
break;
}
}
/* ref0 */
if( h->sh.i_num_ref_idx_l0_active > 1 && b_sub_ref0 )//b_sub_ref0=1时,表示不是P_8X8ref0,4个8x8宏块使用的参考帧索引,对应语法ref_idx_l0[ mbPartIdx ] 2 te(v) | ae(v)
{
bs_write_te( s, h->sh.i_num_ref_idx_l0_active - 1, h->mb.cache.ref[0][x264_scan8[0]] );
bs_write_te( s, h->sh.i_num_ref_idx_l0_active - 1, h->mb.cache.ref[0][x264_scan8[4]] );
bs_write_te( s, h->sh.i_num_ref_idx_l0_active - 1, h->mb.cache.ref[0][x264_scan8[8]] );
bs_write_te( s, h->sh.i_num_ref_idx_l0_active - 1, h->mb.cache.ref[0][x264_scan8[12]] );
}
for( i = 0; i < 4; i++ )
{
int mvp[2];
switch( h->mb.i_sub_partition[i] )//前面获取了8x8宏块的参考帧,接下来计算mvd,使用mvd也可以节省码流
{
case D_L0_8x8:
x264_mb_predict_mv( h, 0, 4*i, 2, mvp );//获取起始mvp,然后预测运动矢量mv-起始运动矢量mvp得到mvd,节省码流
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i]][1] - mvp[1] );
break;
case D_L0_8x4: //分别写入两个8x4的运动矢量
x264_mb_predict_mv( h, 0, 4*i+0, 2, mvp );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i]][1] - mvp[1] );
x264_mb_predict_mv( h, 0, 4*i+2, 2, mvp );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i+2]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i+2]][1] - mvp[1] );
break;
case D_L0_4x8:
x264_mb_predict_mv( h, 0, 4*i+0, 1, mvp );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i]][1] - mvp[1] );
x264_mb_predict_mv( h, 0, 4*i+1, 1, mvp );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i+1]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i+1]][1] - mvp[1] );
break;
case D_L0_4x4:
x264_mb_predict_mv( h, 0, 4*i+0, 1, mvp );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i]][1] - mvp[1] );
x264_mb_predict_mv( h, 0, 4*i+1, 1, mvp );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i+1]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i+1]][1] - mvp[1] );
x264_mb_predict_mv( h, 0, 4*i+2, 1, mvp );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i+2]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i+2]][1] - mvp[1] );
x264_mb_predict_mv( h, 0, 4*i+3, 1, mvp );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i+3]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[0][x264_scan8[4*i+3]][1] - mvp[1] );
break;
}
}
}
else if( i_mb_type == B_8x8 ) //当前x264不支持B8x8,因此B帧的语法都在mb_pred( mb_type )中
{
fprintf( stderr, "invalid/unhandled mb_type (B_8x8)\n" );
return;
}
else if( i_mb_type != B_DIRECT )
{
/* All B mode */
/* Motion Vector */
int i_list;
int mvp[2];
int b_list[2][2];
/* init ref list utilisations */
for( i = 0; i < 2; i++ )
{
b_list[0][i] = x264_mb_type_list0_table[i_mb_type][i];//b_list[0]表示list0参考帧,i表示第i个子宏块,当前的x264 B帧只支持16x16,16x8和8x16,不支持8x8,所以数组变量为2
b_list[1][i] = x264_mb_type_list1_table[i_mb_type][i];
}
if( h->mb.i_partition == D_16x16 )//这部分可参考H264文档中,B片中的mb_type
{
if( b_list[0][0] && b_list[1][0] )//如果16x16宏块,在list0和list1中都有参考帧
{
bs_write_ue( s, 3 );//宏块类型B_Bi_16x16对应值为3
}
else if( b_list[1][0] )//宏块类型B_L1_16x16对应值为2
{
bs_write_ue( s, 2 );
}
else //宏块类型B_L0_16x16对应值为2
{
bs_write_ue( s, 1 );
}
}
else
{
if( i_mb_type == B_BI_BI )//双向预测,即最佳pre_L0和pre_L1预测值的平均值作为预测值
{
bs_write_ue( s, 20 + (h->mb.i_partition == D_16x8 ? 0 : 1 ) );
}
else if( b_list[0][0] && b_list[1][0] )
{
/* B_BI_LX* */
bs_write_ue( s, 16 + (b_list[0][1]?0:2) + (h->mb.i_partition == D_16x8?0:1) );
}
else if( b_list[0][1] && b_list[1][1] )
{
/* B_LX_BI */
bs_write_ue( s, 12 + (b_list[0][1]?0:2) + (h->mb.i_partition == D_16x8?0:1) );
}
else if( b_list[1][1] )
{
/* B_LX_L1 */
bs_write_ue( s, 6 + (b_list[0][0]?2:0) + (h->mb.i_partition == D_16x8?0:1) );
}
else if( b_list[0][1] )
{
/* B_LX_L0 */
bs_write_ue( s, 4 + (b_list[0][0]?0:6) + (h->mb.i_partition == D_16x8?0:1) );
}
}
/*以上完成mb_type的码流写入,接下来是参考帧的写入,最后是mvd的写入,这些都是在宏块layout语法层*/
for( i_list = 0; i_list < 2; i_list++ )//写入list0和list1的参考帧
{
const int i_ref_max = i_list == 0 ? h->sh.i_num_ref_idx_l0_active : h->sh.i_num_ref_idx_l1_active;
if( i_ref_max > 1 )
{
switch( h->mb.i_partition )
{
case D_16x16:
if( b_list[i_list][0] ) bs_write_te( s, i_ref_max - 1, h->mb.cache.ref[i_list][x264_scan8[0]] );
break;
case D_16x8:
if( b_list[i_list][0] ) bs_write_te( s, i_ref_max - 1, h->mb.cache.ref[i_list][x264_scan8[0]] );
if( b_list[i_list][1] ) bs_write_te( s, i_ref_max - 1, h->mb.cache.ref[i_list][x264_scan8[8]] );
break;
case D_8x16:
if( b_list[i_list][0] ) bs_write_te( s, i_ref_max - 1, h->mb.cache.ref[i_list][x264_scan8[0]] );
if( b_list[i_list][1] ) bs_write_te( s, i_ref_max - 1, h->mb.cache.ref[i_list][x264_scan8[4]] );
break;
}
}
}
for( i_list = 0; i_list < 2; i_list++ )//然后写入mvd
{
switch( h->mb.i_partition )
{
case D_16x16:
if( b_list[i_list][0] )
{
x264_mb_predict_mv( h, i_list, 0, 4, mvp );
bs_write_se( s, h->mb.cache.mv[i_list][x264_scan8[0]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[i_list][x264_scan8[0]][1] - mvp[1] );
}
break;
case D_16x8:
if( b_list[i_list][0] )
{
x264_mb_predict_mv( h, i_list, 0, 4, mvp );
bs_write_se( s, h->mb.cache.mv[i_list][x264_scan8[0]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[i_list][x264_scan8[0]][1] - mvp[1] );
}
if( b_list[i_list][1] )
{
x264_mb_predict_mv( h, i_list, 8, 4, mvp );
bs_write_se( s, h->mb.cache.mv[i_list][x264_scan8[8]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[i_list][x264_scan8[8]][1] - mvp[1] );
}
break;
case D_8x16:
if( b_list[i_list][0] )
{
x264_mb_predict_mv( h, i_list, 0, 2, mvp );
bs_write_se( s, h->mb.cache.mv[i_list][x264_scan8[0]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[i_list][x264_scan8[0]][1] - mvp[1] );
}
if( b_list[i_list][1] )
{
x264_mb_predict_mv( h, i_list, 4, 2, mvp );
bs_write_se( s, h->mb.cache.mv[i_list][x264_scan8[4]][0] - mvp[0] );
bs_write_se( s, h->mb.cache.mv[i_list][x264_scan8[4]][1] - mvp[1] );
}
break;
}
}
}
else if( i_mb_type == B_DIRECT )
{
bs_write_ue( s, 0 );
}
else
{
fprintf( stderr, "invalid/unhandled mb_type\n" );
return;
}
/* Coded block pattern 接下来编码pattern,I16x16的pattern在mb_type中,因此以下内容不包含I16x16*/
if( i_mb_type == I_4x4 )
{
bs_write_ue( s, intra4x4_cbp_to_golomb[( h->mb.i_cbp_chroma << 4 )|h->mb.i_cbp_luma] );//对应语法coded_block_pattern [2 me|ae]
}
else if( i_mb_type != I_16x16 )
{
bs_write_ue( s, inter_cbp_to_golomb[( h->mb.i_cbp_chroma << 4 )|h->mb.i_cbp_luma] );
}
/* write residual */
if( i_mb_type == I_16x16 )
{
bs_write_se( s, h->mb.qp[h->mb.i_mb_xy] - h->mb.i_last_qp );//写入qp值
/*redsidual()中的语法*/
/* DC Luma */
/*开始残差数据的编码*/
block_residual_write_cavlc( h, s, BLOCK_INDEX_LUMA_DC , h->dct.luma16x16_dc, 16 );然后是1个4x4矩阵的DC系数
if( h->mb.i_cbp_luma != 0 )
{
/* AC Luma */
for( i = 0; i < 16; i++ )
{
block_residual_write_cavlc( h, s, i, h->dct.block[i].residual_ac, 15 );//然后是16个4x4宏块的AC系数
}
}
}
else if( h->mb.i_cbp_luma != 0 || h->mb.i_cbp_chroma != 0 )
{
bs_write_se( s, h->mb.qp[h->mb.i_mb_xy] - h->mb.i_last_qp );
for( i = 0; i < 16; i++ )
{
if( h->mb.i_cbp_luma & ( 1 << ( i / 4 ) ) )
{
block_residual_write_cavlc( h, s, i, h->dct.block[i].luma4x4, 16 );
}
}
}
/*色度块*/
if( h->mb.i_cbp_chroma != 0 )
{
/* Chroma DC residual present */
block_residual_write_cavlc( h, s, BLOCK_INDEX_CHROMA_DC, h->dct.chroma_dc[0], 4 );
block_residual_write_cavlc( h, s, BLOCK_INDEX_CHROMA_DC, h->dct.chroma_dc[1], 4 );
if( h->mb.i_cbp_chroma&0x02 ) /* Chroma AC residual present */
{
for( i = 0; i < 8; i++ )
{
block_residual_write_cavlc( h, s, 16 + i, h->dct.block[16+i].residual_ac, 15 );
}
}
}
}
static void block_residual_write_cavlc( x264_t *h, bs_t *s, int i_idx, int *l, int i_count )
{
int level[16], run[16];
int i_total, i_trailing;
int i_total_zero;
int i_last;
unsigned int i_sign;
int i;
int i_zero_left;
int i_suffix_length;
/* first find i_last */
i_last = i_count - 1;
while( i_last >= 0 && l[i_last] == 0 )//从尾部往前,直到遇到非零系数
{
i_last--;
}
i_sign = 0;
i_total = 0;
i_trailing = 0;
i_total_zero = 0;
if( i_last >= 0 )
{
int b_trailing = 1;//拖尾系数的判断标志,为1表示当前处理拖尾系数,否则当前处理除拖尾系数外的非零系数
int idx = 0;
/* level and run and total */
while( i_last >= 0 )
{
level[idx] = l[i_last--];//保存非零系数的值
run[idx] = 0;
while( i_last >= 0 && l[i_last] == 0 )
{
run[idx]++;//run保存当前非零系数前连续0的个数
i_last--;
}
i_total++;//保存非0值的个数
i_total_zero += run[idx];//保存第一个非零系数前0的个数
if( b_trailing && abs( level[idx] ) == 1 && i_trailing < 3 )
{
i_sign <<= 1;
if( level[idx] < 0 )
{
i_sign |= 0x01;//保存trailing_ones_sign_flag
}
i_trailing++;//拖尾系数
}
else
{
b_trailing = 0;
}
idx++;
}
}
/* total/trailing */
/*首先根据TotalCoeff(非0值的个数)和TrailingOnes(拖尾系数)和NC值进行编码*/
/*色度的直流系数 NC=-1*/
if( i_idx == BLOCK_INDEX_CHROMA_DC )
{
bs_write_vlc( s, x264_coeff_token[4][i_total*4+i_trailing] );//x264_coeff_token的5个数组对应表9-5 5种不同NC的编码值,根据表9-5,NC=-1时,x264_coeff_token[4]
}
else/*其他系数类型NC值是根据当前块左边4*4 块的非零系数数目NA当前块上面4*4块的非零系数数目NB求得的*/
{
/* x264_mb_predict_non_zero_code return 0 <-> (16+16+1)>>1 = 16 */
static const int ct_index[17] = {0,0,1,1,2,2,2,2,3,3,3,3,3,3,3,3,3 };//NC值
int nC;
if( i_idx == BLOCK_INDEX_LUMA_DC )
{
nC = x264_mb_predict_non_zero_code( h, 0 );//对于亮度DC,NC值由第一个宏块的左侧宏块和上侧宏块求出
}
else
{
nC = x264_mb_predict_non_zero_code( h, i_idx );//i_idx表示16个16x16宏块的索引,根据索引求取NC值
}
bs_write_vlc( s, x264_coeff_token[ct_index[nC]][i_total*4+i_trailing] );
}
if( i_total <= 0 )
{
return;
}
/*编码除拖尾系数外的非零系数*/
i_suffix_length = i_total > 10 && i_trailing < 3 ? 1 : 0;
if( i_trailing > 0 )
{
bs_write( s, i_trailing, i_sign );
}
for( i = i_trailing; i < i_total; i++ )
{
int i_level_code;
/* calculate level code */
if( level[i] < 0 )
{
i_level_code = -2*level[i] - 1;
}
else /* if( level[i] > 0 ) */
{
i_level_code = 2 * level[i] - 2;
}
if( i == i_trailing && i_trailing < 3 )
{
i_level_code -=2; /* as level[i] can't be 1 for the first one if i_trailing < 3 */
}
if( ( i_level_code >> i_suffix_length ) < 14 )
{
bs_write_vlc( s, x264_level_prefix[i_level_code >> i_suffix_length] );
if( i_suffix_length > 0 )
{
bs_write( s, i_suffix_length, i_level_code );
}
}
else if( i_suffix_length == 0 && i_level_code < 30 )
{
bs_write_vlc( s, x264_level_prefix[14] );
bs_write( s, 4, i_level_code - 14 );
}
else if( i_suffix_length > 0 && ( i_level_code >> i_suffix_length ) == 14 )
{
bs_write_vlc( s, x264_level_prefix[14] );
bs_write( s, i_suffix_length, i_level_code );
}
else
{
bs_write_vlc( s, x264_level_prefix[15] );
i_level_code -= 15 << i_suffix_length;
if( i_suffix_length == 0 )
{
i_level_code -= 15;
}
if( i_level_code >= ( 1 << 12 ) || i_level_code < 0 )
{
fprintf( stderr, "OVERFLOW levelcode=%d\n", i_level_code );
}
bs_write( s, 12, i_level_code ); /* check overflow ?? */
}
if( i_suffix_length == 0 )
{
i_suffix_length++;
}
if( abs( level[i] ) > ( 3 << ( i_suffix_length - 1 ) ) && i_suffix_length < 6 )
{
i_suffix_length++;
}
}
/*编码最后一个非零系数前的0的个数*/
if( i_total < i_count )//i_total为非零值的总个数
{
if( i_idx == BLOCK_INDEX_CHROMA_DC )//H264手册请查表9-9
{
bs_write_vlc( s, x264_total_zeros_dc[i_total-1][i_total_zero] );//第一个非零值前0的个数
}
else
{
bs_write_vlc( s, x264_total_zeros[i_total-1][i_total_zero] );//请查表9-7和表9-8
}
}
/*对每个非零系数前零的个数进行编码*/
for( i = 0, i_zero_left = i_total_zero; i < i_total - 1; i++ )
{
int i_zl;
if( i_zero_left <= 0 )
{
break;
}
i_zl = X264_MIN( i_zero_left - 1, 6 );
bs_write_vlc( s, x264_run_before[i_zl][run[i]] );//参考表9-10
i_zero_left -= run[i];
}
}
/*I4X4编码*/
考虑一下预测模式的传递,16x16宏块可能是Intra_16x16类型,也可能是Intra_4x4类型,
后者会导致大量比特的占用,我们要把这两种类型分开表述与编码,对于Intra_4x4类型,
将预测模式信息单独编码,也就是在mb_pred句法中表述,单独编码可能减少不了多少比特,
因此,我们采用一种技术来节省子块预测模式的编码比特:不直接对子块预测模式进行编码,
而是进行预测。正如章节2所述,Intra_4x4宏块的预测模式有9种,且预测模式与该子块的上方与左方宏块具有强相关性,
采用某种映射关系,根据上方与左方宏块的预测模式来推导当前块的预测模式,
这样,我们甚至连1个比特都不用就可以表述当前Intra_4x4宏块的预测模式了,
想想我们可以节省16x4=64个比特,这实在是太棒了!不过转念一想,
并不是每个Intra_4x4宏块的预测模式都可以被预测的,如果是这样,
那我们就单独为这个不能被预测的Intra_4x4宏块指定预测模式。这一策略下,
只要大部分Intra_4x4宏块的预测模式能够被预测,那我们可以节省好多个比特来表述与编码Intra_4x4宏块的预测模式。
因此,我们可以看到[表4 宏块预测语义]中有prev_intra4x4_pred_mode_flag[luma4x4BlkIdx]、
rem_intra4x4_pred_mode[luma4x4BlkIdx]以及intra_chroma_pred_mode字段,
句法元素prev_intra4x4_pred_mode_flag用来指明帧内预测中亮度分量的预测模式的预测值是否是实际预测模式,
如果是,就不需要另外传预测模式,如果不是,就由rem_intra4x4_pred_mode指定实际预测模式。
实际上,由于色度预测模式只有4种,只需要2个比特表述,因此色度预测模式不进行预测,
intra_chroma_pred_mode在帧内预测时直接指定色度的预测模式。
拖尾系数外的非0系数(level)的编码过程,这个比较麻烦,单独拿出来讲解
语法部分:
语法是已知level_prefix和level_suffix推导levelcode,然后根据levelcode计算下一个循环的level_prefix和level_suffix,该语法flow可理解为解码过程
但是在编码时,我们只知道level的值,该语法可能不太清晰描述如何编码
for( i = 0; i < TotalCoeff( coeff_token ); i++ )//TotalCoeff表示字串所有非0的个数
if( i < TrailingOnes( coeff_token ) ) {//TrailingOnes表示拖尾系数,即-1和+1的个数,TrailingOnes表示的最大值为3;编码拖尾系数
trailing_ones_sign_flag [3 | 4 u(1)] //拖尾系数的符号;trailing_ones_sign_flag = 0,相应的拖尾系数是+1;trailing_ones_sign_flag =1,相应的拖尾系数是-1;通过该参考可以得到拖尾洗漱
level[ i ] = 1 – 2 * trailing_ones_sign_flag//保存拖尾系数的值
} else {//编码除去拖尾系数的非零系数
level_prefix [3 | 4 ce(v)] //非零系数的幅值(Levels)的组成分为两个部分,前缀(level_prefix)和后缀(level_suffix)。
levelCode = ( level_prefix << suffixLength ) //Level-prefix = LevelCode / (1 << SuffixLength)
if( suffixLength > 0 | | level_prefix >= 14 ) {
level_suffix [3 | 4 u(v)] //Level-suffix = LevelCode % (1 << SuffixLength)
levelCode += level_suffix
}
if( level_prefix = = 15 && suffixLength = = 0 )
levelCode += 15
if( i = = TrailingOnes( coeff_token ) &&
TrailingOnes( coeff_token ) < 3 )
levelCode += 2
if( levelCode % 2 = = 0 ) //正数level映射到偶数,负数level映射到奇数
level[ i ] = ( levelCode + 2 ) >> 1
else
level[ i ] = ( –levelCode – 1 ) >> 1
if( suffixLength = = 0 )
suffixLength = 1
if( Abs( level[ i ] ) > ( 3 << ( suffixLength – 1 ) ) &&
suffixLength < 6 ) //当level[ i ]的绝对值大于 ( 3 << ( suffixLength ? 1 ) ) ,并且suffixLength小于6时,suffixLength递增1。
suffixLength++
}
条件1:如果此时发现suffixlength=0,level_prefix=14,那么认为level_suffix是4位(而不是0位)。
条件2:如果此时发现level_prefix=15,那么认为level_suffix是12位的。
条件3:如果此时发现suffixlength=0,level_prefix=15,那么经过使用公式levelcode= (level_prefix<<suffixlength)+level_suffix得到的levelcode还需要再加上15
x264代码:
i_suffix_length = i_total > 10 && i_trailing < 3 ? 1 : 0;
for( i = i_trailing; i < i_total; i++ )
{
int i_level_code;
/* calculate level code */
if( level[i] < 0 )//level中保存了非零系数的值
{
i_level_code = -2*level[i] - 1;//level正数对应i_level_code的偶数,负数对应i_level_code的奇数
}
else /* if( level[i] > 0 ) */
{
i_level_code = 2 * level[i] - 2;
}
if( i == i_trailing && i_trailing < 3 )
{
i_level_code -=2; /* as level[i] can't be 1 for the first one if i_trailing < 3 */
}
/*当前if语句包含i_suffix_length为任意值及level_prefix<14的情况*/
if( ( i_level_code >> i_suffix_length ) < 14 )//实际上level_prefix = i_level_code >> i_suffix_length,即i_level_code >> i_suffix_length<4
{
bs_write_vlc( s, x264_level_prefix[i_level_code >> i_suffix_length] );//写入level_prefix = i_level_code >> i_suffix_length
if( i_suffix_length > 0 )
{
bs_write( s, i_suffix_length, i_level_code );//写入Level-suffix = LevelCode % (1 << SuffixLength)
}
}
/*当前else if包含level_prefix=14,i_suffix_length=0的情况*/
else if( i_suffix_length == 0 && i_level_code < 30 )//此时,Level-prefix>15, Level-suffix = LevelCode % (1 << SuffixLength);Level-prefix = LevelCode / (1 << SuffixLength)
{
bs_write_vlc( s, x264_level_prefix[14] );//固定level_prefix=14,写入level_prefix
bs_write( s, 4, i_level_code - 14 );//与语法部分的条件1对应,写入level_suffix,一共4位,29-14<16,刚好可以用4位表示
}
/*包含当前else if包含level_prefix=14,i_suffix_length>0的情况*/
else if( i_suffix_length > 0 && ( i_level_code >> i_suffix_length ) == 14 )
{
bs_write_vlc( s, x264_level_prefix[14] );//写入level_prefix
bs_write( s, i_suffix_length, i_level_code );//写入level_suffix,Level-suffix = LevelCode % (1 << SuffixLength)
}
/*其他情况*/
else
{
bs_write_vlc( s, x264_level_prefix[15] );固定level_prefix=15,与语法条件(2)和(3)对应,12位存放最大值为4096,level_code的最大值不会超过该值,像素残差最大值为256,level_code最大为512
i_level_code -= 15 << i_suffix_length;
if( i_suffix_length == 0 )对应条件(3)
{
i_level_code -= 15;
}
if( i_level_code >= ( 1 << 12 ) || i_level_code < 0 )
{
fprintf( stderr, "OVERFLOW levelcode=%d\n", i_level_code );
}
bs_write( s, 12, i_level_code ); /* check overflow ?? */
}
if( i_suffix_length == 0 )
{
i_suffix_length++;
}
if( abs( level[i] ) > ( 3 << ( i_suffix_length - 1 ) ) && i_suffix_length < 6 )
{
i_suffix_length++;
}
}
当level[i]的绝对值大于(3 << (suffixLength − 1 )), 并且suffixLength小于6时,suffixLength递增1,如下表:
当前suffixLength LevelCode
0 0
1 3
2 6
3 12
4 24
5 48
6 N/A
/*这部分是除拖尾系数外的非零系数的编码方法,这部分比较复杂,单独拿出来讲*/
根据之前分析,
其中前缀的码值需要根据level_prefix的值去参照标准中的表9-6,后缀的码值就是level_suffix的二进制
h264官方手册的解码过程如下,根据解码过程,我们可以逆推出编码过程(编码过程并不是唯一的):
按照结尾变换系数幅值的解码,变量suffixLength的初始化过程如下:
(1)
— 如果TotalCoeff( coeff_token )大于10,并且TrailingOnes( coeff_token )小于3,suffixLength等于1。
— 否则 (TotalCoeff( coeff_token )小于或等于 10,或者TrailingOnes( coeff_token )等于3),suffixLength
等于0。
(2)
— 除以下两种情况外,变量levelSuffixSize等于变量suffixLength。
— 当level_prefix 等于14 且suffixLength等于 0时,levelSuffixSize 等于 4。(x264下直接固定level_prefix=14,levelSuffixSize=4,编码levelcode 范围[15 30),实际上levelode[15,30)对应±8,±9...±15的level值(非零系数的值))
— 当level_prefix大于等于15时,levelSuffixSize等于 level_prefix − 3。(x264下直接固定level_prefix=15,levelSuffixSize=12,12位最大值为4096,像素残差值最大为256,12位完全能满足该要求)
(3)
— 语法元素level_suffix 的解码如下:
— 如果levelSuffixSize大于0,语法元素level_suffix的解码使用levelSuffixSize比特的无符号整
数u(v)表示。
— 否则(levelSuffixSize 等于0),语法元素level_suffix 应该为0。
可知,level_suffix由levelSuffixSize产生,由于(2)中的描述,除了两个条件外levelSuffixSize=level_prefix。
(4)
— 变量levelCode等于( Min( 15, level_prefix ) << suffixLength ) + level_suffix。
— 当level_prefix 大于等于15,并且suffixLength等于0时,levelCode 递增15。
— 当level_prefix大于等于16时,levelCode递增(1<<( level_prefix − 3 )) − 4096。//x264没有用到这一项
(5)
— 当索引i 等于TrailingOnes( coeff_token ) ,并且TrailingOnes( coeff_token )小于3时,levelCode递增2。
(6)
— 变量level[ i ]按照如下步骤推导:
— 如果levelCode是偶数,赋( levelCode + 2 ) >> 1给level[ i ]。
— 否则 (levelCode是一个奇数),赋( −levelCode − 1) >> 1给level[ i ]。
(7)
— 当suffixLength等于0时,suffixLength等于1。
— 当level[ i ]的绝对值大于 ( 3 << ( suffixLength − 1 ) ) ,并且suffixLength小于6时,suffixLength递增1。
— 索引i 递增1。/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zODE4OTk2NA==,size_16,color_FFFFFF,t_70)
比人的总结:
① 如果|level|<8,那么levelSuffixSize为0,也就是没有后缀level_suffix,这些level分别为±1,±2,…,±7,这14个level由level_prefix=0,1,2,…,13表示。(上述步骤2第3条)
② 如果8⩽|level|<16,那么levelSuffixSize为4,也就是后缀共有四个bit,也就是说后缀能表达16个level,由于此时固定了level_prefix=14,因此这种情况能表达的level就是16个,即±8,±9,…,±15。(上述步骤2第1条)
③ 否则,level_prefix⩾15。这种情况下,levelSuffixSize的值为level_prefix-3
可参考https://www.cnblogs.com/TaigaCon/p/5255018.html?share_token=613c1dab-1428-41af-b442-ce6803c31569
/*编码除拖尾系数外的非零系数*/
i_suffix_length = i_total > 10 && i_trailing < 3 ? 1 : 0;//由(1)可得
for( i = i_trailing; i < i_total; i++ )
{
int i_level_code;
/* calculate level code */
/*根据h264官方手册,level_code与level值的关系为:
如果levelCode是偶数,赋( levelCode + 2 ) >> 1给level[ i ],
否则 (levelCode是一个奇数),赋( −levelCode − 1) >> 1给level[ i ]。

*/
/* calculate level code */
if( level[i] < 0 )//level中保存了非零系数的值
{
i_level_code = -2*level[i] - 1;//level正数对应i_level_code的偶数,负数对应i_level_code的奇数
}
else /* if( level[i] > 0 ) */
{
i_level_code = 2 * level[i] - 2;
}
if( i == i_trailing && i_trailing < 3 )
{
i_level_code -=2; /* as level[i] can't be 1 for the first one if i_trailing < 3 */
}
/*当前if语句包含i_suffix_length为任意值及level_prefix<14的情况*/
if( ( i_level_code >> i_suffix_length ) < 14 )//实际上level_prefix = i_level_code >> i_suffix_length,即i_level_code >> i_suffix_length<4
{
bs_write_vlc( s, x264_level_prefix[i_level_code >> i_suffix_length] );//写入level_prefix = i_level_code >> i_suffix_length
if( i_suffix_length > 0 )
{
bs_write( s, i_suffix_length, i_level_code );//写入Level-suffix = LevelCode % (1 << SuffixLength)
}
}
/*当前else if包含level_prefix=14,i_suffix_length=0的情况*/
else if( i_suffix_length == 0 && i_level_code < 30 )//此时,Level-prefix>15, Level-suffix = LevelCode % (1 << SuffixLength);Level-prefix = LevelCode / (1 << SuffixLength)
{
bs_write_vlc( s, x264_level_prefix[14] );//固定level_prefix=14,写入level_prefix
bs_write( s, 4, i_level_code - 14 );//levelSuffixSize=4,与语法部分的条件2对应,写入level_suffix,一共4位,29-14<16,刚好可以用4位表示,
}
/*包含当前else if包含level_prefix=14,i_suffix_length>0的情况*/
else if( i_suffix_length > 0 && ( i_level_code >> i_suffix_length ) == 14 )
{
bs_write_vlc( s, x264_level_prefix[14] );//写入level_prefix
bs_write( s, i_suffix_length, i_level_code );//写入level_suffix,Level-suffix = LevelCode % (1 << SuffixLength)
}
/*其他情况*/
else
{
bs_write_vlc( s, x264_level_prefix[15] );//固定level_prefix=15,与语法条件(2)对应,12位存放最大值为4096,level_code的最大值不会超过该值,像素残差最大值为256,level_code最大为512
i_level_code -= 15 << i_suffix_length;
if( i_suffix_length == 0 )对应条件(3)
{
i_level_code -= 15;
}
if( i_level_code >= ( 1 << 12 ) || i_level_code < 0 )
{
fprintf( stderr, "OVERFLOW levelcode=%d\n", i_level_code );
}
bs_write( s, 12, i_level_code ); /* check overflow ?? */
}
//根据(7)更新i_suffix_length
if( i_suffix_length == 0 )
{
i_suffix_length++;
}
if( abs( level[i] ) > ( 3 << ( i_suffix_length - 1 ) ) && i_suffix_length < 6 )
{
i_suffix_length++;
}
}















 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









