







 本文详细介绍了L0, L1, L2范数在模型规则化中的作用,特别是它们如何影响模型的复杂度和稀疏性。L0范数鼓励模型参数稀疏,但优化困难;L1范数通过Lasso回归实现参数稀疏化,防止过拟合;L2范数通过Ridge回归使参数接近0,降低模型复杂度。L1范数在变量选择上优于L2范数,Lasso回归可通过坐标轴下降法求解。"
138879814,7337247,实时环境监测与CEP技术的应用,"['大数据', '人工智能', '环境监测', 'CEP', 'Python']
本文详细介绍了L0, L1, L2范数在模型规则化中的作用,特别是它们如何影响模型的复杂度和稀疏性。L0范数鼓励模型参数稀疏,但优化困难;L1范数通过Lasso回归实现参数稀疏化,防止过拟合;L2范数通过Ridge回归使参数接近0,降低模型复杂度。L1范数在变量选择上优于L2范数,Lasso回归可通过坐标轴下降法求解。"
138879814,7337247,实时环境监测与CEP技术的应用,"['大数据', '人工智能', '环境监测', 'CEP', 'Python']
范数规则化有两个作用:
1)保证模型尽可能的简单,避免过拟合。
2)约束模型特性,加入一些先验知识,例如稀疏、低秩等。
先讨论几个问题:
1)实现参数的稀疏有什么好处吗?
一个好处是可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据就只能呵呵了。另一个好处是参数变少可以使整个模型获得更好的可解释性。
2)参数值越小代表模型越简单吗?
是的。为什么参数越小,说明模型越简单呢,这是因为越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。
1 L0范数
L0是指向量中非0的元素的个数。如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0。换句话说,让参数W是稀疏的。
但不幸的是,L0范数的最优化问题是一个NP hard问题,而且理论上有证明,L1范数是L0范数的最优凸近似,因此通常使用L1范数来代替。
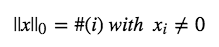
2 L1范数-Lasso回归
L1范数是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









